TinyKV:构建一个基于 Raft、分布式事务支持的、水平可扩展的键值存储服务
前言
Tinykv 课程是 PingCAP 推出的教学项目。具体内容是使用Raft共识算法构建一个具有分布式事务支持的键值存储系统,它提供了一些骨架代码,我们只需要填充其中的一些核心逻辑。从架构和整体功能上来看,像是一个究极简化版的 TiKV。
本来寻思暑假学习一下分布式,写一个mit6.824,不过因为一些原因来写 TinyKV 了,看了一下内容,好家伙一点不比 mit6.824 简单,甚至梯度还很陡峭,几乎是超集,正好当代餐了。
多亏了 TinyKV 是用 Go 语言写的,如果和 TiKV 一样用的是 rust,不敢想会有多痛苦。
非常感谢 PingCAP 花费这么多精力做这样的一个课程项目。
内容
TinyKV 分四个 lab。
lab1 基于 go 库 badger 封装成一个简单 kv 存储引擎。
lab2 实现一个基本的 raft 算法,并在此上实现一个 kv 存储、GC 和快照
lab3 在 lab2 基础上实现 conf change、region split 和 simple scheduler
lab4 实现一个基于 Percolator 事务模型的 MVCC 事务支持
代码量上: lab2 > lab3 > lab4 > lab1
难度上: lab3 > lab2 >> lab4 > lab1
体会
虽然说想在夏天学一学分布式,但在做 TinyKV 之前对分布式了解基本为零,学习过 Go。基本是从头开始学习分布式,看了不少参考资料和博客,感觉写的时候大部分时间反而花在了看论文和博客上了。
分布式这一块感觉建立起对它的直觉非常重要,在看到日志的时候能够理解发生什么很重要。然后通过这些东西,反推出哪里出了问题才能不像无头苍蝇一样横冲直撞。
把一个分布式算法应用到代码上的时候,仅仅了解理论是不够的,实际跑的时候会发现各种各样奇奇怪怪的问题,其具体实现细节的复杂度远超论文的三言两语。(比如说,论文是假定消息的幂等性,而代码是要保证幂等性)
经验
最痛苦的一段时间莫过于刚开始的时候。一方面是刚学习分布式,对分布式没什么概念,上来就是看 raft 算法,既不知道它的背景和面向场景是什么,也不知道它想解决的是什么问题,还不清楚它在设计的时候为什么要这么设计。这些东西,大多都是在后面慢慢写代码的时候才理解的。
看日志或者测试的时候,大概会经过几个阶段:
- 完全看不懂,会对测试或者动辄几个 G 的日志有一些畏惧心理
- 能看懂一点测试或日志,但只能看到表面现象,不理解场景和具体发生了什么
- 能看懂发生了什么,用语言表述出场景因为什么故障而发生了什么事情,但暂时没有想到解决方法
- 根据具体场景和理论知识,想到了解决方法
这几个阶段过渡的时候,我主要是通过反复读 raft 原始论文,查阅博客和资料。尤其是可以借助 AI 工具,来帮助过渡,快速理解上下文到底要做什么,然后进一步追问。还有就是不要畏惧打日志和看日志,在并发的情况下,日志是快速回溯现场的有效方法,即使是 debug 也因为难以复现不便使用。
其他
仓库:
talent-plan/tinykv: A course to build distributed key-value service based on TiKV model
参考清单:
- Raft
- Raft小站: https://raft.github.io
- Raft 论文翻译:【译文】Raft协议 / raft-zh_cn.md
- Onefile raft:https://github.com/drmingdrmer/one-file-raft.git
- Raft in wiki:https://zh.wikipedia.org/wiki/Raft
- Etcd raft:https://github.com/etcd-io/raft
- Etcd 库解析:https://www.codedump.info/post/20180922-etcd-raft/
- TinyKV 博客:TinyKV 启~动!
- TinyKV 博客:Talent Plan TinyKV
- more-raft/notes.md
- Paxos
- paxos made simple 论文:https://lamport.azurewebsites.net/pubs/paxos-simple.pdf
- Paxos made simple 译文:https://blog.mrcroxx.com/posts/paper-reading/paxos-made-simple/
- Paxos in wiki:https://zh.wikipedia.org/wiki/Paxos
- TiKV
Project1
介绍
project1 是对 go 库 badger 进行封装,实现一些基本操作,并模拟列族。虽然这里的列族仅仅只是把各个列个通过编码链接在一起而已。
一般来说,比如 rocksdb,不同的列族会分别存储,减少在写入对应列的时候把一整行写入的写放大。也可以在特定情况下方便查找,比如 Percolator 事务模型就相当于定义了几个列族。
整体来说,这个部分的代码难度不大,就是把Go的一个库封装一下,属于是小试牛刀。属于是第一个部分把人骗进来,后面慢慢杀。
流程
Implement standalone storage engine
因为有关 CF 列族的工具函数,已经在 engine_util 完成了,只需要调用即可。Write 函数对 batch 调用 put 和 delete 即可。
Reader 只需要返回一个 storagereader 对象就可以了。
Implement service handlers
实现 service handlers,其中 get,put,delete 很相像,根据注释和参数基本可以推知要做什么。
其中 scan 需要了解一下迭代的流程。
需要注意的地方
需要注意的地方没什么。
Reader函数需要使用事务- 事务在丢弃的时候,需要
close,可以使用defer比较优雅的关闭 CF列族,其实就是把若干列起个名字,存在一起,至于为什么要这么做,跟 TiKV 的架构以后面的部分有关,可以通过阅读 TiKV 官方的博客了解。- 读取的过程是:获取事务、事务获取迭代器、迭代器迭代。
- 所有写操作都被封装在一个泛型接口中。
- 官方的
github classroom已经满了,只能使用本地测试。
Project2A
介绍
从 project2A 开始,难度就开始有点起飞了~
2A分为三个部分:
- 2AA,进行领导选举(包括论文5.1、5.2)
- 2AB,进行日志复制(包括论文5.3、5.4、5.5)
