CSAPP学习记录(已完结)
CSAPP学习记录(已完结)
CSAPP是一门挺有趣的计算机体系课,包含了很多东西,可以泛泛而粗浅地了解整个计算机系统。
下面是无答案的LAB学习记录。
笔记放在了度盘上:CSAPP读书笔记
代码在 GitHub 上, 不建议直接抄:Dog-Du/CSAPP-CMU15213
LAB 1 DATALAB (第二章之后)
2024.10.2-2024.10.3
比起代码,更像是脑筋急转弯或者益智小游戏,比较简单,也没有什么很好说的。。。
LAB 2 BOMBLAB (第三章之后)
2024.10.20-2024.10.21
有一说一,第三章非常像汇编语言和编译原理的简单杂交版,并另附了一些其他知识。
非常有趣的实验,分为六个阶段,在看代码的时候发现了隐藏阶段,但是没看明白怎么进入,所以放弃了隐藏关卡。
主要思路:
1.首先要知道寄存器的作用,函数的控制转移的过程,指针的引用和解引用,GDB的基本使用等等
2.分段看汇编,因为肯定包含了循环,分支,函数调用的部分,把代码分成一段一段看,比如一个循环做了什么给它抽象出来。哪里会引爆炸弹,去看去猜原因是什么。
phase_1:
很简单,就是得到 string_length 和 string_not_equal 两个函数,因为会使用rdi和rsi寄存器传递参数,然后根据地址获取他想要的字符串即可,用ASCII码转换即可。
phase_2:
打断点,先读read_six_numbers函数,看看他是怎么实现的,然后再去看phase_2函数,然后尽量还原出来源代码,因为C语言的代码和汇编语言的代码一一对应关系还是比较好找的。
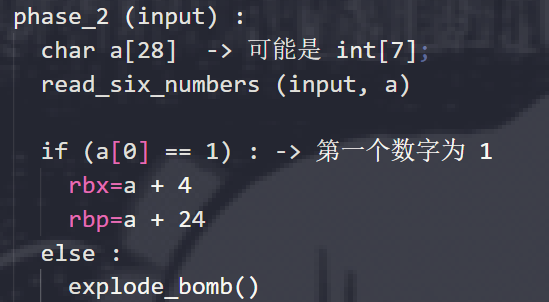
这样会更加方便理解,最后猜到phase_2到底想干什么,就可以比较流畅的得到荅案。
phase_3:
phase_3也是如法炮制,比较简单,唯一需要注意的是 jmp *() 表示间接跳转,然后猜到后面那么多 jmp 的指令到底从何而来之后就能轻松解决。
phase_4:
先看phase_4函数再去看func4函数,phase_4先是读取整数,然后进行一些判断处理,调用了func4,如果func4返回的结果和预期不符则爆炸,最后是一个检查,检查不过则爆炸。
再看func4,可以看到用rdx,rsi,rdi传递了三个整数,之后进行了一些运算,然后在func4中又调用了func4,是递归,这里我们只需要关注递归的退出条件即可,就可以轻松解决。
phase_5:
注:汇编中 mov %fs:0x28,%rax 的作用: 栈保护功能,将一个特殊值(fs:0x28)存在栈的底部, 函数运行结束后再取出这个值和fs:0x28做比较,如果有改变就说明栈被破坏,调用__stack_chk_fail@plt。fs寄存器的值本身指向当前线程结构
这个题目最重要的是要看懂 AND edx, 15 的作用是什么即可。
phase_6:
这六个题目中最难的一个,在还原的C语言代码中,包含了两层循环,多个循环过程,一大堆跳转看得人头晕眼花,但是还是只要进行分段,把代码分成一段一段看懂某一段是干什么用的,进行抽象即可。但是这里可能需要一点想象力,猜测作用是什么。
lab2总结:
总的来说,比起难,更是有趣,需要一点想象力和代码结合,然后进行猜测。隐藏阶段没有写~
LAB 3 ATTACK LAB(第三章之后)
2025.2.2-2025.2.3
之所以隔了好几个月才写lab3,是因为2024.10.21之后就去参加oceanbase赛和天池杯了,之后2024.12.23比赛结束之后,又磨磨唧唧搞期末考试,2025.1.16放了假。该过年了,玩了几天,初四提前回家,初五2025.2.2开始才写lab3。
lab3也是一个比较有趣的实验,根据汇编语言,输入字符串,利用缓存区溢出进行ROP和缓冲区溢出hack。
需要注意的点:
1.关于栈的指针
返回栈指针在当前栈底的上面。
因为栈是从上向下拓展,并且栈底在最上面。
比如:当前函数帧是 [1000'000, 1000'010]。则返回栈指针为 [1000'011, 1000'018]
在当前函数帧最高位的上面,小端读取,所以反写。
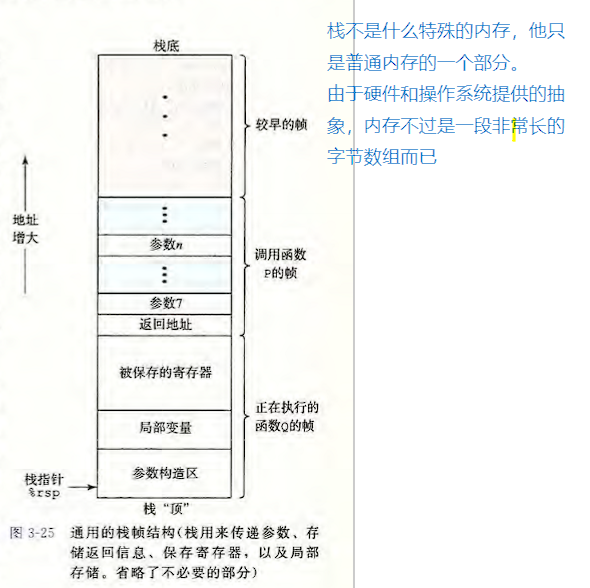
在这个图中,栈是倒过来的,栈底是最大的,栈顶是最小的。
2.关于caller save调用者保存, callee save被调用者保存 (x86-64 Linux Register Usage)
书上说:
所有其它的寄存器,除了栈指针%rsp,都分类为调用者保存(caller save)寄存器。
%rbx,%r12,%r13,%r14是被调用者保存(callee save)
%rsp是一个特殊的被调用者保存(callee save), 被保存到原值用于退出函数
%rbp是被调用者保存,被调用者必须保存并存储,也许会被用作函数帧指针,可以混用和比较。
3.x86-64, 64位,所以8字节,地址也是64位,指令也是64位。
4.pushq, popq,会将数据压入栈
call是先把pushq rsp,再jump。
ret 是先popq rsp,再jump。
所以,只要利用这一点就可以进行jump。
5.rtarget没有金丝雀
6.rtarget 栈随机化,但是可执行代码部分没有随机化。
