读论文-Architecture of a Database System
Architecture of a Database System
原文:https://dsf.berkeley.edu/papers/fntdb07-architecture.pdf
论文出于 2007 年,作者是 Joseph M. Hellerstein, Michael Stonebraker, James Hamilton。
年代较早并且更重视于体系结构与其他鲜少被提到的地方,很多新技术没有提及,如:SSI,NoSQL等
本文总体上是对论文的翻译、阅读。有一些不确定单词语句之处,会给出原文,附加我的翻译。一些地方可能会给上注。
本文的正确使用方式或许是根据某些需要的点,去查看相应的引用论文。
Abstract
介绍了 DBMS 的重要性和先进性。由于一些原因,介绍 DBMS 系统设计问题的文献较少。论文介绍了 DBMS 的设计原则的框架讨论。包括进程模型、并行框架、存储系统设计、事务系统实现、查询处理器和优化器架构,以及经典的组件和程序。
嘻,全是我想看的,是不是说明我啥也不会啊(
1 Introduction
再次强调了 DBMS 的复杂性,重要性。提到早期的 DBMSs 在计算机科学领域是具有重要影响力的软件,其思想和实现在各处都被借鉴使用。
对于 DBMS 的课程没有得到应用的重视。分析了两个原因:
- 应用领域的 DBMS 圈子很小。市场只允许少数高端巨头存在。数据库设计圈子很小:许多人处于同一个学校,研究相同的项目,从事于相同的商业产品
- 数据库的学术领域常忽略体系结构问题。数据库的教科书专注于算法和理论方面,而很少讨论整个实现时的体系结构。
总而言之,关于如何构建数据库系统的许多传统智慧是可用的,但很少有人写下来或广泛交流。
论文试图抓住现代数据库系统的体系结构观念,同时讨论一些先进的话题。有一些问题出于文献,有一些问题处于产品手册或者惯例。
论文的目标是关注整体系统设计和强调教科书中通常没有讨论的问题,为更广为人知的算法和概念提供有用的上下文。
论文假定读者熟悉数据库系统教材并且熟悉现代操作系统基本功能。
1.1 Relational Systems: The Life of a Query
论文强调了关系型数据库在基础领域和先进领域的重要性与地位,表示本文会关注于关系型数据库。
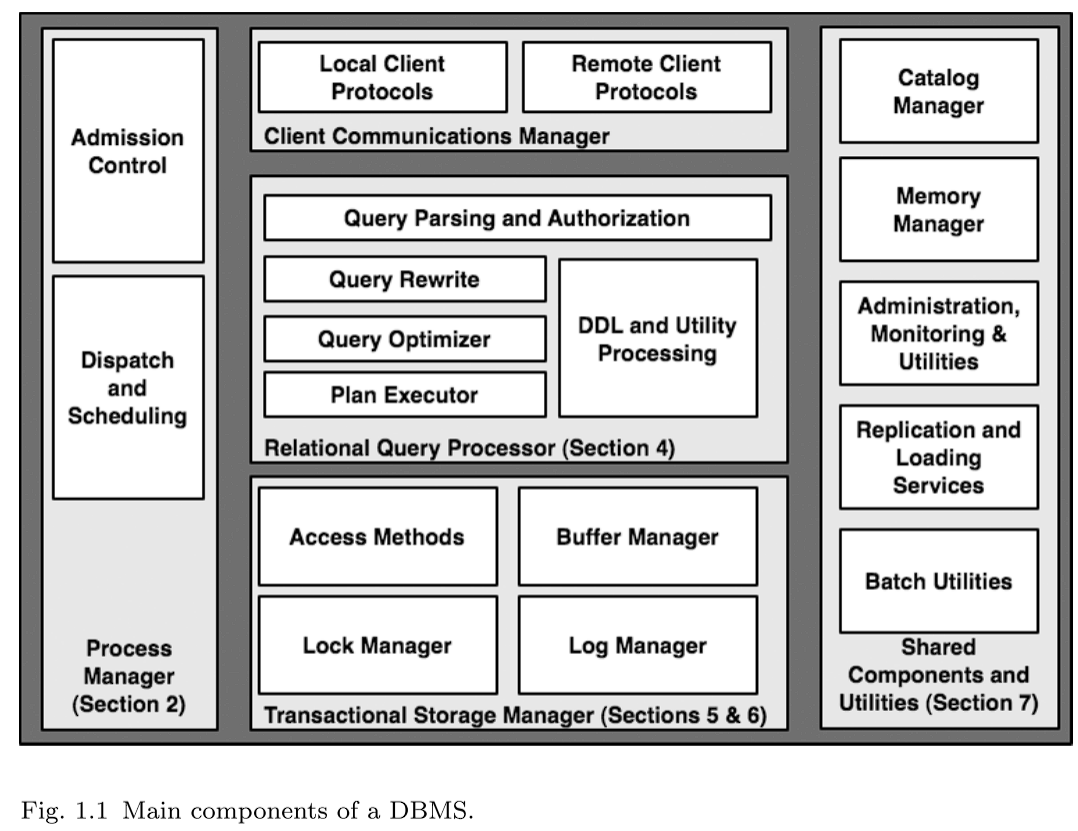
作为对这些部分的简单介绍以及论文后些部分的总结,可以关注一句 SQL 的生命周期。
考虑机场中一个简单但典型的数据库交互,其中登机口代理单击表单以请求航班的乘客列表。
当按下查询按钮之后一个单查询事务工作如下:
- 个人电脑与服务器建立网络连接、直接与数据库建立网络连接、或者与一个在客户端和数据库之间的中间层建立连接。由于这些不同的选择,一个传统 DBMS 需要适合不同协议。但他们的职责基本相同,为调用者建立并记住连接状态,响应 SQL 命令,需要时返回数据与其他信息。在这个示例中,客户端与中间层建立连接,并将请求转发给 DBMS 中。
- 一旦收到 SQL, DBMS 为 SQL 命令分配一个计算线程,这个线程与客户端进行通信与输出,这是 DBMS 中 Process Manager (如图1.1) 的任务。这个阶段,数据库最重要的决定是 admission control (准入控制),系统是应该立即开始处理查询,还是延迟执行,直到有足够的系统资源可以用于此查询。这部分将在第二节讨论。
- 准入并分配线程控制后,查询开始进行。这是 Relational Query Processor (关系查询处理器,如图1.1)的任务。这组模块检查用户是否被授权运行查询,并将用户的SQL查询文本编译到内部查询计划中。编译后,执行计划交予计划执行器。计划执行器由一组“operators(算子)”(关系算法实现)组成,用于执行任何查询。算子包括连接、选择、投影、聚合、排序等,同时向该系统的较低层级请求数据记录(也就是在语法树上向孩子请求元组)。在示例中,是一个简单子集。这部分将在第四节讨论。
- 在查询计划的基础上,有多个算子向数据库请求数据。这些算子通过调用 DBMS 中管理数据读写操作的 Transctional Storage Manager (事务存储管理器,如图1.1)获得数据。存储系统包括一系列算法和数据结构来组织、管理和读写磁盘上的数据,像基础的结构表和索引等。还包括一个缓冲区管理模块,用来决定何时以及将什么数据从磁盘传输到内存缓冲中。回到示例,在访问数据中,查询必须调用事务管理模块以保证事物的 ACID 属性。[30](将在 5.1 节有更详细的讨论)。在获取数据之前,必须从锁管理器中先上锁,以确保并发时的正确执行。如果查询包含数据库的更新,他会与日志管理器进行交互,确保事务提交之后的持久性,和中止之后的完全 undo。在 5 节中,会更细节讨论存储和缓冲管理;在 6 节中,会介绍事务性一致性体系结构。
- 这时示例中的 SQL 已经开始访问数据记录,并准备用他们为客户端计算结果。调用方法,将控制返回查询执行器的算子,算子从数据库数据中编排元组的计算结果;结果元组生成之后,被放置在客户端通信管理器缓冲区中,并将交过返回给调用者。对于大型结果集,客户机通常会进行额外的调用,以便从查询中增量地获取更多数据,从而导致通过通信管理器、查询执行器和存储管理器进行多次迭代。在我们的简单示例中,在查询结束时,事务完成,连接关闭;这导致事务管理器清理事务的状态,流程管理器为查询释放任何控制结构,通信管理器清理连接的通信状态。
这个示例,虽然触及 RDBMS 中许多关键部分,但并非全部。图1.1右边部分的共享部分对一个完全功能的 DBMS 非常重要。catalog (目录)目录和内存管理器在任何事务期间(包括我们的示例查询)都作为实用程序调用。查询处理器在身份验证、解析和查询优化期间使用 catalog (目录)。内存管理器贯穿于整个 DBMS ,每当需要动态分配或释放内存时。图1.1最右边框中列出的其余模块是独立于任何特定查询运行的实用程序,使数据库作为一个整体保持良好和可靠。我们将在第7节中讨论这些共享组件和实用程序。
1.2 Scope and Overview
在论文的大部分内容中,重点是支持核心数据库功能的架构基础。论文不会对文献中广泛记载的数据库算法进行全面的回顾。论文会对现代dbms中出现的许多扩展进行了最少的讨论,其中大多数扩展提供了核心数据管理之外的功能,但不会显著改变系统架构。然而,在论文的各个部分中,论文会记录超出论文范围得有趣的主题,并提供额外阅读的指导。