- 2AC,进行 Raft 包装
其中 2AA 和 2AB 也就是:

照理说,需要把这几个部分地方一一对照着论文完成,是一定可以通过测试的。不过反过来倒不一定成立,就算通过测试,也不代表跟论文一模一样,因为 2A 测试比较水,没有什么因为网络延迟,丢包和乱序的问题,在 2B 会发现这一点。
我的做法是:
- 多读一遍 Raft 论文,如果有测试过不了就再读读看,会惊奇的发现常读常新。
- 借助 AI 工具,问问这个测试是干什么的,流程是怎么样的,某个参数或者某个变量是怎么用的,
message中的字段含义是什么。 - 看看 Raft 小站的动画演示、看看
Etcd的实现。
我觉得这个 2A 很重要,虽然后面的部分也很困难,但是这个 2A 是理解 Raft 算法,建立 Raft 算法和分布式共识的直觉的基础。
2A 的流程我建议先不必过多管log.go部分,先完成raft.go部分,完成领导人选举,不然其实很难理解log.go中结构体的那几个索引applied、committed、stabled都是干什么的。等领导人选举,也就是 2AA 写的差不多了,或者基本过了,再开始写log.go部分。最后再写 2AC,也是这个部分最简单的,只有三个函数,两个测试。
流程
领导选举
领导选举这部分可以暂不理会 log.go 部分,仅完善 raft.go 这部分。
Raft 是强领导的,一个集群只能有一个领导,其他节点都是强迫听从领导。
正因为 raft 是强领导,后面在进行 propose 或者 append 的时候,不需要再进行 2PC,可以一阶段直接提交复制;可以认为是把 paxos 的 2PC 的第一阶段移动到了领导选举中,也就是达成共识,大伙都听领导的,之后再有 propose 就不用管别人了。我觉得这也是 leader 要向日志中添加一个空日志的一部分原因,也是为什么在选举领导的时候,集群会拒绝服务的原因。
在 2AA 这部分的领导选举基本遵守 term 大优先,难点可能在于收到 requestvote 之后对其的处理,需要遵守一系列论文的规则。
tick() 函数是推进工具,主要是推进 follower 发起选举和 leader 发出心跳,分别是推进选举和组织选举。每次选举超时时间均为随机,用于选举的快速收敛。
日志复制
日志复制这一部分需要完善 log.go 部分代码。
如果对 storage 这个接口有疑惑,可以查看:TiKV 源码解析系列文章(二)raft-rs proposal 示例情景分析
日志复制发生在 leader 选举出来之后,leader 通过心跳保持地位,通过心跳发送信息,并通过心跳的回复得知 follower 的信息来决定是否要发送日志。
集群成员的日志情况记录在 Prs 中,match 表示匹配,next 表示接下来要发送的。如果 match 小于 leader 的 lastindex,则会发送日志同步给 follower。
重点的操作时,sendHeartBeat,handleHeartBeat,sendAppendEntries,handleAppendEntries,handleAppendResponse 和 handlePropose
handleHeartBeat
- 判断 term,如果心跳的 term 小则不改变状态,仅发送回复消息
- 通过 1 的判断之后,becomeFollower并发送回复消息即可。
- 心跳回复消息是 term 和当前 term
sendHeartBeat
- 只有 leader 才能发送心跳;收到 beatMsg 需要发送心跳;心跳超时需要发送心跳;
- 心跳内容只是 term 和 commit: min(current_commit, Prs[to].commit) 无需其他内容
sendAppendEntries
- 只有 leader 才能发送 append entries;log 提交时需要发送;leader 当选时需要发送;收到心跳回复,发现 follower 日志比较落后时需要发送;收到 propose 时需要发送;收到 appendResponse 时,发现被拒绝需要重试发送。
- 发送内容为当前 term,next - 1,next - 1 处的日志 term,日志,commit
handleAppendEntries
- 判断 term,如果消息的 term 小则不改变状态,直接丢弃消息,可以选择不回复消息,也可以选择回复拒绝消息。
- 调用 becomeFollower
- 判断消息是否应该接受,基准是消息中的 index 是否在本地中存在,如果存在,本地中对应的 term 是否和消息中的 logterm 一致;如果任一不符合,则返回拒绝消息。
- 将日志放入 raftLog 中,会回复接受消息,同时将本地的 commit 与消息中的 commit 同步,选择两者的中的打者。
- 回复消息需要的内容是:当前 term,是否接受 reject,当前最新 index。
handleAppendResponse
- 判断 term,如果消息 term 大,则变成 follower,并丢弃消息;
- 判断状态,如果不是 leader,则丢弃消息
- 判断接受与否,不接受,则 index - 1,重新发送。
- 消息接受,则 match 取大者,next 值更新,同时尝试提交消息
Rawnode
建议阅读这两个文章:
里面介绍 rawnode 的作用和流程已经非常详细了。
主要接口就是 ready,hasready 和 advance。
Ready 返回推进的状态,hasready 返回是否有所推进,advance 进行推进。
在这个地方,nextEntries 会很有用。
需要注意的地方
- Raft 节点发消息的方式就是把消息 append 进入结构体中的 Msgs 即可。测试的方法就是从这里面拿出去消息进行发送,这种测试方法当然很怪,照理说不应该在里面写一个模拟网络或者通道的东西嘛;后来知道这是库的做法,因为库是要对外的。
- 在收到 requestvote 的时候,需要判断是否投过票的方主要通过 term;如果当前 term 小于消息 term,则需要重置 vote 值;如果当前 term 大于消息 term,拒绝投票;如果等于,那么可以根据 vote 值来判断是否应该投票。
- Raftlog 和 Raft 初始化的时候,需要从
storage.nitialState()中取出hardState,有的测试需要用到这个。 - 当候选者发现自己落选(集群中大多数明确拒绝了)的时候,应该重新变成 follower,再次等待选举超时再变成候选者。