也就是可执行代码的地址是固定的,只是执行期间的栈是随机的
7.rtarget 没有栈越界检测,不然没法写
8.ctarget没有任何保护
ctarget-level1:
只需要简单的利用缓冲区溢出覆盖掉栈帧顶内存所存的栈指针即可。
在GDB中利用 disassemble <函数名> 指令可以很容易的得到函数的地址,得到touch1函数的地址之后,覆写上即可,注意需要倒写。
ctarget-level2:
开始需要注入代码。
注入代码的原理:先将代码注入缓冲区,之后利用函数返回时的ret指令并通过覆盖栈指针的方式,让机器跳转,并去执行我们所希望的指令的地址。
需要注意的是,ret指令在add $…, rsp之后,也就是说,栈空间已经被回收,之后在执行函数的时候这部分栈空间很可能被占用,所以不能用来存取变量。
注入代码的步骤:
1.首先获取缓冲区的地址。
2.写出注入的代码的汇编语言,利用gcc -c 和 objdump -d得到机器指令。(因为不使用jump,为了实现函数跳转,可以参考上面的第四点)
3.将得到的机器指令写在缓冲区的头部(不在头部也行,只要保证有足够空间容纳机器指令并且明确好机器指令的地址即可)
4.用缓冲区的地址覆盖掉栈指针
之后只需要参考touch2函数,然后把cookie存入%rdi即可。
ctarget-level3:
同样是注入代码。有两种方法。
方法一:
hex2match中,random函数为伪随机,每次运行得到的随机数一样。
hex2match用于判断给出的字符串是否和想要的字符串一样。
那么,只需要让给出的字符串的地址和想要的字符串的地址一致即可,也就是让同一个字符串进行比较。
这样就基本和ctarget-level2基本一样,只是把参数换成了地址而已。只需要先gdb跟踪,得到在比较的时候给出的cookie的字符串的地址,然后作为函数参数传递即可。
PS:这样的做法不太符合CSAPP希望做的方法。
方法二:
考虑怎么传递一个字符串,我们需要把字符串在代码注入的时候就写入内存,然后把这个地址传递给hex2match,同时保证内存不被破坏。
把字符串在注入时就写入内存不难,得到字符串的地址也不难,难点在怎么保证内存不被破坏。
考虑把字符串存在某个位置,比如:全局变量,或者栈空间。
考虑全局变量,查看汇编语言,很容易发现vlevel是一个全局变量,同时我们也知道cookie也是一个全局变量,我们可以考虑把字符串存放在这个地方。但是我没有做到,原因是空间无法使用,他会提醒我不可达内存。
考虑栈空间,从getbuf的栈空间考虑,栈是从上向下拓展的。而在hex2match以及random中,会开辟并使用到很多栈空间,也就是栈会向下拓展,并被使用到,而getbuf在ret之前会回收栈空间,因此存放在getbuf的栈空间及其下方,不合适。考虑存放在getbuf上方,查看汇编语言,发现test函数有一片栈空间,可以把字符串存放在test函数的栈空间中,具体方法为,getbuf函数的栈空间上方的栈指针的上方。
这时我们考虑好了字符串存放位置,注意要倒写,可以思考一下为什么需要倒写。
最后把字符串放在对应位置,然后把这个字符串的地址当做函数参数传递即可。
rtarget-level4
这是我唯一一个一次过的,前面几个都抠抠索索反复看了好几遍书花了好几个小时才搞明白怎么弄,只有这个弄得比较快。
rtarget开启了限制可执行区域和栈随机化,但没有开启栈破坏检测,也就是我们仍然可以覆盖栈指针,让程序跳转到我们希望的地方,这得以让rtarget可以破解。
方法依旧是通过缓冲区溢出,控制ret时的转移方向,但是注意,由于限制了可执行区域,也就是栈空间的字节不会被执行。因此不能进行注入,而是利用叫ROP的方法。
思路分析:
因为注入不了代码,所以缓冲区的部分实际上压根就没有意义,也就是这40字节不管是什么都无所谓。需要考虑的是这40字节之后的。回想ctarget-level2所注入的汇编代码,所做的事情为把%rdi赋值为cookie,在这里也是一样。只是因为无法注入代码,因此写的别扭一些。
利用movq, popq, 以及栈空间,栈指针的之间的配合实现一样的事情。至于怎么存放cookie,可以考虑放在栈空间中,然后利用上面 “需要注意的点” 中的第四点,实现赋值。最后将值传递给%rdi,再跳转到touch2。
然后盯着3A表和3B表中movq, popq这两个机器指令,去一个一个找farm.c中的函数的后几位对应的字节。拼凑出指令。
最后写出字节码即可。
lab3总结:
attacklab比bomblab更进一步,bomb只需要读懂汇编语言即可,而attack需要深入理解栈,函数调用以及中间内存分配的过程,同时运行在64位的平台,也是很贴近实际的实验。虽然以后不会做hacker,但是也能深刻的理解计算机运行的过程。最后,rtarget-level5没有写~
LAB 4 BUFBOMB LAB(第三章之后)
2025.2.4-2025.2.4
这个LAB4 BUFBOMB LAB基本和LAB3 ATTACK LAB一致,只有level3和level4略微超出LAB3范围。还有就是LAB4使用的是x86-32,LAB3使用的是x86-64,这导致汇编语言有些许不同,以及其他方面在标准上不同。
需要注意的点:
1.关于函数传递