论文首先对数据库系统的总体体系结构进行研究。任何服务器系统架构的第一个主题都是它的整体进程结构,论文在这方面探索了各种可行的替代方案,首先是针对单处理器机器,然后是针对当今可用的各种并行架构。对核心服务器系统体系结构的讨论适用于各种系统,但在很大程度上是DBMS设计的先驱。在此之后,讨论 DBMS 中更特定的组件。从系统的单个查询的视角开始,重点关注关系查询处理器。接下来,我们进入存储体系结构和事务性存储管理设计。最后,我们介绍了大多数 DBMSs 中存在的一些共享组件和实用程序,这些组件和实用程序在教科书中很少讨论。
2 Process Models
在设计任何多用户服务器时,需要对并发用户请求的执行以及如何将这些请求映射到操作系统进程或线程做出早期决策。这些决策对系统的软件架构、性能、可伸缩性和跨操作系统的可移植性都有深远的影响。在本节中,我们将研究 DBMS 进程模型的许多选择,这些模型可作为许多其他高并发服务器系统的模板。我们从一个简化的框架开始,假设对线程有良好的操作系统支持,我们最初的目标只是一个单处理器系统。然后,我们对这个简化的讨论进行扩展,以处理现代 DBMSs 如何实现其流程模型的现实问题。在第 3 节中,我们将讨论尽可能利用计算机集群以及多处理器和多核系统的技术。
下面的讨论依赖于这些定义:
-
一个 Operating System Process (操作系统进程) 由操作系统(OS)和一个带有私有地址空间进程的程序执行单元(一个控制线程)组成。为进程维护的状态包括操作系统资源句柄和安全上下文。这个程序执行单元由操作系统内核调度,每个进程都有自己唯一的地址空间。
-
一个 Operating System Thread (操作系统线程) 是一个操作系统程序执行单元,没有额外的私有操作系统上下文,也没有私有地址空间。每个操作系统线程都可以完全访问在同一个多线程操作系统进程中执行的其他线程的内存。线程执行由操作系统内核调度器调度,这些线程通常称为“内核线程”或k-线程。
-
一个 Lightweight Thread Package (轻量级线程包) 是一个应用程序级别的结构,它支持单个操作系统进程中有多个线程。与由操作系统调度的操作系统线程不同,轻量级线程由应用程序级别的线程调度程序调度。轻量级线程和内核线程的区别在于,轻量级线程是在用户空间中调度的,不需要内核调度器的参与或了解。用户空间调度器及其所有轻量级线程的组合在单个操作系统进程中运行,并且对操作系统调度器显示为单个执行线程。
与操作系统线程相比,轻量级线程具有更快的线程切换的优点,因为不需要进行操作系统内核模式切换来调度下一个线程。然而,轻量级线程的缺点是,任何阻塞操作(例如任何线程的同步I/O)都会阻塞进程中的所有线程。这会阻止其他线程在一个线程被阻塞等待操作系统资源时执行。轻量级线程包通过只发出异步(非阻塞)I/O请求和不调用任何可能阻塞的操作系统操作来避免这种情况。通常,轻量级线程提供了比基于OS进程或OS线程编写软件更困难的编程模型。(注:论文语境中的轻量级线程,可见2.2.1 DBMS Threads。我原本以为其实指的就是协程或者纤程,但实则有一定区别。但总之,它们无法使用多核,见3.5)
-
一些 DBMSs 实现了自己的轻量级线程(LWT)包。当DBMS、一般LWT和操作系统线程之间的区别对讨论不重要时,我们将这些线程称为 DBMS 线程和简单的线程。
-
***DBMS client (DBMS 客户端)***是一个软件组件,它实现了应用程序用来与DBMS通信的API。一些示例数据库访问api有JDBC、ODBC和OLE/DB。此外,还有各种各样的专有数据库访问API集。有些程序是使用嵌入式SQL编写的,这是一种将编程语言语句与数据库访问语句混合在一起的技术。它首先在IBM COBOL和PL/I中发布,后来在SQL/J中发布,SQL/J为Java实现了嵌入式SQL。嵌入式SQL由预处理器处理,预处理器将嵌入式SQL语句转换为对数据访问api的直接调用。无论客户机程序中使用什么语法,最终结果都是对DBMS数据访问api的一系列调用。对这些api的调用由DBMS客户端组件编组,并通过某种通信协议发送给DBMS。这些协议通常是专有的,通常没有文档记录。在过去,已经有一些标准化客户机到数据库通信协议的努力,其中Open Group DRDA可能是最著名的,但没有一个获得广泛采用。
-
一个***DBMS Worker (工作线程)***是DBMS中代表DBMS客户端工作的执行线程。在DBMS Worker 和DBMS客户端之间存在1:1的映射:这个DBMS Worker 处理来自单个DBMS客户机的所有SQL请求。worker 执行每个请求并将结果返回给客户端。在接下来的内容中,我们将研究商业DBMS将DBMS Worker映射到操作系统线程或进程的不同方法。这些差别是明显的,我们将它们称为 worker threads (工作线程) 或 worker process (工作进程)。否则,我们将它们简单地称为工作器或DBMS worker。
2.1 Uniprocessors and Lightweight Threads
在本小节中,我们将概述一个简化的DBMS过程模型分类法。很少有领先的 DBMSs 的架构与本节中描述的完全一样,但是这些材料构成了我们将更详细地讨论当前一代生产系统的基础。当今的每一个领先的数据库系统,其核心都是本文所介绍的至少一个模型的扩展或增强。
我们首先做两个简化的假设(我们将在随后的章节中放宽):
- OS thread support (操作系统线程支持):我们假设操作系统为我们提供了对内核线程的有效支持,并且一个进程可以有非常多的线程。我们还假设每个线程的内存开销很小,上下文切换开销也很小。这在今天的许多现代操作系统上都是正确的,但在大多数 DBMS 最初设计时却不一定不是正确的。由于那时的操作系统线程要么不可用,要么在某些平台上伸缩性差,因此许多 DBMSs 在实现时没有使用底层操作系统线程支持。
- Uniprocessor hardware (单处理器硬件):我们将假设我们正在为具有单个CPU的单个机器进行设计。考虑到多核系统的普遍性,这是一个不现实的假设,即使在低端也是如此。然而,这个假设将简化我们最初的讨论。
在这个简化的上下文中,DBMS有三个自然的过程模型选项。从最简单的到最复杂的,它们是:(1)the process per DBMS worker,(2)the thread per DBMS worker,(3)process pool。虽然这些模型都是简化的,但这三种模型都在今天的商业DBMS系统中使用。
2.1.1 Process per DBMS Worker
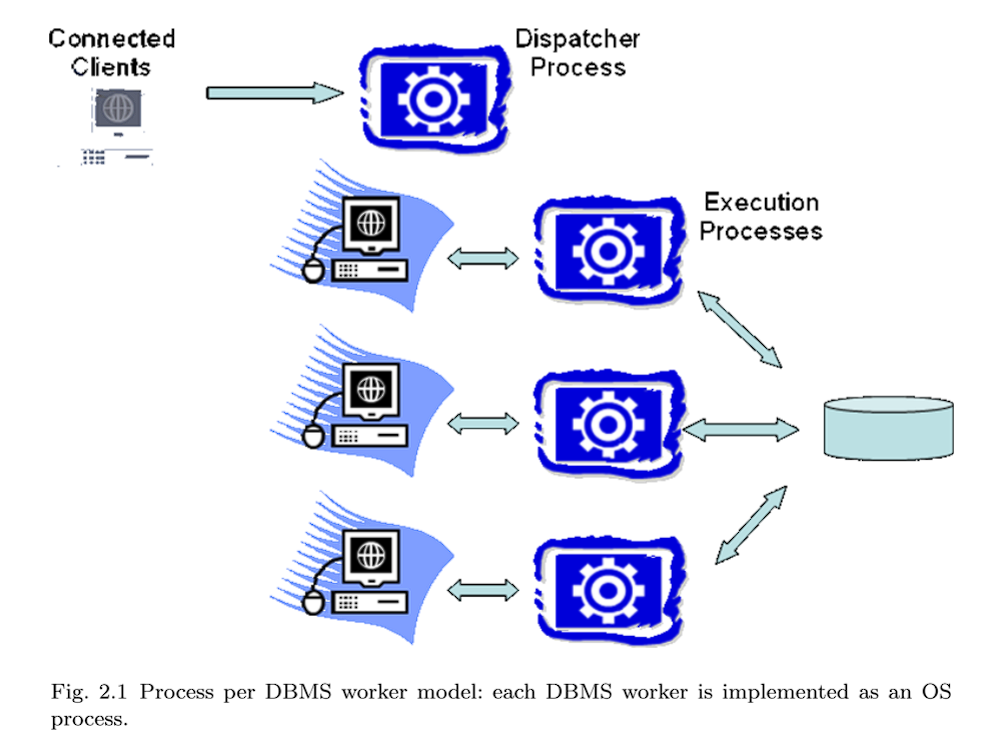