- 只有当 Follower 的日志中,存在一条日志,其索引和任期都与 Leader 发送的 AppendEntries 请求中的 Index 和 Term 完全一致时,Follower 才会接受 Leader 发送的新日志条目,否则拒绝。这是 Raft 日志一致性的基础。
- Append RPC 中,需要
prevLogIndex日志的prevLogTerm相等才能接受,这里可能要注意 append 的时候可能会删除或者覆盖部分无效日志。 - Leader 在发送 Append RPC 的时候应该直接把所有条目全部发送,这个其实不全部发送也行,只是这里的测试全部发送会比较方便。
request vote中,拒绝投票和变成follower不是绝对相连的的过程。变成follower的时候也可能会拒绝投票。- Leader 在收到 follower 的 append response 的时候,需要检查是否可以提交,如果可以提交需要更新 commitindex,并立刻广播给所有 follower ,这点在 tinykv 的 hint 中也可以看到
- Follower 的日志必须至少与 Candidate 的日志一样新才能投票。具体来说,Follower 的最后一个日志条目的任期必须大于等于 Candidate 的最后一个日志条目的任期,如果任期相同,则 Follower 的索引必须大于等于 Candidate 的索引。
- Leader 在处理 heartbeat response 的时候,如果发现收到的信息的 commit 较小,那么需要给 follower 发送一个 append RPC 来保持一致。
- 注意 RPC 的幂等性。
- Leader 只会提交当前 term 的日志,当它收到 append response 发现以前 term 的日志即使可以提交也不会选择提交。“Leader 只能通过计数副本数来提交当前任期的日志条目,之前任期的条目必须通过其他方式(如后续的日志条目)来间接提交。” 这是为了安全性:如果之前的 Leader 在网络分区期间提交了条目,但新 Leader 不知道,直接提交可能覆盖已提交的条目
- 在节点只有一个的时候,需要在 hup 或者 propose 之后立刻成为 leader 或者 commit,因为已经是大多数。但是需要注意判断,当前节点是否在集群中,或者说是否在 Prs 中,后面 3B 会具体陈述这个问题
- 当新 Leader 的日志不是最新的时,它必须能够覆盖其他节点上更高任期的日志条目。也就是需要在 raftlog 中进行截断。
- Raft 节点在成为新 Leader 后,需要忽略来自旧 Leader 的 AppendEntries 消息。
- 如果 Follower 的日志在 prevLogIndex 处没有与 prevLogTerm 匹配的条目,则拒绝此次日志追加请求。
- 如果 Follower 的日志和 Leader 的新日志条目在同一 index 但 term 不同,则删除本地该 index 及其之后的所有日志,并追加 Leader 发送的新日志条目。
- 如果 Leader 的 commitIndex 大于 Follower 的 commitIndex,则 Follower 更新自己的 commitIndex 为 min(leaderCommit, last new entry index)。其中 last new entry index 是指:append RPC 中最后一个 entry 里面所写的 index,或者是 prevLogIndex。
- Raft 协议中所有角色(Follower、Candidate、Leader)在遇到更高任期的消息时,降级为 Follower并更新相关状态。
- 收到 MsgRequestVote 时,其 Lead 值应该是 None。只有收到 MsgAppend 或者 HeartBeat 时,Follower 才会把 Lead 设置为 Leader 的 ID。
- 在 project2A 中,raftLog 的 stabled 值是由测试进行修改的。
- 选举超时时间应该随机为
r.electionElapsed = rand.Intn(r.electionTimeout) + r.electionTimeout这是从一个测试中发现的。 - raftLog 中的 entries 除了上面中的截断情况,应该是一直增加的,只是 stabled 会变化。关于其中 entries 的维护,推荐查看 etcd 的 unstabled 实现,当然不建议直接抄上去,因为测试的方法有点古怪,很不方便。别问我怎么知道的。
- 这个不确定是不是我实现的问题:在当选 leader 之后,需要初始化 Prs 数组,添加一个空条目,同时广播给所有人;其中初始化 Prs 数组需要在添加空条目之前,也就是说初始化 next 的时候,它的值应该是空条目的 Index 值。不过这是我的实现方式,我搜索了一下,其实应该是都行,我是我的条件判断导致这种方式更合适。
- Raftlog 的 stable 和 unstable,应该通过 stabled 索引分割,而不是自己新添加的 firstIndex,这个 firstIndex 应该只是用来分隔快照和非快照,不用来分隔持久和非持久。
- 在 becomeXXX 函数应该把 Vote 值至为 None,Vote 变化的时机在:投票,收到leader消息。
- rawnode 初始化的时候应该为空,方便后面 HasReady 统一判断。
- advance 函数只需要修改状态信息即可。
- hasready 和 ready 需要判断状态是否发生了变化。
Project2B
介绍
2B 是基于 2A 完成的 raft 服务来实现一个可容错的分布式 KV 存储。
只有一个基本的 raft 服务是没什么用的,需要通过这个服务在上层进行应用。把一个一个日志转化为对应的命令然后应用到对应的 KV 存储中才算是有用了。
而这个封装基本上的流程是:接受指令 -> 达成共识 -> 应用指令。所有指令都需要这三个过程,包括读操作,除了 Transfer Leader。
1 | // PS:读操作也需要进行 propose 达成共识的原因和线性一致性有关,不然直接本地读可能出现脏读等问题。 |
其中 raft 仅完成了第二部达成共识,project2B 就是要求完成第一步和第三步。
虽说如此,写的时候会发现,出问题的大多数还是第二步达成共识。
这部分问题在于上手蒙,需要了解一个整体框架,推荐文章:TiKV 源码解析系列 – multi-raft 设计与实现
整体来说 2B 是要 raft 层写的健壮,而其他别写漏。