bufbomb lab是x86-32,而不是x86-64,与attack lab不同
x86-32参数传递的方法是倒序压入栈
x86-64参数传递的方式是使用%rdi等寄存器,不够用了再用栈
2.关于返回栈指针在内存地址的存放位置。
x86-64是直接放在栈帧之上。
x86-32存在一个保存原来%ebp的操作
因此栈帧再加4字节(因为x86-32是32为地址,所以加4字节)
所以返回栈指针在内存地址的存放位置为栈帧+4字节之上
3.关于push
因为是x86-32系统,push不可能一次性压入8个字节
因此可以考虑把八位立即数分成高低各4个字节,分两次压入栈中,或者进行字节对齐
这样就可以在使用的时候使用 mov 0x8(%ebp), %eax 的形式直接把立即数送给 eax
4.关于在不修复时为什么段错误
在进行level3的时候,要求修复栈,而且要求在完成getbuf返回时,local值不变。
必须要知道的是,只修改栈底的返回栈指针并不会破坏local值。
这点可以通过尝试得知,可以先注入代码,不做特别的事情,只是返回getbuf函数下方。
记住调用getbuf前的%esp, %ebp,然后gdb的x指令查看local值所在内存
可以发现,local值没有发生变化
那么为什么会在之后出现段错误,其实是因为esp和ebp被破坏导致的
在gdb下使用info frame 1,可以看到返回了错误的信息,这是导致段错误的原因。
5.关于%esp和%ebp之间的关系
x86-32中,在一个栈空间中,完成栈空间的拓展之后,leave之前,存在如下关系:
%ebp = %esp + 拓展的栈空间
6.关于项目的一个说明
buflab32.pdf的level4说:
从一次运行到另一次运行,尤其是不同用户之间,给定过程使用的精确栈位置会有所不同。
这种差异的一个原因是,当程序开始执行时,所有环境变量的值都放置在栈的底部附近。
环境变量作为字符串存储,根据其值需要不同的存储量。因此,为给定用户分配的栈空间取决于其环境变量的设 置。
其实就是传入的参数 -u <用户名> 中用户名字符串长度不同导致的
C语言的main函数声明为 int main(int argc, char *args[])
这和 char *args[] 有一定关系
level 0 & level 1 :
level0与level1几乎和LAB3的ctarget-level1和ctarget-level2一模一样,除了一个是x86-32一个是x86-64,但是需要注意的点已经在上面标注了。
但是CSAPP所希望的level1的解法可能不是代码注入,通过覆盖栈底内存,保证跳转之后pop出来的内容正好是cookie,这是因为x86-32使用的是push和pop来访问参数的,所以可以这么做。这样的方法更加简单。
PS:有一个坑是buflab32.pdf中说缓冲区大小是32字节,但是实际上应该以汇编语言的为准。。。。
level 2 :
这个就和ctarget-level2更像,需要注入代码,但是他希望修改global_value的值,让他等于cookie,同时bang函数的参数根本没有用到。
1 | int global_value = 0; |
所以我们不需要管这个参数的问题,只需要在注入的代码修改global_value即可,方法很简单,先gdb通过info variables找到global_value的地址,然后修改这个地址,修改为cookie,之后再跳转到bang函数即可。
level 3 :
level3有一些超出ctarget的范围了,要求我们复原栈空间其实上面注意的点中第四条其实说了,local值不会因为返回栈底指针那部分内存被破坏而被破坏,只要记录好ebp,esp的值,然后把返回地址记录好就可以完美还原栈空间的状态,就像是正常的调用了getbuf一样。之后就是把getbuf的返回值也就是%eax修改为cookie即可。
至于为什么只需要修复ebp,esp寄存器的值就可以完成栈的复原,其实也跟函数的调用过程有关,在x86-32中,ebp会记录返回位置,esp则在栈。可以看一眼书这里。
在level3这里我走了一个弯路,我以为在破坏getbuf函数的栈底的时候local值也会被破坏,然后想着在注入的代码中call一次uniqueval函数,但是一直不成功,后来才想起来,栈底的返回地址是通过金丝雀来保护的,而不是像local这种保护方式。
level4:
level4其实差不多和level3一样,但是更进一步,同时有一个和level0一样的坑。
方法其实还是注入代码还原现场,然后把%eax改为cookie,最后返回testn中getbufn之后的位置。
但是存在栈的随机,好在变动幅度在buflab32.pdf中给出了,是+-240字节,所以只需要480字节的nop雪橇,就可以让注入的代码总是顺利执行。
不过有两个问题:
一是怎么还原现场,因为存在随机,esp和ebp的值不固定。
二是雪橇应该从哪里开始滑
对于问题一上面需要注意的点第五条已经差不多指出了,因为我们需要把现场还原成testn调用getbufn之后的样子,也就是testn函数本来的样子。所以只需要去研究testn函数中esp和ebp之间的关系即可,最后发现,esp和ebp的关系后。分析怎么写,因为在getbufn结尾的ret之前有一个leave,leave会pop %ebp,所以ebp的值会被污染,而esp的值不为所动,所以只需要用esp的值推导出ebp的值即可。