一个 DBMS worker 一个进程(图2.1)被早期的DBMS实现并使用,并且今天仍被许多商业系统所使用。这个模型相对容易实现,因为DBMS工作器直接映射到操作系统进程。操作系统调度器管理DBMS工作人员的分时,而DBMS程序员可以依靠操作系统的保护设施来隔离内存溢出等标准错误。此外,各种编程工具(如调试器和内存检查器)都非常适合此进程模型。使这个模型复杂化的是跨DBMS连接共享的内存数据结构,包括锁表和缓冲池(分别在第6.3节和第5.3节中详细讨论)。这些共享数据结构必须显式地分配在操作系统支持的共享内存中,这些内存可以跨所有DBMS进程访问。这需要操作系统支持(这是广泛可用的)和一些特殊的DBMS编码。在实践中,这个模型中需要大量使用共享内存,这降低了地址空间分离的一些优势,因为有很大一部分“interesting(有趣的)”内存是跨进程共享的。
在扩展到非常大量的并发连接方面,*process per DBMS worker (一个 DBMS worker一个进程)*不是最有吸引力的进程模型。伸缩问题的出现是因为进程比线程拥有更多的状态,因此会消耗更多的内存。进程切换需要切换安全上下文、内存管理器状态、文件和网络句柄表以及其他进程上下文。而这对于一个线程的切换来说,是不需要的。尽管如此,一个 DBMS worker一个进程的模型仍然很流行,并在IBM DB2、PostgreSQL和Oracle得到支持。
2.1.2 Thread per DBMS worker
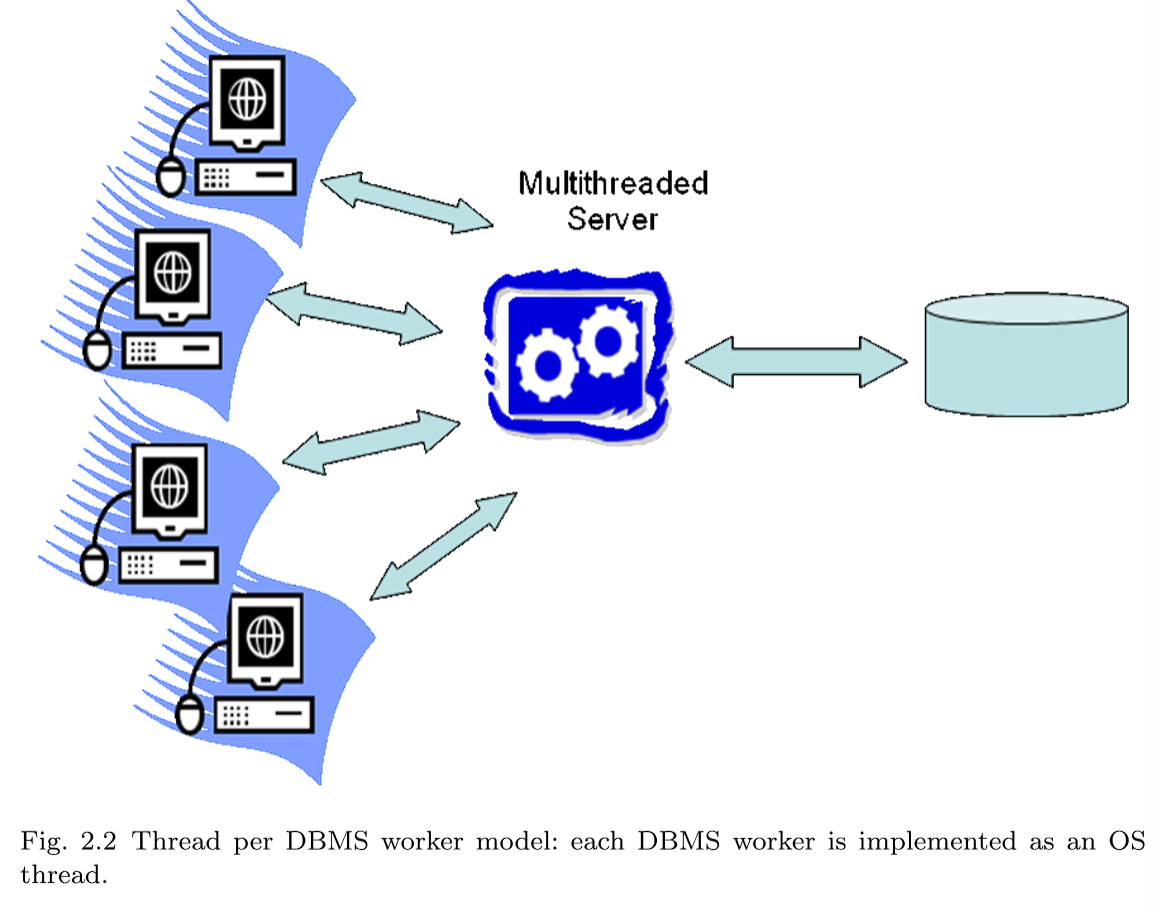
在每个DBMS工作线程模型(图2.2)中,单个多线程进程承载所有DBMS工作线程活动。一个调度线程 (或一小部分这样的线程)监听新的 DBMS 客户端连接。每个连接分配一个新线程。当每个客户端提交SQL请求时,请求完全由运行DBMS worker的相应线程执行。该线程在DBMS进程中运行,完成后,结果返回给客户端,线程在连接上等待来自同一客户端的下一个请求。
在这种体系结构中出现了常见的多线程编程挑战:操作系统不保护线程免受彼此的内存溢出和偏离指针的影响;调试是棘手的,特别是在竞争条件下;由于线程接口和多线程扩展的差异,软件很难跨操作系统移植。由于共享内存的广泛使用,the thread per DBMS worker的许多多编程挑战也存在于每个the process per DBMS worker中。
尽管近年来不同操作系统之间的线程API差异已经最小化,但平台之间的细微差异仍然会给调试和调优带来麻烦。忽略这些实现困难,每个DBMS工作线程模型可以很好地扩展到大量并发连接,并在一些当前一代的生产DBMS系统中使用,包括IBM DB2、Microsoft SQL Server、MySQL、Informix和Sybase。
2.1.3 Process Pool
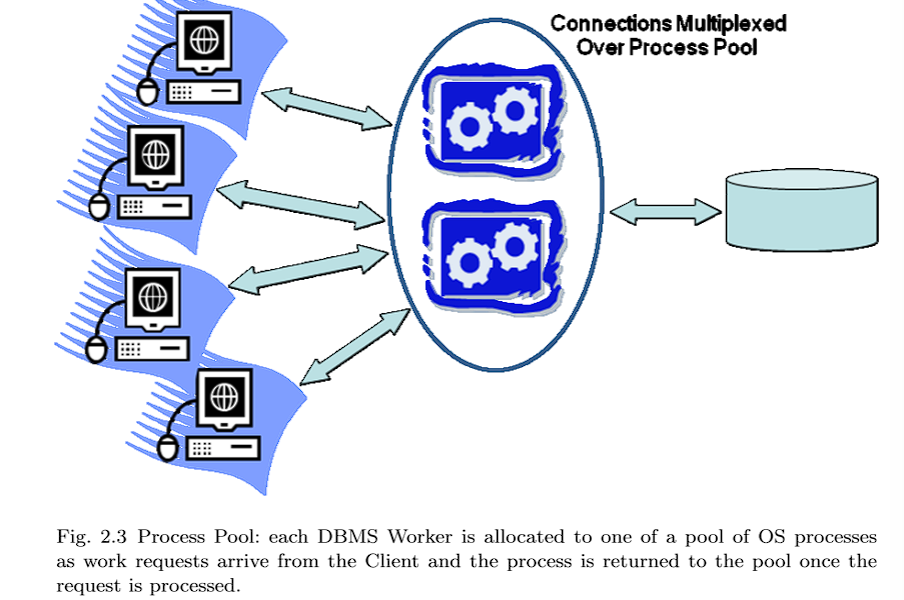
这个模型是 the process per DBMS worker 的一个变体。回想一下,其优点是实现简单,但是每个连接需要一个完整进程的内存开销是一个明显的缺点。使用进程池(图2.3),而不是为每个DBMS工作人员分配一个完整的进程,它们由进程池托管。中央进程保存所有DBMS客户端连接,并且当每个SQL请求来自客户端时,该请求被传递给进程池中的一个进程。SQL语句执行到完成,结果返回给数据库客户端,进程返回到池中,以分配给下一个请求。进程池的大小是有限的,而且通常是固定的。如果一个请求到达而所有进程都在处理其他请求,那么新请求必须等待一个进程空闲。
进程池具有每个DBMS工作进程的所有优点,但由于所需的进程数量要少得多,因此内存效率要高得多。进程池通常使用动态调整大小的进程池来实现,当大量并发请求到达时,进程池可能会隐式增长到某个最大数量。当请求负载较轻时,可以将进程池减少到更少的等待进程。与the thread per DBMS worker一样,目前使用的几个当前一代DBMS也支持进程池模型。
2.1.4 Shared Data and Process Boundaries
上面描述的所有模型都旨在尽可能独立地执行并发客户机请求。然而,完全的DBMS工作者独立性和隔离性是不可能的,因为它们操作相同的数据库。在 the thread per DBMS worker 模型中,所有线程在相同的地址空间中运行,数据共享很容易。在其他模型中,共享内存用于共享数据结构和状态。在所有这三种模型中,数据必须从DBMS移动到客户端。这意味着所有SQL请求都需要移到服务器进程中,返回到客户机的所有结果都需要移动至客户端。这是如何做到的呢?简短的回答是使用了各种缓冲区。我们在这里描述这些缓冲区,并简要讨论管理它们的策略。
Disk I/O buffers (磁盘I/O缓冲区):最常见的跨工作数据依赖关系是对共享数据存储的读取和写入。因此,DBMS worker之间的I/O交互是常见的。有两个单独的磁盘I/O场景需要考虑:(1)数据库请求和(2)日志请求。
-
Database I/O Requests: The Buffer Pool (数据库I/O请求:缓冲池):所有持久化数据库数据都通过DBMS缓冲池进行暂存(第5.3节)。在另外两种模型中,缓冲池分配在所有进程可用的共享内存中。这三种DBMS模型的最终结果都是缓冲池是对所有线程/进程可用的巨大的共享数据结构。当一个线程需要从数据库中读入一个页面时,它会生成一个指定磁盘地址的I/O请求,并生成一个句柄,指向缓冲池中可以放置结果的空闲内存位置(帧)。缓冲池将在4.3节中详细讨论。
-
Log I/O Requests: The Log Tail. (日志 I/O 请求:日志追踪):数据库日志(章节6.4)是存储在一个或多个磁盘上的条目数组。日志条目在事务处理时产生,他们被存储在一个内存队列中,按照 FIFO 的顺序定期刷入日志磁盘中。这个队列通常称为日志追踪。在许多系统中,一个单独的进程或线程负责定期将日志尾刷新到磁盘。
对于the thread per DBMS worker,日志尾只是一个堆驻留数据结构。在另外两个模型中,两种不同的设计选择是常见的。在一种方法中,一个单独的进程管理日志。日志记录通过共享内存或任何其他有效的进程间通信协议传递给日志管理器。在另一种方法中,在共享内存中分配日志尾,其方式与上面处理缓冲池的方式大致相同。关键的一点是,执行数据库客户机请求的所有线程和/或进程都需要能够请求写入日志记录并刷新日志尾。
日志刷新的一种重要类型是提交事务刷新。在提交日志记录刷新到日志设备之前,事务不能报告为成功提交。这意味着客户端代码要等待,直到提交日志记录被刷新,而DBMS服务器代码也必须保持所有资源(例如锁),直到那个时间。日志刷新请求可以延迟一段时间,以允许在单个I/O请求中批量提交记录(“组提交”)。
Client communication buffers (客户端通信缓冲区):SQL通常用于“拉”模型:客户端通过重复发出SQL FETCH请求从查询游标中消费结果元组,每个请求检索一个或多个元组。大多数dbms尝试在FETCH请求流之前工作,以便在客户端请求之前对结果进行排队。