在写 2B 的时候,我向 TinyKV 课程项目的作者之一请教过,TinyKV 在整体架构上和 TiKV 非常相似,在 raft 层则和 etcd 非常相似。因此在不熟悉的地方,可以考虑参考这两个项目的文档。
不得不说,这个 2B 我做有些浑浑噩噩,我虽然理解了这个流程,但是个别错误我只是修改了没有理解非常具体的出错原因,不过好在后面逐渐理解了。
流程
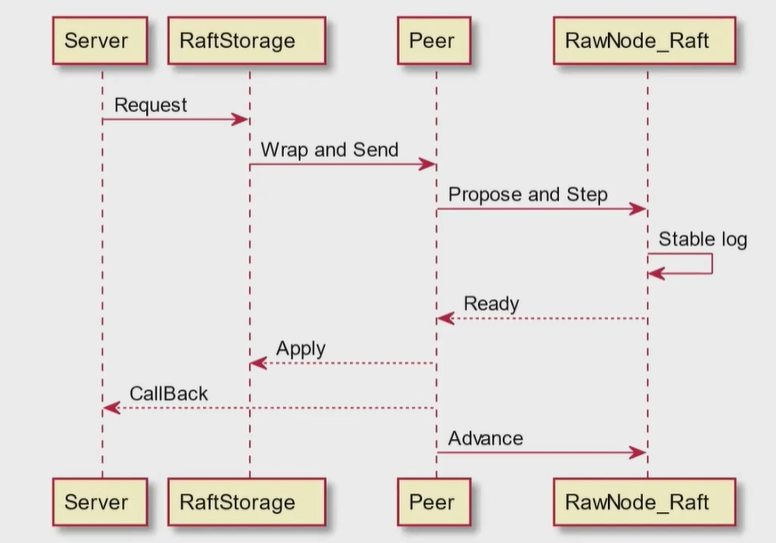
- Server 发起请求给 raftstorage,转交给 raftstorage 处理
- raftstorage 进行包装成 raft_cmd 类型消息,并转发给对应 region 的 peer
- Peer 进行 propose,在 raft 层达成共识,并持久化日志
- Raft 层达成共识之后,peer 层通过 ready 取出 raft 已经提交的消息
- 随后 peer 进行应用,调用 raft 层的 advance 进行推进。
- 最后调用 callback,通知上层。
主要内容在 3.、4. 和 5.。在 peer_msghandler.go 和 peer_storage.go。主要内容是持久化、状态的同步以及消息应用。
像 2A 一样,rawnode 被封装在 peer 中;peerStorage 实现了 Storage 接口。
peer_storage.go 中主要进行状态的持久化。其中,RaftLocalState 保存 HardState 和 LastIndex,持久化于 raftdb;RaftApplyState 保存 AppliedIndex 和 Truncated Log Info,持久化于 kvdb;RegionLocalState 保存 Region 信息和对应的 Peer 状态,持久化于 kvdb。
peer_msghandler.go 中主要函数是 proposeRaftCommand,HandleRaftReady。
proposeRaftCommand 进行消息的编解码,并进行 propose 达成共识。
HandleRaftReady 则是在 raft 层有所推进时,持久化状态,发送消息,最后应用指令。
需要注意的地方
- RaftLog 的 Term 和 Index 初始化为5,反正是非零,注意让 Raft 和 RaftLog 编写的更加健壮,处理错误。
- Raft 初始化于 storage, peers 从 storage 中获取。我在 2A 的时候总是从 config 中获取,导致 2B 出问题没发现为什么。
- 现象1:测试 scan 时,会出错误,但是有时候又正确,具体点就是缺少部分 key。
- 现象2:打印日志发现有多个 leader,因为节点不知道彼此,所以都认为只有自己一个节点,所以都是leader。
- entry 获取 Term 函数 需要注意处理 ErrCompact 错误。
- 现象1:日志中看到,follower和leader不断对日志,直到 index = 0,才对上日志。
- 现象2:打印错误日志之后发现爆出,ErrCompact 错误,确定是在 RaftLog 中未合理处理 compact 情况。
- raft 在提交的时候错误的计算 majority 。
- 解决办法:正确公式应该是 cnt + 1 > len(prs)/2,不能因为没有计入 leader 就使用 cnt >= len(prs) / 2 可能会因为除法向下取整出问题。
- 现象1:导致极偶尔可能会出现少一条的情况,并且确定只有在分区或者重启的时候才会出现这个情况。要求这个被分区的 follower 在分区结束之后当上了 leader 才会出现这个现象,很难复现,大概七次运行会有一次出现错误。
- 测试时偶尔会出现 timeout 情况。
- 解决办法:增加了日志快速回推优化,也就是在处理 append entries 的时候进行优化。但是这会导致
TestFollowerCheckMessageType_MsgAppend2AB过不了,思考了一下,取消了这个测试。在优化中,让 Message 中的 index 和 term 在 reject == true 的时候表示conflictTerm和conflictIndex,没有在信息中增加新的字段 - 现象1:有时候会出现 timeout 错误,是因为采用朴素的减一策略导致的。
- 解决办法:增加了日志快速回推优化,也就是在处理 append entries 的时候进行优化。但是这会导致
- 一定一定要注意 RPC 的幂等性。尤其是 append RPC 的幂等性,否则很容易出问题,比如乱序的情况下出现各种奇妙的错误。需要特别注意的是,在 append 日志的时候,需要和对应位置的日志进行检查,必要时删除本地的日志,与新发来的日志对齐,确保不重不漏;而发来的日志本地全都有的时候,则不必 append;确保幂等性。
- 在
HandleRaftReady函数中记得清洗消息中的无用内容。
Project2C
介绍
2C 主要是做快照,主要在2B的基础之上,难点在状态保存持久化和恢复,需要看不少代码。
快照是对消息进行合并,并丢弃这些冗余的消息。而对于过于落后的节点,leader 则需要发送快照对其同步。在必要时,leader 通过调用 Snapshot() 函数,并发送它。
从这一节开始,由于会出现一些重试操作,日志里面会有很多 error,把日志撑的非常大,不易于查看,需要比较有耐心的查看日志,选择性的打日志。
流程
Raftstore 会定期检查是否需要进行日志垃圾回收,如果需要,它会提出一个 Admin 类型的命令。
在process中根据admin命令的类型执行与普通 requests 不同的操作,因为他们的类型不同,动作也不太一样。但这里只是压缩日志,并非生成快照,生成快照是一个 lazy 的动作,只会在必须要发送快照的时候才会生成。
这里压缩完之后,就轮到了 raft 层的事情了。主要函数是 sendSnapshot,handleSnapshot。
sendSnapshot
- 发生在 sendAppend 中,当想发送的日志发现已经被压缩了,返回了 ErrCompact 错误,那么这个时候就需要发送快照。
- sendSnapshot 中,生成快照是比较慢的,且这个操作是异步的,在发送的时候不会立刻准备好,需要等待一会重试才发送成功。
handleSnapshot
- 如果已经有了正在处理的 Snapshot,直接丢弃,建议打个 log。
- 虽然处理 Snapshot 的思路基本上是清空覆盖,清空本地的状态,用快照去覆盖。
peer_storage 中需要完善 applySnapshot 函数,其主要思路也是用快照去清空覆盖本地的状态,并且把所有内容同步到持久化存储中。