对于问题二,由于不清楚这个栈的变动范围,预期读代码去判定到底是怎么个变动范围,不如直接尝试。先gdb去查看第一个测试样例中 getbufn 中缓冲区的位置,然后设置雪橇;之后通过第一个测试样例之后,再去查看第二个测试样例缓冲区的位置,依次类推。最后根据五个样例所推导出雪橇即可。
lab4总结:
总的来说,LAB4 BUFBOMB LAB和ATTACK LAB差不多,都是根据缓冲区漏洞去输入特定的字符串。只不过一个是x86-32,一个是x86-64,写完lab3之后写lab4很快,一天就写完了。这可能也是CSAPP的教学目的,让学生既熟悉x86-64也了解x86-32。
LAB 5 & LAB 6 Architecture Lab 放弃(第四章之后)
因为一些个人原因,我放弃了 Architecture Lab 。
其实是我实在是不想写汇编,读汇编姑且可以,但是真的不想写汇编了。正好 2015 年 cmu15213 没这章课程。
如果以后有机会的话,会回来补坑。
LAB 7 CACHE LAB(第六章之后)
2025.2.6-2025.2.8
PART A:
PART A其实还是很简单的,只需要照猫画虎写出一个 lru 算法即可。而且不考虑越界的情况,因此比较简单。
需要注意的是地址的结构: 六十四位地址, 2^s组,每组 E 块,每块 2^b 字节。
所以地址构成为:Tag(64 - s -b 位) | Index(s 位) | Offset(b 位)
至于为什么这么设置,其实更多可以在第四章或者计算机组成原理中找到答案。
hit 则是,通过中间的 Index 的 s 位,也就是 (address >> b) & ((1 << s) -1) 获得组号,然后在组内先检查Tag,如果有某一块 Tag 相等,则 hit。
这是因为 cache.pdf 中指明了,不会出现块越界的情况。比如:块为[0x0001000, 0x0001111],有一个访问为 0x0001110 开始的 2 个字节,那么就需要读取 [0x0001110, 0x001000] 这两个字节,就出现了越块的情况。
需要注意的是,给出地址虽然没有前缀的 0x , 但是是 16 进制的。
在 PART A 写 lru 的时候,我想到了我在复习计算机组成原理的时候看的课程中另类的适合于较小数据量的写法,但是后来发现,不行,原因在于可能同时存在两个及以上可以驱逐的块。但是通过队列实现的有且仅有一个块应该被驱逐。所以后来没有采用。
别忘了指令需要跳过,以及 LOAD 和 STORE 其实是一样的都相当于访问一次内存块,对于 lru 算法来说没有区别。
我建议在写 PART A 的时候实现 -v 选项,方便调试和发现错误。
PART B:
PART B 比较难了。有一说一,我第一时间没想到要分块来着,后来参考了别人的思路才想到的。
为什么分块可以减少miss?
1 | for (i = 0; i < N; i++) { |
上面代码是原版代码。
miss的主要原因在于 B, 因为 A 是按行读,其读取是连续的,符合 cache 的工作原理。
但是 B 是按列写,其地址不连续,会频繁的导致缓冲需要重新读取内存,频繁地 evict 导致miss。
那么分块之后呢?
miss主要原因在 B 按列写,导致每次写的时候只写了一个地址,缓冲块内其他内存废弃了。
比如:写 [0x000102, 0x000105],那么缓冲很可能会读入 [0x000100, 0x000111] ,也就是 [0x000100, 0x000101] 和 [0x000106, 0x000111] 这部分都没有用到,而且读取的列越多,之前读取的内存就越可能被驱逐,导致下次用到的时候反而不在缓冲中,而且miss。
分块的意义就在于利用好这原本会被废弃的内存。
例如: 8 * 8 分块,因为会直接利用这 8 * 8 的区域,利用好了缓冲会一次性读取一片内存,并且充分利用这部分内存。之后再也不需要这片内存,就减少了miss。
对于 32 * 32
首先,cache的参数为 s=5 E=1 b=5,一块可以存8个int,一共有32块,最多256个int。每次读入int会一次性填满整个块,也就是每次都会一次性读入8个int。
对于一个地址 Tag(64 - 5 -5) | Index(5) | Offset(5),让我们考虑什么时候一块会被驱逐:
首先Index会相等,其次根据PART A所说,Tag不相等。至于Offset,它与匹配无关。
也就是Index相等,而Tag不等,会导致一块被驱逐。显然,那就是每过 2 ^ 10 字节,就会导致一块被驱逐。
那么对于 32 * 32 每行 32 个int,128字节, 2 ^ 10 / 128 = 8,所以当访问 A[8][0] 的时候, A[0][0] 会被驱逐,反之一样。因为他们的低 10 位相等,而Tag位不等。
考虑到分块方法,既然每次都会读入8个int又考虑到 A[8][0] 和 A[0][0] 不能同时出现,那么自然会想到 8 * 8 分块。
循环中每次利用8个临时变量按行一次性读取 8 个A数组的数字,然后写入对应的 B 数组中 ,然后重复 8 次。
考虑怎么写入 B 数组,既然 A 数组有按行读,那么 B 数组能否按行写?