为了支持这种预取行为,DBMS worker可以使用客户端通信套接字作为它生成的元组的队列。更复杂的方式是实现客户端侧的游标缓存并使用DBMS 客户端存储很可能在之后不久会被拉取的结果,而不是依赖 OS 的通信缓存。
Lock table(锁表):锁表由所有DBMS worker共享,并由锁管理器(章节6.3)使用来实现数据库锁定语义。共享锁表的技术与缓冲池的技术相同,这些相同的技术可用于支持DBMS实现所需的任何其他共享数据结构。
2.2 DBMS Threads
前一节提供了对DBMS过程模型的简化描述。我们假设了高性能操作系统线程的可用性,并且DBMS只针对单处理器系统。在本节的其余部分中,我们将放宽第一个假设,并描述对DBMS实现的影响。下一节将讨论多处理和并行性。
2.2.1 DBMS Threads
今天的大多数 DBMSs 都起源于20世纪70年代的研究系统和20世纪80年代的商业化努力。在构建原始数据库系统时,我们今天认为理所当然的标准操作系统特性通常对当时的DBMS开发人员是不可用的。高效、大规模的操作系统线程支持可能是其中最重要的。直到20世纪90年代,操作系统线程才被广泛实现,即使存在,实现也有很大差异。即使在今天,一些操作系统线程实现也不能很好地扩展到支持所有DBMS工作负载。[31,48,93,94]
因此,出于历史原因、移植性和可伸缩性的原因,许多广泛使用的DBMS在其实现中不依赖于操作系统线程。(注:这句话对于2025年的今天可能并不适用了。)有些则完全避免使用线程,并使用the process per DBMS worker或进程池模型。对于那些没有很好的内核线程实现的操作系统,需要一个解决方案来实现剩余的进程模型选择,即the process per DBMS worker。几个领先的DBMSs采用了一种解决此问题的方法是实现它们自己专用的,轻量级的线程包。这些轻量级线程或DBMS线程取代了前一节中描述的操作系统线程的角色。每个DBMS线程都被编程来管理自己的状态,通过非阻塞的异步接口执行所有潜在的阻塞操作(例如,I/O),并经常将控制权交给调度例程,调度例程在这些任务之间进行调度。
轻量级线程是中以回顾的方式讨论的一个老概念,并且广泛用于用户界面的事件循环编程。在最近的OS文献中,这个概念经常被重新审视。这种架构提供了快速的任务切换和易于移植,但代价是在DBMS中复制大量的操作系统逻辑(任务切换、线程状态管理、调度等)。[49,31,48,93,94,86]
2.3 Standard Practice
在当今领先的 DBMSs 中,我们可以找到2.1节中介绍的所有三种体系结构的代表,以及它们的一些有趣的变化。在这个维度中,IBM DB2可能是最有趣的例子,因为它支持四种不同的处理模型。在具有良好线程支持的OSs上,DB2默认使用 the thread per DBMS worker 并且可选支持在线程池上多路复用DBMS worker线程。在没有可伸缩支持的OSs上,DB2默认使用 the process per DBMS worker 并且可选支持在一个进程池上多路复用 DBMS worker。
总结IBM DB2、MySQL、Oracle、PostgreSQL和Microsoft SQL Server支持的进程模型:
Process per DBMS worker:
这是最直接的流程模型,至今仍被大量使用。在不支持高质量、可扩展的操作系统线程的操作系统上,DB2默认the process per DBMS worker,而在支持高质量、可扩展的操作系统线程的操作系统上,DB2默认the thread per DBMS worker。这也是 Oracle 默认的处理模型。Oracle还支持下面描述的进程池作为可选模型。只有PostgreSQL在所有支持的操作系统上都只运行the process per DBMS worker。
Thread per DBMS worker:
这是一个有效的模型,目前有两个主要的变体。
- OS thread per DBMS worker:在具有良好的操作系统线程支持的系统上运行时,IBM DB2默认使用此模型,MySQL也使用此模型。
- DBMS thread per DBMS worker:在这个模型中,DBMS工作程序由操作系统进程或操作系统线程上的轻量级线程调度器调度。该模型避免了任何潜在的操作系统调度器伸缩或性能问题,但代价是高昂的实现成本、较差的开发工具支持以及DBMS供应商的大量长期软件维护成本。这个模型有两个主要的子类别:
- 在操作系统进程上调度的DBMS线程:轻量级线程调度程序由一个或多个操作系统进程托管。Sybase和Informix都支持这个模型。当前所有使用此模型的系统都实现了一个DBMS线程调度器,该调度器在多个操作系统进程上调度DBMS工作程序,以利用多个处理器。然而,并非所有使用此模型的DBMS都实现了线程迁移:将现有DBMS线程重新分配给不同的操作系统进程的能力(例如,为了负载平衡)。
- 在OS线程上调度的DBMS线程:Microsoft SQL Server将此模型作为非默认选项支持(默认是DBMS工作线程在下面描述的线程池上多路复用)。这个SQL Server选项,称为Fibers(纤程),在一些高规模的事务处理基准测试中使用,但除此之外,很少使用。
Process/thread pool:
在这个模型中,DBMS工作器在一个进程池中进行多路复用。随着操作系统线程支持的改进,这个模型的第二个变体基于线程池而不是进程池出现了。在后一种模型中,DBMS工作线程在操作系统线程池中复用:
- DBMS workers multiplexed over a process pool(DBMS workers在一个进程池上多路复用):这个模型比每个DBMS工作进程的内存效率高得多,很容易移植到没有良好的操作系统线程支持的操作系统上,并且可以很好地扩展到大量用户。这是Oracle支持的可选模型,也是他们为具有大量并发连接用户的系统推荐的模型。Oracle默认的模型是 the process per DBMS worker。Oracle支持的两个选项都很容易在它们所针对的大量不同的操作系统上得到支持(Oracle一度支持超过80个目标操作系统)。
- DBMS workers multiplexed over a thread pool(DBMS workers 在线程池上多路复用):Microsoft SQL Server默认采用这种模式,并且超过99%的SQL Server安装都以这种方式运行。如上所述,为了有效地支持成千上万并发连接的用户,SQL Server可选择支持在操作系统线程上调度的DBMS线程。
正如我们在下一节中讨论的那样,当前一代的大多数商业 DBMSs 都支持查询内并行性:在多个处理器上并行执行单个查询的全部或部分的能力。就本节讨论的目的而言,查询内并行是多个DBMS worker临时赋给对单个SQL。除了单个客户端连接可能有多个DBMS工作器代表其执行之外,底层处理模型不会受到此特性的任何影响。