peer_msghandler 中需要修改的地方不多,主要是判断应用快照发生时,修改 region 信息,且需要注意 rawnode 对快照的处理,在 advance 时把 raft 的 pendingSnapshot 给至为 nil。
需要注意的地方
- 在 rawnode 中增加对 snapshot 的判断和处理,并在 advance 中调用 maybecompact。
- raft 的初始化 newRaft 中,如果 config 中设置了 applied 和 committed 可能需要覆盖 raftlog 的初始化的值。
- 现象1:莫名其妙的 applied 和 committed 值,导致 panic。
- raft 中注意处理 ErrCompated 和 ErrUnavailable 错误。
- 现象1:会出现不知所谓的 panic
- 在 handleSnapshot 中,如果接受了快照,可以认为是快照把当前状态完全覆盖了。所有信息都需要清空覆盖,包括 raftLog 的 entries。
- 现象1:有时会发生,在最后一个测试中大概率发生。重启 peerStorage 时 panic,错误是 lastIndex < appliedIndex。也可能在 newRaftLog 中panic,错误内容大体一致。花了很久去debug。
- 发送 append 的时候,如果 r.RaftLog.firstIndex > Next 或者出现 ErrCompacted,需要发送快照。发送快照时,需要调用 storage.Snapshot 这个函数注意处理
ErrSnapshotTemporarilyUnavaliable错误,因为拍快照是异步的。返回错误之后,让上层去处理即可,raft 层需要注意保证幂等性。 - RaftLog 中注意考虑快照的存在,增加健壮性。
- SaveReadyState中增加对快照的判断,如果需要,返回 applySnapshot 的值。
- applySnapshot 主要是先清理旧数据,然后根据 snapshot 更新 ps.raftState 也就是 RaftLocalState,ps.applyState 也就是 RaftApplyState。并在对应的raftdb、kvdb中保存值(快照接收之后,相当于覆盖了之前的状态,记得清空)
- HandleRaftReady 中在 SaveReadySate 之后增加对 snapshot 的处理,在处理这部分的metaStore的时候,注意可能需要上锁。同样处理方式是清空加覆盖。
- process 中,增加对 adminrequest 的处理。主要思路仍然是清空覆盖,注意调用 ScheduleCompactLog 分派任务。
Project 3A
介绍
3A 属于是在 3B 打你一棒子之前给口糖吃吃,只是简单的 TransferLeader 和 AddNode、RemoveNode。不过最好写的健壮一些,让 3B bug 少一点。
分布式一大特色在于集群拓展以提升性能,因此集群成员配置变更必不可少,这里采用的是单个节点的成员变更,而非论文中的 joint consensus ,因此相对简单一些。而 TransferLeader 则是成员变更不可缺少的一个工具,尤其是 leader 被从集群中删除时。
吐槽一句:得亏 tinykv 是 go 写的,写的时候基本不用考虑语法或者内存问题;不敢想如果用 rust 写会有多痛苦。
从 project3 开始基本开始熟悉了这个项目,以及整体的流程。
流程
raft 层主要函数是 sendTimeoutNow, handleTimeoutNow, handleTransferLeader 以及 addnode,removenode。
前三个函数是在 propose 阶段发生的,而后两个函数则是应用阶段发生的。
前两个函数 sendTimeoutNow,handleTImeoutNow 很简单,只需要进行对应操作即可。
handleTransferLeader
- 判断当前是否为 leader,如果不是,则将此消息转发给 leader
- 判断是否集群中有 m.From 节点,不过没有,丢弃
- 判断 leadTransferLeader 字段
- 是否与 msg 中的相等,若是,则忽视改次请求
- 是否为 None,若是,应用改次请求
- 是否与 msg 中的不同,且不为 None,若是,则终止当前转移,并应用最新的请求。
- 应用需要转移 leader 的对方的日志也为最新,同时在转移 leader 这段时间拒绝 propose。
addnode、removenode
- 至空 pendingConfChange
- 删除或添加对应的节点 id,但是要考虑幂等性,如果已经存在或不存在,则不做任何操作。
- 如果是删除,注意需要尝试推进 commit
需要注意的地方
- 增加 sendTimeOutNow、sendLeaderTransfer、handleTransferLeader 和 abortTransferLeader
- abortTransferLeader 其实只需要把 leadTransferee 至为 None 即可,因为其本身只是一个动作,不管成功与否都不影响集群的正确性。
- 在removeNode的时候,如果自身是leader,需要尝试进行提交,因为可能可以提交了。
Project 3B
介绍
3B 分为三个部分 TransferLeader、ConfChange 和 Region Split。在 raftstore 层实现这几个 admin 类型命令。region split 是 multi-raft 的基础,用于提高 raft 的并发,提高 raft 的效率。
前两个需要一起做,第三个最好在前两个测试可以完整通过的之后再去实现。毕竟 3B 是整个 project 中最难的一个部分。有很多想不出来的 bug;诡异的并发问题;莫名其妙的顺序问题;大到打不开的日志文件;意义不明的 requst timeout;代码量不大,但是诡异的问题一点不少。
因为 3B 各种问题非常多,难以确定;最好在一次修改之后,先跑一跑 project2 和 project3A,可能会有意外惊喜 😦
流程
TransferLeader
在 proposeRaftCmd 中直接调用 rawnode 的 transferLeader 即可,无需 propose,因为 transferLeader 只是一个集群一个动作,不必添加记录,转移成功之后,新 leader 自然会添加一条日志。
ConfChange