答案是可以的。
我们先把每一行 8 个的 A 数组直接先按行写入 B 数组中,然后在 8 * 8 写入 B 数组之后,对 B 进行转置即可。
为什么可以直接转置? 因为这个时候 B 数组的这 8 * 8 位全部都在缓冲中。
对于 64 * 64
可以参考:CSAPP - Cache Lab的更(最)优秀的解法 - 知乎
我的解法说是在这篇文章中抄来的也不为过。
首先,直接把 32 * 32 的代码放上去会有很高的miss。
分析:
cache 是 32 组, 每组一块, 一块内 32 字节
地址组成: Tag(64 - 5 - 5) | Index(5位) | Offset(5位)
所以对于 A[4][0] 和 A[0][0], 因为一行为 64 个int,共 256 字节。
256 * 4 = 1024 字节,这个时候 正好 A[4][0] 和 A[0][0] 的地址的低 10 位相同。
所以会发生分到同一组的情况,并且导致 A[0][0] 被驱逐。因此 miss 率超高。
一次最多处理 4 行,考虑 4 * 8, 也不行,因为这样解决不了写入 B 的时候同样情况。
必须以 4 * 4 为单位进行处理,可是这样会导致每一行同时读入的 8 个 int 中后面会有 4 个int 用不到。
下次再使用的时候会导致重新读入。
-------
| A| B|
-------
| C| D|
-------
上面 ABCD 四个区域均为 4 * 4,用 AA 表示 A 的左上,BC表示 B 的左下,由此类推。
先复制, AA -> BA, AB -> BB, 注意这个地方复制的时候,利用 32 * 32 的临时变量一次读取会更优。
转置, 转置 BA, 转置 BB
再复制, AC -> BC, AD -> BD
转置, 转置 BC, 转置 BD
这个时候 BA, BD 已经完成,不需要管。
只需要按行交换 BC 即可。
需要注意的是,按行交换 BC 的时候注意方法。具体可以看上面的知乎文章。
对于 61 * 67
其实 61 * 67 才是我第一个通过的一个测试点。因为最开始的时候我希望一份代码过三个测试。但是后来发现不太行,在这期间发现61 * 67很容易通过。
只需要分块大小为 16 即可。
这个简单,就不遮遮掩掩了:
1 | for (i = 0; i < N; i += 16) { |
但是这样成绩不优,如果想要更好的成绩可以这样考虑:
1024 / 67 / 4 = 3.82 向下取整为 3
可以考虑使用 6 * 6 分块,同时运用 64 * 64 的方法。
而且 61 - 7 = 54, 67 - 7 = 60. 都可被 6 整除,对最后一部分运用 7 * 7 即可
总结:
最后成绩:
1 | Cache Lab summary: |
哎呀,这个 LAB 真是头大,优化之优化,只能说写到最后头疼,不得已第一次看了别人分享的思路题解。
LAB 8 Perference LAB(第六章之后)
LAB 8可以说是LAB 7 的全面劣化版了,首先评分没有确定的标准,没有满分线,性能测试却没有进行环境隔离排除环境因素,甚至每次测试的结果都不一样,而且测试出来的结果依赖于机器。如果时间比较紧的话,这个 LAB 完全可以跳过,认真完成 LAB 7 CACHE LAB即可。
2025.2.9-2025.2.11
首先回顾基本的优化方法:
1.循环展开
2.减少内存引用
3.减少循环低效率
4.提高机器级并行度
因为 Perf LAB 没有像 CACHE LAB 限制临时变量和数组等条件,为了提高代码的通用性和锻炼自己,我将在 Perf LAB 中遵守 CACHE LAB 所提出的 code rule。
ROTATE :
1 | char naive_rotate_descr[] = "naive_rotate: Naive baseline implementation"; |
看到这个naive_rotate很难不让人想起 CACHE LAB 的 PART B 优化 Transpose 函数,不说是一模一样,也可以说是长得很像。很容易想到进行分块即可。
那么分块,8 * 8, 16 * 16, 32 * 32。 在我的电脑上最佳的是 16 * 16。
之后我尝试把 CACHE LAB 的其他优化点也加入,发现没啥用,提升的速度还没有误差来的大。于是放弃。
SMOOTH :
1 | static pixel avg(int dim, int i, int j, pixel *src) |
分析:
1.大量函数调用开销 -> 只需要把函数调用换成宏即可。
2.大量重复计算导致的高计算开销。 -> 需要换成更优的算法。
重复计算在哪?