2.4 Admission Control
我们以一个与支持多个并发请求相关的剩余问题结束本节。随着任何多用户系统中工作负载的增加,吞吐量将增加到某个最大值。超过这个点,当系统开始颠簸时,它(应该指性能)将开始急剧减少。与操作系统一样,抖动通常是内存压力的结果:DBMS 不能将数据库页面的“工作集”保存在缓冲池中,并且花费大量时间来替换页面。在 DBMSs 中,对于排序和散列连接等查询处理技术来说,这尤其是个问题,因为它们往往会消耗大量的主内存。在某些情况下,DBMS抖动也可能由于锁的争用而发生:事务不断地彼此死锁,需要回滚并重新启动。因此,任何好的多用户系统都有一个准入控制策略,除非有足够的DBMS资源可用,否则不接受新的工作。有了一个好的准入控制器,系统在过载情况下将显示出优雅的降级:事务延迟将与到达率成比例地增加,但吞吐量将保持在峰值。[2]
DBMS的准入控制可以分为两层。首先,可以在调度程序进程中设置一个简单的准入控制策略,以确保客户端连接数保持在阈值以下。这有助于防止过度消耗基本资源,如网络连接。在一些 DBMSs 中,不提供这种控制,假设它是由多层系统的另一层处理的,例如,应用程序服务器、事务处理监视器或web服务器。
第二层准入控制必须直接在核心DBMS关系查询处理器中实现。此执行许可控制器在查询被解析和优化后运行,并确定查询是延迟执行、在资源较少的情况下开始执行,还是在没有额外约束的情况下开始执行。来自查询优化器的信息可以帮助执行许可控制器,这些信息可以估计查询所需的资源和当前系统资源的可用性。特别是,优化器的查询计划可以指明(1)查询将访问的磁盘设备的随机顺序I/O操作,(2)基于查询计划中的算子和处理元组的数量估计CPU负载,最重要的是(3)估计的内存占用查询数据结构,包括空间排序和散列大型期间输入连接和查询执行其他任务。如上所述,最后一个指标通常是准入控制器的关键,因为内存压力通常是导致抖动的主要原因。因此许多DBMS使用内存占用和活动DBMS工作器的数量作为准入控制的主要标准。
2.5 Discussion and Additional Material
处理模型的选择对DBMS的扩展和可移植性有很大的影响。因此,三个更广泛使用的商业系统在其产品线中都支持一个以上的处理模型。从工程的角度来看,在所有操作系统和所有扩展级别上使用单一流程模型显然要简单得多。但是,由于使用模式的巨大多样性和目标操作系统的不一致性,这三个dbms都选择支持多个模型。
展望未来,近年来,由于硬件瓶颈的变化以及Internet上工作负载的规模和可变性,人们对服务器系统的新流程模型产生了浓厚的兴趣。这些设计中出现的一个主题是将服务器系统分解为一组独立调度的“引擎”,并在这些引擎之间异步地批量传递消息。这类似于上面的“进程池”模型,其中工作单元跨多个请求重用。最近这项研究的主要新颖之处在于,它以一种比以前更狭窄的任务特定方式打破了工作的功能颗粒。这导致了worker和SQL请求之间的多对多关系——单个查询通过多个worker中的活动进行处理,每个worker为许多SQL请求执行自己的专用任务。这种架构支持更灵活的调度选择——例如,它允许在允许单个工作者完成许多查询任务(可能提高整体系统吞吐量)或允许查询在多个工作者之间进行进展(以改善该查询的延迟)之间进行动态权衡。在某些情况下,这已被证明在处理器缓存局部性方面具有优势,并且能够在硬件缓存丢失期间保持CPU繁忙而不是空闲。[31,35,48,93,94]
StagedDB研究项目代表了在DBMS上下文中对这一思想的进一步研究,这是进行额外阅读的一个很好的起点。
3 Parallel Architecture:Process and Memory Coordination
并行硬件在现代服务器中是一个事实,并且有各种各样的配置。在本节中,我们总结了标准DBMS术语,并讨论了每个术语中的进程模型和内存协调问题。[87]
3.1 Shared Memory
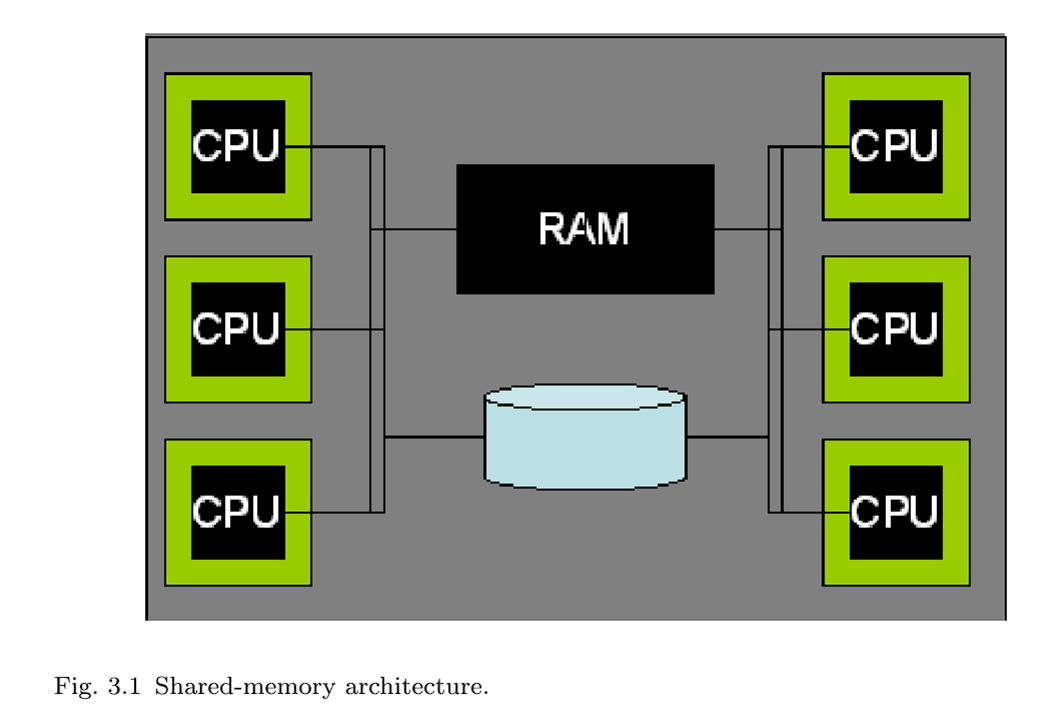
在共享内存并行系统(图3.1)中,所有处理器都可以以大致相同的性能访问相同的RAM和磁盘。这种架构在今天是相当标准的——大多数服务器硬件都有 2 到 8 个处理器。(注:现在的服务器CPU能有几十甚至上百个核,而且根据架构不同,核与核之间的性能不一定完全相同。)高端机器可以配备数十个处理器,但相对于所提供的处理资源,它们的售价往往高出很多。高度并行的共享内存机器是硬件行业中仅存的“摇钱树”之一,在高端在线事务处理应用程序中被大量使用。与管理系统的成本相比,服务器硬件的成本通常显得微不足道,所以购买少量的大型、昂贵的系统的代价(以降低管理成本),有时是可接受的折中。
多核处理器支持单个芯片上的多个处理核心,并共享一些基础设施,如缓存和内存总线。这使得它们在编程模型方面与共享内存架构非常相似。如今,几乎所有严肃的数据库部署都涉及多个处理器,每个处理器都有多个CPU。DBMS体系结构需要能够充分利用这种潜在的并行性。幸运的是,第2节中描述的所有三种DBMS体系结构都可以在现代共享内存硬件体系结构上运行良好。
共享内存机器的进程模型非常自然地遵循单处理器方法。事实上,大多数数据库系统都是从最初的单处理器实现发展到共享内存实现的。在共享内存机器上,操作系统通常支持跨处理器透明地分配工作(进程或线程),并且所有人都可以访问共享数据结构。所有三种模型都能在这些系统上运行良好,并支持并行执行多个独立的SQL请求。主要的挑战是修改查询执行层,以利用跨多个cpu并行处理单个查询的能力;我们将此推迟到第5节。
3.2 Shared-Nothing
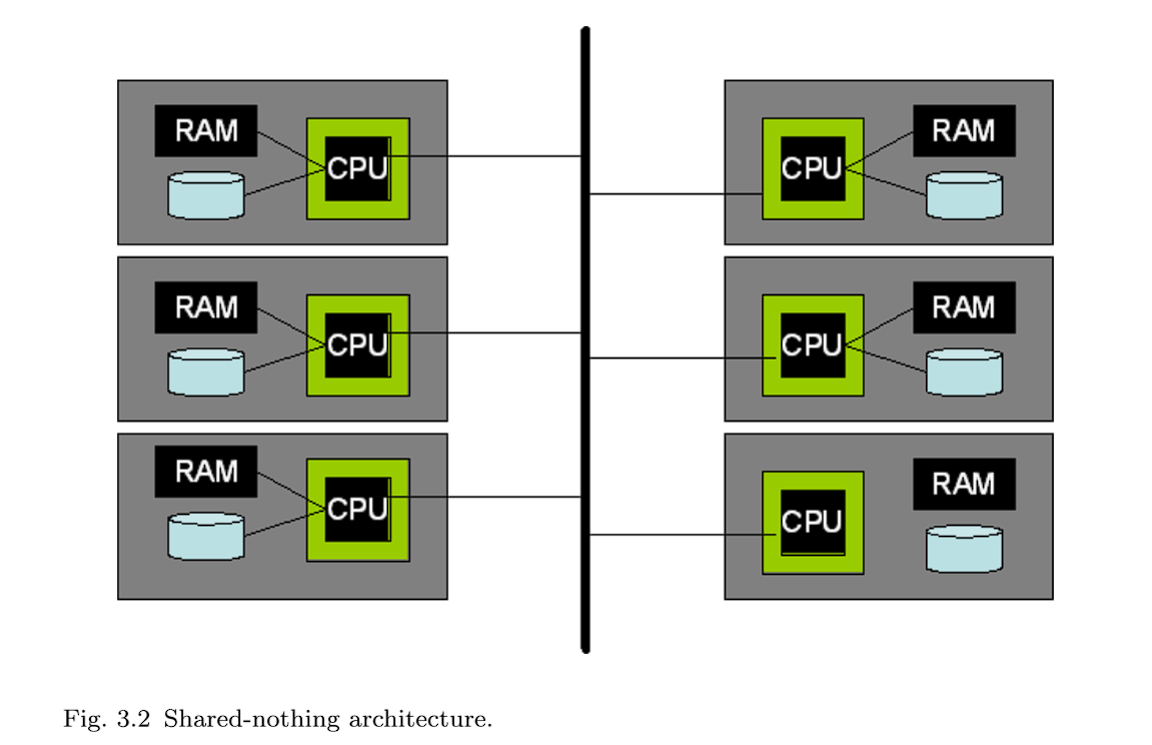
无共享并行系统(图3.2)由一组独立的机器组成,这些机器通过高速网络互连进行通信,或者更频繁地通过商业网络组件进行通信。给定的系统无法直接访问另一个系统的内存或磁盘。
无共享系统不提供硬件共享抽象,将各种机器的协调完全交给DBMS处理。DBMSs 用来支持这些集群的最常用技术是在集群中的每台机器或节点上运行它们的标准处理模型。每个节点都能够接受客户端SQL请求、访问必要的元数据、编译SQL请求和执行数据访问,就像在上面描述的单个共享内存系统上一样。主要区别在于集群中的每个系统只存储一部分数据。请求被发送到集群的其他成员,而不是仅针对本地数据运行它们接收到的查询,所有涉及的机器都对它们存储的数据并行执行查询。这些表分布在集群中的多个系统上,使用水平数据分区允许每个处理器独立于其他处理器执行。