- Propose,不过 ConfChang 需要调用不同的 propose 函数
- Raft 层收到 Propose,如果当前已经在进行 ConfChange,那么需要返回错误,告知上层稍后重试。否则,需要设置 pendingConfIndex,在应用这次之前,拒绝其他 ConfChange 请求。
- Process, 需要处理 epoch stale 错误,检查 epoch 是否为最新。
- 修改 RegionLocalState,修改 peers,注意幂等性,如果已经增加或者删除,那么忽略它。将状态持久化到 db 中。
- 修改元数据 meta,记得上锁。
- 调用 applyConfChange,修改 raft 层的状态。
- 进行回调
这个流程并不困难, 还是 接受指令 -> 达成共识 -> 应用指令,大多数出错可能还是 raft 层。
Split
Split 是一个特殊的写操作,修改的是 Regin 元数据。
其他步骤基本一致,但是因为 Split 的触发是基于 region 的大小的,因此需要修改前面的普通指令 put 和 delete,更新 region 的 SizeDiffHint。同时检查指令是否在对应的 region 中。
- Propose
- Raft 层收到 Propose,与普通操作别无二致,无需特别处理
- Process,需要处理 epoch stale 错误,并且检查 key 是否在对应的 region中。
- 判断新分裂的 peers 长度是否和原长度相同,不相同则拒绝,稍后重试
- 构造新的 region,同时使用 split 指令中的信息,构造出 peers。修改 id 等信息
- 将元数据写入 db 中
- Createpeer 创建新的 peer,修改 meta 插入新的 region。使用 router 注册 peer,并且发送 StartMsg 启动节点。
- 重置统计信息 SizeDiffHint 和 ApproximateSize
- 两个 region 都调用 notifyHeartBeat 刷新缓存
需要注意的地方
我在 3B 遇到的问题快可以凑一个十八罗汉了 XD
- ConfChange 编码问题
ConfChange 和其他指令的编码和解码方式不太一样,需要编码两次
1 | // ConfChange 编码 |
解码:
1 | if entry.EntryType == eraftpb.EntryType_EntryConfChange { |
- 在发送心跳的时候,需要 commit == min(r.RaftLog.committed, r.Prs[to].Match),这是因为在 store_worker 中,通过信息中的 commit == 0 特判,来判断是新建节点。
- 日志呈现:store_worker 不断出现 don't exist 错误.
- 发送 snapshot 不断出现错误,错误是 stale 的 snapshot,不断 epoh_not_match 最后 request timeout,在 processAdminRequest 中仅修改了 addnode 中 epoch 的 conf_ver 忘记修改 removenode 中 epoch 的 conf_ver 了。
- 在 TestConfChangeRecover3B 中,总是出现
peer for region id:1 region_epoch:<> is initialized but local state hard_state:<> last_index:xxx last_term:xxx has empty hard state 错误,导致 Panic。
- 原因是在接受 applySnapShot 的时候,忘记根据快照应用 HardState 了。不知道为什么 2C 测不出来
- [region x] x meta corruption detected. 查看日志,发现是在 processAdminRequest 中,一个 peer 被删除了两次,第一个清空之后,第二次报错。
查看可能调用 destroyPeer 函数的地方之后发现,应该是在 processAdminReqeust 中没有过滤已经处理过的 ConfChange 请求。判断两个 ConfChange 请求是否相等,需要其中的 peer 既 id 相同也 storeid 相同
这之后仍然出现该错误,查看日志,搜索 remove 相关日志,发现存在某些情况下,删除之后的 region.Peers 仍然存留信息。再次排查之后发现,只有自己被删除才会出现这个情况;对于RemoveNode命令的apply,不需要对 storeMeta 进行修改,destroyPeer 会负责
下面是 request timeout 大军
- 删除节点之后的 request timeout,这个是什么 tinykv 必吃榜嘛?每个 tinykv 的博客基本都会记录这个问题。
用的是原论文的想法,当 leader 不在新配置中,也就是 leader 被删除的时候;需要进行 transfer leader,这个新的 leader 在新旧配置的交集,也就是把 leader 转移给一个集群中的任意一个其他人,这个节点和 leader 的日志越接近越好,可以减少交接速度。也就是:删除的是 leader,那么可以在 propose 阶段直接 transferleader,然后返回一个错误,让上层之后重试即可,这样一定可以解决问题,概率上没有问题。
- 增删节点之后,request timeout。仔细观察日志,发现连续增删同一个节点,发生 timeout。是在无需操作增删的时候,忘记返回 cb 了。导致上层不断重试,最后超时。
- pendingconfindex 用来标记一个 confchange 操作是否已经应用,在应用这个 confchange 之前,拒绝其他 confchange 操作,这个拒绝应该发生在 raft 层的 propose 中,也就是需要对 msg 的类型进行判断。标记的方式是:
pendingconfindex != None && pendingconfindex > r.raftlog.applied。否则可能因为奇奇怪怪的原因而 timeout,这个日志呈现出来是千奇百怪的,还好有博客已经指出了这个问题。 - Transfer leader 应该在一个 election timeout 的时间之后再取消,而不是下一次 tick 就取消, 否则可能因为transfer leader 失败重试而 timeout。可以参考 etcd-raft 的实现。