比如计算 dst[1][1],需要计算 src[0][0] -> src[2][0] src[0][1] - > src[2][1] src[0][2] - > src[2][2] 九个点。
接着计算 dst[1][2],需要计算 src[0][1] -> src[2][1] src[0][2] - > src[2][2] src[0][3] - > src[2][3] 九个点。
很容易发现,这中间有六个点重复。
记 a = src[0][0] -> src[2][0], b = src[0][1] - > src[2][1], c = src[0][2] - > src[2][2], d = a + b;
那么计算 dst[1][2] 的时候只需要计算 e = src[0][3] - > src[2][3] 然后 e + d 即是dst[1][2]答案。
接着,令 d = e + b 即可,a,c只需要在计算边界的时候需要,之后循环中,只需要 d,e,b即可。
这么做之后,计算一个点只需要 src[i +1][j - 1] - > src[i +1][j + 1] 两次加法,加上 e + d 一次加法和 d = e + b 一次赋值。
大大减少了计算量。
注意处理好边界条件即可。
另一种方法:
可以考虑前缀和,那么一个点就是 sum[i + 1][j + 1] - sum[i - 2][j + 1] - sum[i + 1][j - 2] + sum[i - 2][j - 2]。
但是这么做其实并不会快多少,因为每次的计算量没少太多。而且考虑到尽量减少数组的设立,利用分块 + 前缀和的方法的话,边界条件处理很麻烦,而且也不通用,最后我没有实现,
总结:
perf lab是很简单的一个实验,因为没有一个具体的评分标准,其含金量不如 CACHE lab。而且因为误差导致的波动比优化带来的提升大的多。
我的最终结果:
1 | Teamname: DogDu |
LAB 9 Shell LAB (第八章之后)
2025.3.4-2025.3.5
这个shell lab很怪,更像是一个函数应用实现,因为基本上完整的框架已经给了。想好思路,把函数怎么用怎么用给记住,然后用就好了。主要思考的就是信号与中断而已,而且测试量非常小。只要把第八章给记好了基本上没啥问题。
主要需要记住waitpid函数用法,还有记得信号阻塞和中断的中断。
先按照shlab.pdf所说,把提示点和注意事项完成了。

一个坑:
在bg和fg中,文档的描述和实际实现不符。

文档中说restart,但是实际上tshref参考答案没有restart,于是最后我也没有restart。
之后只需要明确每个函数需要做什么即可:
eval函数:执行命令
- 把任务加入数组
- 阻塞sigchld信号
- 如果前台则调用waitfg
- 如果后台则打印,并退出
builtin_cmd函数:处理内建命令并移交控制权
- quit -> exit(0);
- & -> return 1;
- jobs -> listjobs();
- fg || bg -> do_fgbg();
do_bgfg函数: 负责重启job以及转交控制权。
-
检查%jobid或者pid是否存在以及合理。
-
如果job状态为ST,则发送信号重启。
-
设置job状态,BG则退出,FG则调用waitfg。
waitfg函数:阻塞并对前台程序进行完全处理。
- 需要明确前台程序可能会发生什么:
正常结束,终端输入ctrl+c或ctrl+z,子进程本身出现某种中断。
- 如何处理:
正常结束 -> sigchld_handler处理,判断出正常结束,打印状态。
终端输入ctrl+c或ctrl+z -> sigint_handler/sigtstp_handler处理之后,判断出是终端输入,打印状态。
子进程本身出现某种中断 -> sigchld_handler处理之后,判断出是子进程出现某种中断,处理。
- 难点在于区分和判断状态:
正常结束,应该由sigchld_handler处理,waitfg发现pid已不在数组中可以不做处理。
终端输入ctrl+c或ctrl+z,经过sigint_handler/sigtsp_handler处理,给子进程发送信号,可以通过标记特殊状态让waitfg识别出,但是需要注意sigchld_handler可能会因发送的信号而触发,为了防止处理复杂,可以选择block掉它。待waitfg处理之后由waitfg重新打开。
子进程本身出现某种中断 -> sigchld_handler不应过多干扰,这样waitfg可以根据根据前两种排除判断出这种情况,之后进行对应处理即可。
- sigint_handler/sigtstp_handler:处理int/stop信号
具体操作应该结合waitfg函数,避免当子进程发生状态变化而waitfg而无法得知导致无限循环。
- sigchld_handler:当子进程状态发生某种变化之后进行处理
因为同时要回收后台的子进程,因此必须要用while循环回收,因此难点在于和waitfg函数的配合,避免因为sigchld_handler已经回收了,导致waitfg不知道子进程的状态变化。
- 其他函数:
没进行更改。
总结:
其实shell lab不难,注意和处理好细节即可。
LAB 10 Malloc LAB (第九章之后)
2025.3.6-2025.3.7
malloc lab这个实验主要难点在于怎么设计自己的malloc,难的在于把malloc工作的具体细节,先怎么做后怎么做想清楚思路,malloc lab的思路比写代码更重要,想好整体框架之后,细节代码到挺简单,调试即可。
整体思路 :
我的想法是写一个遵循最佳匹配的分离适配显式空闲链表。
首先需要明确的是,这个lab是在 -m32 下编译并运行的。所以一个指针大小为 4byte。
块
既然是显式链表,就需要在空闲块中存储两个指针指针,再加上一个头部一个脚部。
总计 4 * 2 + 4 + 4 = 16 字节,是 8 的倍数。但去掉脚部和两个指针之后,空闲块的可用部分为 12 字节,不是 8 的倍数,不方便 8 字节对齐,怎么办?