数据库中的每个元组都被分配给单独的机器,因此每个表都被“水平”切片并分布在机器上。典型的数据分区方案包括基于元组属性的哈希分区、基于元组属性的范围分区、轮循(round-robin)和混合(基于范围和基于哈希的组合)。每台单独的机器负责访问、锁定和记录本地磁盘上的数据。在查询执行期间,查询优化器选择如何跨机器水平地重新划分表和中间结果以满足查询,并为每台机器分配工作的逻辑分区。不同机器上的查询执行器相互传送数据请求和元组,但不需要传输任何线程状态或其他低级信息。由于数据库元组的这种基于值的分区,在这些系统中只需要很少的协调。但是,为了获得良好的性能,需要对数据进行良好的分区。这给数据库管理员(DBA)和查询处理器带来了很大的负担,他们需要智能地布局表,以便更好地对工作负载进行分区。[30]
此外,部分失效(partial failure)是必须在shared-nothing系统中进行管理。在一个shared-memory 系统中,一个处理器的故障通过会导致整个机器的故障,进而导致整个 DBMS 故障。在无共享系统中,单个节点的故障不一定会影响集群中的其他节点。但是它肯定会影响DBMS的整体行为,因为故障节点承载了数据库中的一部分数据。在这种情况下,至少有三种可能的方法。第一种方法是在任何节点发生故障时关闭所有节点;这实际上模拟了共享内存系统中可能发生的情况。第二种方法被IBM Informix称为“数据跳过”,它允许在任何正常运行的节点上执行查询,“跳过”故障节点上的数据。这在数据可用性比结果完整性更重要的场景中很有用。但是,“尽力而为”的结果没有定义良好的语义,并且对于许多工作负载来说,这不是一个有用的选择—特别是因为DBMS经常被用作多层系统中的“记录存储库”,并且可用性与一致性的权衡往往在更高的层中完成(通常在应用程序服务器中)。第三种方法是采用冗余方案,从完全数据库故障转移(需要双倍数量的机器和软件许可证)到细粒度冗余,如链式集群。在后一种技术中,元组副本分布在集群中的多个节点上。链式集群相对于更简单的方案的优势在于(a)与原始方案相比,它需要更少的机器来保证可用性(b)当一个节点发生故障时,系统负载会相当均匀地分布在剩余的节点上:剩下的n−1个节点每个都完成了原始工作的n/(n−1),并且随着节点故障,这种形式的性能线性下降会继续下去。在实践中,大多数当前一代的商业系统都处于中间位置,既不像完全数据库(full database)冗余那样粗粒度,也不像链式集群那样细粒度。[43]
shared-nothing架构在今天相当普遍,并且具有无与伦比的可伸缩性和成本特征。它主要用于极端高端,通常用于决策支持应用程序和数据仓库。在一个有趣的硬件体系结构组合中,无共享集群通常由许多节点组成,每个节点都是一个共享内存多处理器。
3.3 Shared-Disk
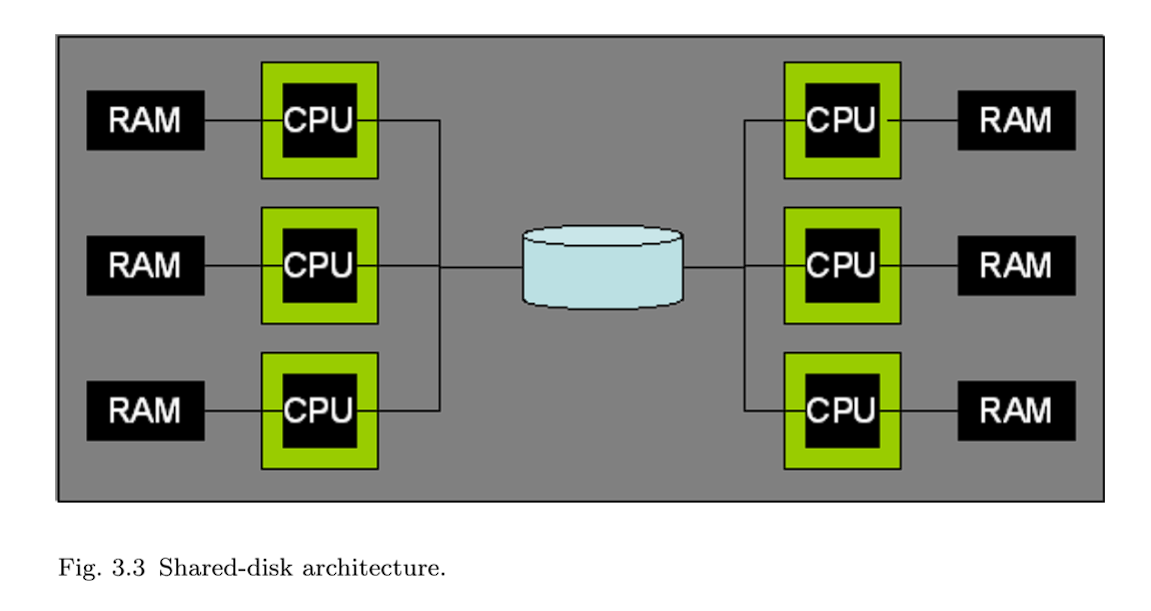
在shared-disk并行系统(图3.3)中,所有处理器都可以以相同的性能访问磁盘,但不能访问彼此的RAM。这种体系结构非常常见,有两个突出的例子是Oracle RAC和DB2 for zSeries SYSPLEX。近年来,随着存储区域网络(SAN)的日益普及,shared-disk变得越来越普遍。SAN允许一个或多个主机系统挂载一个或多个逻辑磁盘,从而易于创建共享磁盘配置。
与shared-nothing系统相比,shared-disk的一个潜在优势是其更低的管理成本。共享磁盘系统的 DBAs 不必为了实现并行性而考虑跨机器分区表。但是非常大的数据库通常仍然需要分区,因此,在这种规模下,差异变得不那么明显。共享磁盘体系结构的另一个引人注目的特性是,单个DBMS处理节点的故障不会影响其他节点访问整个数据库的能力。这与作为一个整体发生故障的共享内存系统和在节点发生故障时至少失去对某些数据的访问的无共享系统形成对比(除非使用了其他数据冗余方案)。然而,即使有这些优点,共享磁盘系统仍然容易受到一些单点故障的影响。如果数据在到达存储子系统之前由于硬件或软件故障而损坏或损坏,那么系统中的所有节点将只能访问这个损坏的页面。如果存储子系统使用RAID或其他数据冗余技术,损坏的页面将被冗余存储,但在所有副本中仍然损坏。
由于在共享磁盘系统中不需要对数据进行分区,因此可以将数据复制到RAM中并在多台机器上进行修改。与共享内存系统不同,没有自然的内存位置来协调这种数据共享—每台机器都有自己的本地内存用于锁和缓冲池页面。因此,需要在机器之间明确地协调数据共享。共享磁盘系统依赖于分布式锁管理器功能和缓存一致性协议来管理分布式缓冲池。这些都是复杂的软件组件,对于有大量争用的工作负载来说可能是瓶颈。有些系统(如IBM zSeries SYSPLEX)在硬件子系统中实现锁管理器。[8]
3.4 NUMA
Non-Uniform Memory Access (NUMA) 非一致内存访问系统在具有独立内存的系统集群上提供共享内存编程模型。集群中的每个系统都可以快速访问自己的本地内存,而跨高速集群互连的远程内存访问有些延迟。架构的名称来自于内存访问时间的不一致性。
NUMA硬件架构是介于shared-nothing和shared-memory系统之间的一个有趣的中间地带。它们比shared-nothing的集群更容易编程,并且通过避免共享争用点(如共享内存总线),可以扩展到比共享内存系统更多的处理器。
NUMA集群在商业上还没有取得广泛的成功,但NUMA设计概念已被采用的一个领域是共享内存多处理器(第3.1节)。随着共享内存多处理器扩展到更大的处理器数量,它们在内存体系结构中显示出越来越多的不一致性。通常,大型共享内存多处理器的内存被分成几个部分,每个部分与系统中处理器的一个小子集相关联。内存和cpu的每个组合子集通常称为pod。每个处理器访问本地pod内存的速度比远程pod内存略快。这种NUMA设计模式的使用允许共享内存系统扩展到非常多的处理器。因此,NUMA共享内存多处理器现在非常普遍,而NUMA集群从未获得任何重要的市场份额。
DBMSs 可以在NUMA共享内存系统上运行的一种方法是忽略内存访问的非一致性。如果不均匀性很小,这种方法是可以接受的。当近内存访问时间与远内存访问时间之比超过1.5:1到2:1的范围时,DBMS需要进行优化以避免严重的内存访问瓶颈。这些优化有多种形式,但都遵循相同的基本方法:(a)当分配内存供处理器使用时,使用该处理器的本地内存(避免使用远内存)。(b)如果可能的话,确保给定的DBMS工作器总是被调度在它之前所在的同一硬件处理器上。这种组合允许DBMS工作负载在具有内存访问时间不均匀性的高规模共享内存系统上良好运行。
尽管NUMA集群几乎消失了,但是编程模型和优化技术对当前一代DBMS系统仍然很重要,因为许多大规模共享内存系统在内存访问性能上存在显著的不均匀性。
3.5 DBMS Threads and Multi-processors