- raft 层不应该返回 util.errnotleader 错误, 否则可能会在日志中出现大量的 errnotleader 错误, 因此 timeout 而且日志膨胀非常大。
- raft 层,pendingconfindex 应该在 propose 时候设置,而不是在 apply 的时候设置, apply 的时候设置已经太晚了。同时,只需要拒绝后续的 confchange,不需要拒绝普通 propose。不然会阻塞正常的 propose,导致 timeout。
- raft 层,addnode 之后,由 leader 发起 heartbeat 尽快创建新节点,但是却总是创建不了,日志上出现很多
region xxx in tombstone state: xxx,同时后面导致创建不了节点:
1 | for _, region := range meta.getOverlapRegions(&metapb.Region{ |
Debug 发现,这里 region 莫名有一个 ["", "") 的 startkey 和 endkey,导致总是有交集。但这只是问题的表现,似乎根因不出在这里,经过排查,是在修改 regionRanges 的时候错误的插入了 region 而且在后续的删除的时候没有正确删除导致的错误。处理方法是删除 maybecreate 最后的 replaceOrinsert 同时修改 destroyPeer 中的判断,修改为先删除后判断初始化。不然会无法创建节点,导致 tiemout。
- raft 层,最好提供一个接口,让 raftstore 希望在 leader 被删除的时候转移 leader 的时候选择一个日志尽可能新的follower,不然可能因为转移 leader 而拒绝服务,最后 timeout。
- 在 transferLeader 的时候,如果 sendTimeOutNow 不幸丢失,那么如果没有重传机制,或者没有在 heartbeat 处理这种情况,或者 leader 没有主动变成 follower 那么可能因此无法推进。需要在日志中仔细观察 dropped,否则可能会有两个 leader,一直拒绝服务,导致 timeout。
- 比较棘手的是一种情况发生在先添加节点随后紧接着删除 leader,日志中呈现一直选举不出 leader 导致拒绝服务并 timeout。
在发送 transferleader 之后,接收方已经接受开始选举,同时旧 leader 下位,但是接收方却选举失败了,比如因为丢失的情况;同时还有新来的节点没有应用,他不知道当前集群都有谁,这个时候选举就可能一直失败,虽然概率很小但是很尴尬,确实存在。
概率大概在 1/20 左右。这种情况一方面要加强候选者重试,重新发票;另一方面我认为要对新节点进行处理,在新节点回复 leader 第一次 append 之前,不进行下一次 confchange,但是可以进行新的 propose,相当于延长了 addnode 的 confchange 时间
我两个都做了,代价就是有一个测试 TestRawNodeProposeAddDuplicateNode3A 过不了了。
补充:后来过了 3B 之后仔细考虑发现,其实这个情况就是后面的第十七条,还是因为新节点没有集群信息导致的错误(在选举失败之后新节点和集群剩下节点的处理上是一样的)。因此其实只要完成第十七条的修改,这个问题也就完成了,不必延长 addnode 的 confchange 时间,也不必牺牲 TestRawNodeProposeAddDuplicateNode3A。
- snapshot 消息可能会丢失,导致后续出错,在 leader 收到 heartbeat 的时候,如果消息的 term 更大,需要变成 follower 并回复心跳。简单的一种方法就是 snapshot 多发几次,这样就不会出现问题,不过还是概率而已,大概概率为 5/200,后面还是新节点因为不知道集群中其他节点的信息导致选举不出 leader 进一步 timeout。
- 考虑这么一个场景:
新增一个节点 A,当前 leader B 尝试发送快照对其进行初始化,但是快照丢失,最后导致节点 A 超时开始选举。因为节点 A 没有初始化,并不知道集群中的其他节点,这导致节点 A 选举成功变成 leader,后来 leader B 发送心跳,节点 A 回复心跳 leader B 得知了这个事情,主动变成 follower 并开始重新选举。但是因为 leader A 在当选 leader 之后向日志中 append 了一个日志,这个日志的 term 更大,导致 A 不会投票给 B,这导致无限循环,永远选举不出有效的 leader 并 timeout。
这个问题的本质是信息的不对称。起初,我想不到什么优雅的解决方案,选择的方法方法是:发送快照的时候多发送几次,同时在心跳的时候检测,如果发现过于落后,就发快照。概率大概在 1/50 左右会出现这个错误。
最后发现根本问题,这其实是一个 2A 的问题。我在 2A 默认了一个节点一定在自己的 Prs 中,当一个节点发起选举的时候会给自己投票。但是对于 add 进入集群的一个节点来说,这是不正确的。一个 peerstorage 在初始化的时候是空的,没有任何 peer 信息,即使是自己本身的信息也没有。结合这个场景,也就是在给自己投票之前,先判断自己在没在这个集群中,也就是 Prs 中是否有自己,如果没有就不给自己投票,这样就成为不了 leader,虽然 节点 A 还是会 term 增加,但是不会因为成为 leader 而 append 一个日志,也杜绝了这个情况,节点 A 会在随后投票给节点 B,这样也没必要重复发送 snapshot。
- split 中出现一个错误:调用如下:
1 | panic: requested entry at index is unavailable |
出现概率极低,我测试非常多次仅仅出现一次,概率可能不足 1/200,跑了一个晚上却再也没有复现出现问题,没办法找到原因。猜测可能跟 split 操作的原子性有关,需要元数据和持久化存储间的不一致导致的错误。
Project 3C
介绍
3C 就简单了,只需要实现两个函数,而且详细步骤文档已经给出。
其作用是根据心跳获取统计信息,告知 scheduler,让 scheduler 更新对应的 region。
以及调度,平衡各个 region 的数量和大小。
流程
文档给的非常详细了。
需要注意的地方
这里记录一个非编码的错误
1 | ❯ make project3c |
这个问题是由于 etcd 版本与 Go 1.24 版本不兼容 导致的。
错误发生在 etcd 的 HTTP ServeMux 注册 pprof 路由时.