- 方法一:不使用脚部,也就是脚部的四个字节永远不用。 有点浪费空间
- 方法二:讲究着用。我使用的。
- 方法三:填充字节,扩大最小可用块。做不到,因为头部是 4 个字节,只要把头部也放入空闲块内,就永远不可能同时做到整个空闲块大小和可用部分大小均为 8 字节对齐。除非把头部置为 8 字节的 int,但是这样和方法一一样,都有些浪费空间。
方法二可行的原因在于,虽然可用部分不是 8 字节对齐的,但是整个块的大小是 8 字节对齐的。所以只需要在最开始 mm_init 时调整好堆头尾的两个特殊块的位置即可。
定义:空闲块的大小 free_size 为可用部分的大小,整个块 block_size 的大小则加上头部,也即 block_size == free_size + HEAD_SIZE (也就是 4 byte)。
头尾部,均为32bit,前30bit用来存储free_size,后面两个bit一个表示该块是否空闲,一个表示前面的块是否空闲,也就是书上所说的优化方法。
之所以留下两个bit的空间,是因为根据定义,free_size 应该是4字节对齐,而非8字节对齐。
堆头和堆尾和书上基本一致,只要能让堆头的后面 8 字节对齐和堆尾的后面 8 字节对齐即可。
链表
链表的头节点用一个放在全局的静态指针数组表示。
定义一个 mm_start_brk 指向堆头最开始的那个头部, mm_brk 指向堆尾最后的那个头部。
链表为双向链表,但并非循环链表(其实也可以是循环链表)
块管理
一个大小为 free_size 的空闲块,其最小为 12 byte, 并且为 4 byte 的倍数。
分大小类:seg_list[i] 存放 2^(i - 1) ~ (2^i) - 1 的 free_size 的空闲块。
流程
mm_malloc (size):
1. 规整size
2. 遍历链表得到头指针,同时遍历空闲块
3. 如果不存在这样的空闲块则拓展堆
4. 如果有这样的空闲块,则从链表中移除,同时设置空闲信息
mm_free(ptr):
- ptr -= HEAD_SIZE 得到首部指针
- 向前合并空闲块
- 向后合并空闲块
- 设置空闲信息和大小信息
- 插入链表中
合并
合并采取立刻合并也就是在发现可以合并的时候立刻合并。
建议
-
建议先完成最基本的功能,之后再慢慢添加功能。
-
把函数的参数都作为指向空闲块的首部,这样便于宏和函数的编写。
-
初始化时,把堆初始化为0,也就是每次初始化之后的第一次申请空间总需要拓展堆。
-
多设置一些宏,方便使用。
-
遇到段错误的时候,使用gdb调试。
注意
-
只有当首部的 bit 显示前方的块空闲,才能够去访问前方的块。
-
一定要注意mm_init的对齐。
-
每次调用mm_init都应该让状态恢复至初始,我们不应该调用 mem_init 函数。
-
假如 brk 为堆开始的指针,那么对齐只需要让 brk += (8 - brk % 8) % 8 即可。
-
给定需要大小 size 应该进行规整。
-
因为所有宏和函数的参数均为指向头部的指针,所以 seg_list 也应该遵循这样的规则。
优化
优化集中在对空间的优化,因为速度基本上是满分。
分裂
分裂采取在仅在 malloc 时发现 free_size - size - HEAD_SIZE >= MIN_FREE_BLOCK_SIZE 的时候才进行分裂,同时分裂采取仅分裂两块的最大分裂。
合并
合并可以发生在 mm_realloc、mm_free和extend_heap扩展堆大小时。
mm_free 好理解。
mm_realloc 的点在于,重新分配的块如果前后物理相邻的块是空闲的那么直接直接拓展,如果符合所给大小,则可以直接返回。
extend_heap 的点在于,虽然没找到合适大小的空闲块,但是堆尾的最后一个块可能是空闲块,可以利用这个空闲块。这样可以减少拓展的空间。
堆收缩
如果堆尾最后的一个块为空闲,那么可以收缩堆,来提高空间利用率。
但是查看 mem_sbrk 的实现发现,参数 inrc 不能为负数。
于是考虑:先重置 mem_reset 再恢复。 如下。
1 | static void shark_heap() { |
但是这样好像会出问题:
1 | Results for mm malloc: |