当我们从2.1节中删除最后一个简化假设(单处理器硬件)时,使用DBMS线程实现的the thread per DBMS worker产生的一个潜在问题立即变得明显起来。2.2.1节中描述的轻量级DBMS线程包的自然实现是所有线程在单个操作系统进程中运行。不幸的是,单个进程一次只能在一个处理器上执行。因此,在多处理器系统上,DBMS一次只使用一个处理器,而将系统的其余部分闲置。早期的Sybase SQL Server架构遭受了这种限制。随着共享内存多处理器在90年代早期变得越来越流行,Sybase迅速对体系结构进行了修改,以利用多个操作系统进程。
当在多个进程中运行DBMS线程时,有时一个进程有大量的工作,而其他进程(因此处理器)是空闲的。要使该模型在这些情况下正常工作,DBMSs必须在进程之间实现线程迁移。IBM Informix从6.0版本开始在这方面做得非常出色。
当将DBMS线程映射到多个操作系统进程时,需要决定使用多少操作系统进程,如何将DBMS线程分配给操作系统线程,以及如何跨多个操作系统进程进行分布。一个好的经验法则是每个物理处理器有一个进程。这最大化了硬件中固有的物理并行性,同时最小化了每个进程的内存开销。
3.6 Standard Practice
关于对并行性的支持,趋势与上一节类似:大多数主要的 DBMSs 都支持多个并行性模型。由于共享内存系统(SMPs、多核系统以及两者的组合)在商业上的流行,所有主要的DBMS供应商都很好地支持共享内存并行。在多节点集群并行中,我们开始看到支持上的分歧,其中广泛的设计选择是shared-nothing和shared-disk。
- shared-memory:所有主要的商业DBMS提供商都支持共享内存并行性,包括:IBM DB2、Oracle和Microsoft SQL Server。
- shared-nothing:此模型由IBM DB2、Informix、Tandem和NCR Teradata等支持;Green-plum提供了一个自定义版本的PostgreSQL,它支持shared-nothing并行。
- shared-disk:该模型由Oracle RAC、RDB(由Oracle从Digital Equipment Corp.收购)和IBM DB2 for zSeries等支持。
IBM销售多种不同的DBMS产品,并选择在一些产品中实现shared-disk支持,而在另一些产品中shared-nothing。到目前为止,没有一个领先的商业系统在一个代码库中同时支持shared-nothing和shared-disk;Microsoft SQL Server都没有实现。
3.7 Discussion and Additional Material
上面的设计代表了在各种服务器系统中使用的硬件/软件体系结构模型的选择。虽然它们主要是在dbms中首创的,但这些想法在其他数据密集型领域也越来越流行,包括低层可编程数据处理后端,如Map-Reduce,它正在增加各种自定义数据分析任务的用户。然而,即使这些想法正在更广泛地影响计算,在数据库系统的并行性设计中也出现了新的问题。[12]
在接下来的十年中,并行软件架构面临的一个关键挑战来自于开发新一代“多核”架构的愿望,这些架构来自处理器供应商。这些设备将引入一个新的硬件设计点,在单个芯片上有数十、数百甚至数千个处理单元,通过高速片上网络进行通信,但在访问片外存储器和磁盘方面保留了许多现有的瓶颈。这将导致磁盘和处理器之间的内存路径出现新的不平衡和瓶颈,这几乎肯定需要重新检查DBMS体系结构,以满足硬件的性能潜力。
在面向服务的计算领域,在更“macro(宏观)”的范围内,某种程度上相关的架构转变正在被预见。这里的想法是,拥有数万台计算机的大型数据中心将为用户托管处理(硬件和软件)。在这种规模下,只有高度自动化的应用程序和服务器管理才能负担得起。没有任何管理任务可以随着服务器数量的增加而扩展。而且,由于通常使用不太可靠的商用服务器,并且故障更常见,因此需要完全自动化地从常见故障中恢复。在大规模的服务中,每天都会出现磁盘故障,每周会出现几个服务器故障。在这种环境中,管理数据库备份通常由存储在不同磁盘上的不同服务器上维护的整个数据库的冗余在线副本取代。根据数据的值(value,或者翻译成价值?),冗余副本甚至可以存储在不同的数据中心中。自动脱机备份仍可用于从应用程序、管理或用户错误中恢复。但是,从大多数常见错误和故障中恢复是快速故障转移到冗余在线副本。冗余可以通过多种方式实现:(a)数据存储级的复制(存储区域网络);(b)数据库存储引擎级别的数据复制(如7.4节所述);(c)查询处理器对查询的冗余执行(第6节);(d)冗余的数据库请求在客户端软件级别自动生成(例如,由web服务器或应用服务器)。
在更解耦的级别上,在实践中,将具有DBMS功能的多个服务器分层部署是非常常见的,目的是尽量减少对“DBMS of record”的I/O请求率。这些模式包括用于SQL查询的各种形式的中间层数据库缓存,包括专用的主存数据库,如Oracle TimesTen,以及配置用于此目的的更传统的数据库。在部署堆栈的上层,可以配置许多面向对象的应用程序服务器体系结构,支持诸如Enterprise Java Beans之类的编程模型,以便与DBMS一起对应用程序对象进行事务性缓存。然而,这些不同方案的选择、设置和管理仍然是非标准的和复杂的,而优雅的普遍认可的模型仍然是难以捉摸的。[55]
4 Relational Query Processor
前几节强调了DBMS中的宏观体系结构设计问题。现在我们开始以更精细的方式讨论设计,依次处理每个主要的DBMS组件。根据我们在1.1节中的讨论,我们将从系统的顶部开始,从查询处理器开始,然后在随后的部分中向下讨论存储管理、事务和实用程序。
关系查询处理器接受声明性SQL语句,对其进行验证,将其优化为过程性数据流执行计划,然后(在admission control准入控制下)代表客户机程序执行该数据流程序。然后,客户端程序获取(“提取”)结果元组,通常是一次一个或小批量地获取。关系查询处理器的主要组件如图1.1所示。在本节中,我们将关注查询处理器和存储管理器访问方法的一些非事务性方面。一般来说,关系查询处理可以看作是单用户、单线程的任务。并发控制由系统的较低层透明地管理,如第5节所述。这条规则的唯一例外是,当DBMS在操作缓冲池页面时,必须显式地“固定”和“解固定”缓冲池页面,以便它们在短暂的关键操作期间留在内存中,我们将在4.4.5节中讨论。
在本节中,我们将重点讨论常见的SQL命令:数据操作语言(DML)语句,包括SELECT、INSERT、UPDATE和DELETE。数据定义语言(DDL)语句,如CREATE TABLE和CREATE INDEX,通常不由查询优化器处理。这些语句通常在静态DBMS逻辑中通过显式调用存储引擎和目录管理器(见6.1节)实现。一些产品也开始优化DDL语句的一小部分,我们预计这一趋势将继续下去。