错误信息:parsing "/debug/pprof/trace ": at offset 0: invalid method "/debug/pprof/trace"
这是因为 Go 1.24 对 HTTP 路由解析变得更加严格
版本兼容性问题:
项目使用的 etcd 版本:go.etcd.io/etcd v0.5.0-alpha.5.0.20191023171146-3cf2f69b5738 (2019年的版本)
当前 Go 版本:go1.24.4 (2024年版本)
这个老版本的 etcd 与新版本的 Go 不兼容
具体触发点:
在 scheduler/server/config/config.go:613 中设置了 cfg.EnablePprof = true
etcd 启动时会注册 pprof 路由,但路由格式不符合新版 Go 的要求
最简单的解决方法就是:
在 scheduler/server/config/config.go GenEmbedEtcdConfig() 把 cfg.EnablePprof = false
Project 4
介绍
仅靠 Raft 一次只能对一个值达成共识并返回解决,单单 raft 是做不到多个操作的 ACID 的,因此还是需要分布式事务,也就是这一节
P4 是对 raft 的应用,基于 raft 来实现事务,使用的是 Percolator 事务模型。本质上是一个 2PC 的拓展。
可以查看文档:TiKV 源码解析系列文章(十一)Storage – 事务控制层 还有一个笔记:percolator/notes.md
Percolator 事务模型可以提供快照隔离(SI)的事务隔离级别,当然它是基于 MVCC 的。当然这里没有实现 SELECT xxx FOR UPDATE,因此可能如果真的关心写倾斜异常的话,是没办法避免的。
流程
4A
为 badger 库进行进一步封装,满足 Percolator 事务的要求,在 MVCCTxn 中 writes 字段用于现在本地写,随后在事务提交或者回滚时一口气利用 write_batch 写入全部内容,保证写操作的原子性。
这部分的三个函数 GetValue、CurrentWrite 和 MostRecentWrite 操作流程比较相似,都是先 seek 查找对应位置,然后迭代,根据时间戳 check 是否符合条件,最后返回对应结果。
4B、4C
-
KvGet
-
func (server *Server) KvGet(_ context.Context, req *kvrpcpb.GetRequest) (*kvrpcpb.GetResponse, error) <!--code6--> -
获取存储读取器:创建存储快照
-
创建MVCC事务:使用开始时间戳
req.StartVersion -
收集锁定键:提取所有要修改的键用于latch管理
-
获取latches:调用
server.Latches.WaitForLatches()确保并发安全 -
逐个处理mutation:
- 调用
prewriteKey()处理每个键 - 检查锁冲突和写冲突
- 创建锁并放置值
- 调用
-
写入存储:如果没有错误,调用
server.storage.Write()提交修改 -
验证latches:调用
server.Latches.Validate()确保一致性 -
释放latches:在defer中释放所有latches
-
prewriteKey 辅助函数:
- 检查现有锁:
txn.GetLock(mut.Key) - 检查写冲突:
txn.MostRecentWrite(mut.Key) - 创建新锁:设置primary、timestamp、TTL等
- 根据操作类型放置或删除值
-
KvCommit
-
func (server *Server) KvCommit(_ context.Context, req *kvrpcpb.CommitRequest) (*kvrpcpb.CommitResponse, error) <!--code7--> -
获取存储读取器:创建存储快照
-
创建MVCC事务:使用读取时间戳
req.Version -
创建Scanner:调用
mvcc.NewScanner(req.StartKey, txn) -
扫描循环:
- 调用
scanner.Next()获取下一个键值对 - 检查键是否被锁定
- 根据锁状态创建相应的
KvPair(带错误信息或正常值) - 直到达到限制或扫描完毕
- 调用
-
关闭Scanner:在defer中清理资源
-
KvCheckTxnStatus - 检查事务状态
-
-
KvCheckTxnStatus
-
func (server *Server) KvCheckTxnStatus(_ context.Context, req *kvrpcpb.CheckTxnStatusRequest) (*kvrpcpb.CheckTxnStatusResponse, error) -
获取存储和事务:创建MVCC事务
-
获取primary key的latch:确保并发安全
-
检查事务状态:
- 查找已有写记录:
txn.CurrentWrite(req.PrimaryKey) - 如果已提交,返回提交时间戳
- 如果已回滚,返回相应状态
- 查找已有写记录:
-
检查锁状态:
- 验证锁的存在和所有权
- 检查TTL是否过期
-
处理TTL过期:
- 创建回滚记录
- 删除锁和值
- 设置相应的Action
-
返回锁TTL:如果锁仍有效
-
-
KvResolveLock
- 获取存储和事务
- 查找所有相关锁:
mvcc.AllLocksForTxn(txn) - 获取所有锁键的latches
- 根据CommitVersion决定操作:
- 如果
CommitVersion == 0:回滚所有锁 - 否则:提交所有锁
- 如果
- 批量处理:复用
rollbackKey()或commitKey()逻辑