看来评测认为堆应该是单调不减的。
哈哈哈哈。
这可能是全网最高评分了吧
成绩
1 | Results for mm malloc: |
整体成绩为 93 分,还不错。
关于为什么吞吐量很容易就拿满分,我觉得这和libc中的malloc函数是线程安全的有关,这可能会付出不少代价。比起这个我更好奇libc中的空间利用率是多少。
总结:
malloc lab比起代码难,不如说是构建一个整体的框架和思路比较难。然后顺便体验一下无类型编程是什么感觉。不过这个我以前写数据库比赛的时候,写缓冲池、磁盘和元组管理这块已经有了不少心得。感觉整体还算可以。
LAB 11 Proxy LAB (第十二章之后)
Proxy LAB 这个实验可以说是很水了。测试量不大,整体代码也比较简单,并发的困难和不确定性感觉完全没有体现出来。只需要一天左右时间就能完成。虽然有一部分原因是因为我写的很糙就是了~
2025.3.7-2025.3.8
做好需求分析即可。代理介于客户端和服务器之间,对于客户端来说代理就是服务器,对于服务器来说代理就是客户端。所以代理就是接受客户端的请求,转发给服务器,再讲服务器的相应返回给客户端。更需要注意的是 http 的请求格式该怎么写。
这个 lab 所分的part1,part2,part3分的真的很好,有一种循序渐进的感觉。
PART1
写一个顺序的代理,重点和难点在于解析 http 请求。由于csapp.c中已经分装了listenfd等函数,对socket的操作是很简单的。
http 请求大概的格式可以上网查一查,感觉翻阅一下还挺有好处的。
根据客户端发来的请求,进行拼接,添加上 HOST 字段,然后再发送给服务器即可。
接受时,对于服务器的响应直接写给客户端即可,不需要进行处理。
PART2
写一个并发的代理,需要改动的地方比较少。我使用的是书中的预线程化 + 缓冲队列的方法完成生产消费模式的。
把预线程化的各个线程当做消费者,主线程作为生产者。缓冲队列也就是书中的 PV 操作完成阻塞唤醒的机制。
线程的函数也就是一个无限循环,不断调用part1中的处理函数即可。
PART3
要求写一个缓冲,也不难,可以把缓冲池给模块化出来。但是缓冲池本身不进行socket操作,仅进行缓冲。当且仅当,缓冲池找到对应标记的 URI 的时候,才直接返回对象。
关于怎么返回对象,我选择的是,参数中传递一个指针,进行复制。当然,这样不是最优解。比如,可以返回指向缓冲页的指针,但是这样交互是比较麻烦的,可能需要向外面暴露缓冲池的细节。
关于怎么存储对象,我选择直接把缓冲页开成 MAX_OBJECT_SIZE ,这也是很垃圾的解法。更优解应该是,把缓冲页调成比较小于 MAX_OBJECT_SIZE 的某个合适值,不然空间浪费非常大。然后再在页面中进行标记,把存储同一个对象的若干页面穿成一个链表,进行 lru 时,一起驱逐或者修改即可。毕竟这不是在进行硬件的设计,所以这么做倒也不是很难。
不过得益于这样的缓冲池,让缓冲池页面非常少,可以实施简单的计数方法实现 lru 的方法,而非传统的双向链表 + 哈希的方法。
总结:
Proxy LAB作为最后一个实验,也是一个相对简单的实验,只需要能使用 csapp 所提供的封装函数、理解场景和对并发编程有简单的了解即可完成。
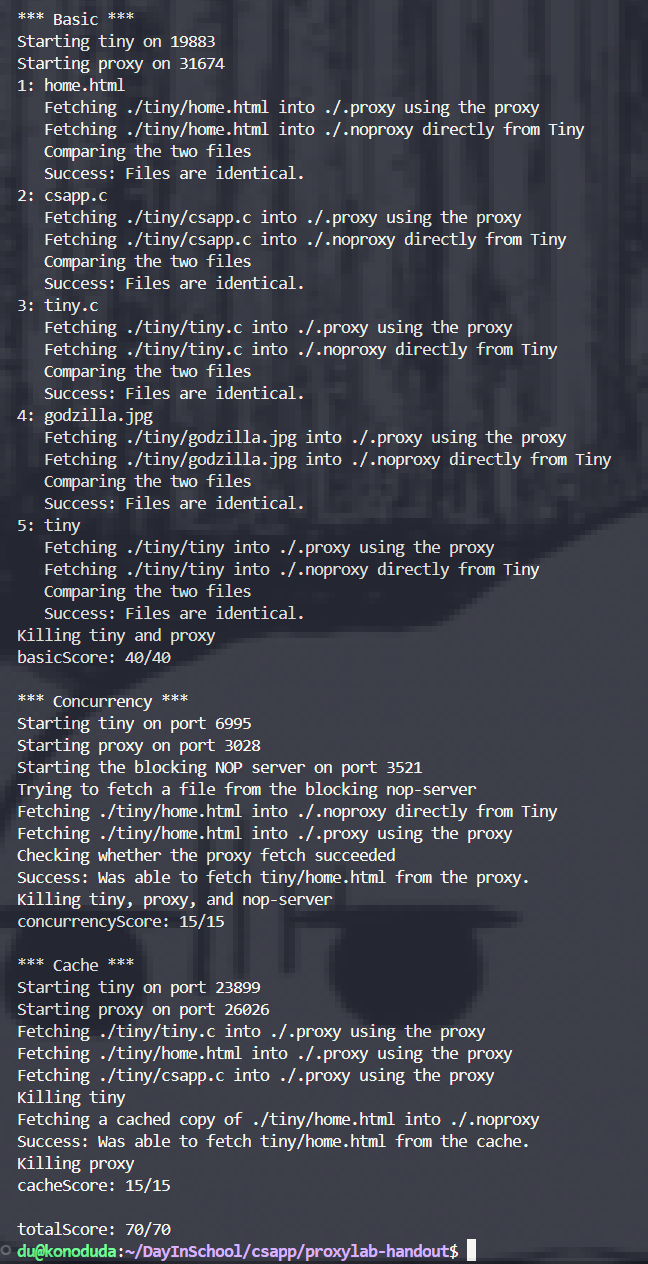
总结
CSAPP 的 LAB 感觉最难的应该是 LAB 7 CACHE LAB,这个优化上确实非常难搞。其他的实验基本上都是最多两三天就能完成的,但是双拳难敌四手,架不住这 LAB 多啊,前前后后也是不少时间。还把书给看完了。
不过整体上 CSAPP 更倾向于概论层次,计算机的各个方面都泛泛而谈,对计算机有一个比较整体的认识。
非常适合大一学完C语言之后来学这门课,对于现在大三的我来说,感觉刺激少了点,书中大部分内容都是课堂上学过的,LAB 也是相互独立,没有一个系统的概念。更多的是巩固了我使用GDB (不是)。
不得不说 Markdown 是真挺方便的,再加上 github 提供的网站,这博客永真真挺方便的。
从去年的九月份末开始,中间因为各种事情耽误,现在可算是完成了。前一段时间面试被疯狂拷打,看动漫也被喂史。现在又要开始学OS、计网和背八股准备暑期实习,又要开始忙了。