4.1 Query Parsing and Authorization
给定一个SQL语句,SQL Parser的主要任务是:(1)检查查询是否被正确指定,(2)解析名称和引用,(3)将查询转换为优化器使用的内部格式,以及(4)验证用户是否被授权执行查询。有些 DBMSs 将部分或全部安全检查推迟到执行时进行,但是,即使在这些系统中,解析器仍然负责收集执行时安全检查所需的数据。
给定一个SQL查询,解析器首先考虑FROM子句中的每个表引用。它将表名规范化为server.database.schema.table格式的完全限定名。这也被称为四部分命名。不支持跨多个服务器查询的系统只需要规范化到database.schema。对于只支持一个数据库的DBMS系统可以规范化为schema.table。这种规范化是必需的,因为用户具有上下文相关的默认值。有些系统支持一个表的多个名称,称为表别名,这些名称也必须用完全限定的表名称替换。
规范化表名之后,查询处理器调用 catalog manager (目录管理器)来检查表是否已在系统编目中注册。在此步骤中,它还可以在内部查询数据结构中缓存关于表的元数据。然后,根据表的信息,它使用编目来确保属性引用是正确的。属性的数据类型用于驱动重载函数表达式、比较运算符和常量表达式的消歧逻辑。例如,考虑表达式(EMP.salary * 1.15) < 75000。乘法函数和比较运算符的代码以及假定的数据类型和字符串“1.15”和“75000”的内部格式将取决于empp .salary属性的数据类型。该数据类型可以是整数、浮点数或“货币”值。还应用了其他标准SQL语法检查,包括元组变量的一致性使用、通过集合操作符(UNION/INTERSECT/EXCEPT)组合的表的兼容性、聚合查询的SELECT列表中属性的使用、子查询的嵌套等等。
如果查询解析成功,下一个阶段是授权检查,以确保用户对查询中引用的表、用户定义函数或其他对象具有适当的权限(SELECT/DELETE/INSERT/UPDATE)。有些系统在语句解析阶段执行完整的授权检查。然而,这并不总是可能的。例如,支持行级安全性的系统在执行之前不能进行完整的安全性检查,因为安全性检查可能依赖于数据值。即使理论上可以在编译时静态验证授权,但将某些工作推迟到查询计划执行时也有好处。将安全检查推迟到执行时间的查询计划可以在用户之间共享,并且在安全性更改时不需要重新编译。因此,安全验证的某些部分通常延迟到查询计划执行。
在编译期间也可以对常量表达式进行约束检查。例如,UPDATE命令可能有一个形式为SET EMP.salary = -1的子句。如果完整性约束为薪金指定了正值,则甚至不需要执行查询。然而,将这项工作推迟到执行时间是很常见的。
如果查询解析并通过验证,则将查询的内部格式传递给查询重写模块以进行进一步处理。
4.2 Query Rewrite
查询重写模块(或rewriter)负责在不更改其语义的情况下简化和规范化查询。它只能依赖于查询和目录中的元数据,而不能访问表中的数据。虽然我们说“重写”查询,但大多数重写器实际上是在查询的内部表示上操作,而不是在原始SQL语句文本上操作。(注:这是显然的,因为DBMS其实无法理解SQL字符串,直接在内部表达中进行修改)查询重写模块通常以其在输入时接受的相同内部格式输出查询的内部表示形式。
许多商业系统中的重写器是一个逻辑组件,其实际实现要么在查询解析的后期阶段,要么在查询优化的早期阶段。例如,在DB2中,重写器是一个独立的组件,而在SQL Server中,查询重写是作为query Optimizer的早期阶段完成的。尽管如此,单独考虑重写器是有用的,即使显式架构边界并不存在于所有系统中。
重写器的主要责任是:
-
View expansion(视图扩张):处理视图是重写器的主要传统角色。对于出现在FROM子句中的每个视图引用,重写器从编目管理器检索视图定义。然后将查询重写为(1)将该视图替换为该视图和引用的表和谓词(2)将对该视图的任何引用替换为对视图中表的列引用。此过程递归地应用,直到查询仅在表上表示且不包含视图。这种视图扩展技术最初是在INGRES中为基于集合的QUEL语言提出的,它需要在SQL中小心地正确处理重复消除、嵌套查询、null和其他棘手的细节。[68,85]
-
Constant arithmetic evaluation(常量算数求值):查询重写可以简化常量算术表达式:例如,R.x < 10 + 2 + R.y 被重写为R.x < 12 + R.y。
-
Logical rewriting of predicates(谓词的逻辑重写):基于WHERE子句中的谓词和常量应用逻辑重写。简单的布尔逻辑通常用于改进表达式之间的匹配和基于索引的访问方法的功能。例如,NOT EMP.Salary > 1000000这样的谓词可以重写为EMP.Salary <= 1000000。通过简单的可满足性测试,这些逻辑重写甚至可以缩短查询执行时间。例如,表达式EMP.Salary < 75000 AND EMP.Salary > 1000000可以替换为FALSE。这可能允许系统在不访问数据库的情况下返回空查询结果。无法满足的查询可能看起来难以置信,但请记住,谓词可能“隐藏”在视图定义中,外部查询的编写者不知道。例如,上面的查询可能是在一个名为“Executives”的视图上查询工资过低的员工的结果。在Microsoft SQL Server的并行安装中,不可满足的谓词也构成了“分区消除”的基础:当一个关系通过范围谓词在磁盘卷上进行水平范围分区时,如果它的范围分区谓词与查询谓词一起不能满足,则不需要在卷上运行查询。
另一个重要的逻辑重写使用谓词的传递性来引出新的谓词R.x < 10 AND R.x = S.y,例如,建议添加额外的谓词“AND S.y < 10”。添加这些传递谓词可以提高优化器选择在执行早期过滤数据的计划的能力,特别是通过使用基于索引的访问方法。
-
Semantic optimization(语义优化):在许多情况下,模式上的完整性约束存储在编目中,可以用来帮助重写一些查询。这种优化的一个重要例子是消除冗余连接(redundant join elimination)。当外键约束将一个表(例如,Emp.deptno)的列绑定到另一个表(Dept)时,就会出现这种情况。给定这样的外键约束,我们知道每个Emp都有一个Dept,并且如果没有相应的Dept元组(父元组),Emp元组就不可能存在。
考虑一个连接两个表但不使用Dept列的查询:
1 | SELECT Emp.name, Emp.salary |
这样的查询可以重写以删除Dept表(假设Emp.deptno被约束为非空),从而删除连接。同样,这些看似不可信的场景往往是通过观点自然产生的。例如,用户可以在连接这两个表的视图EMPDEPT上提交关于雇员属性的查询。像Siebel这样的数据库应用程序使用非常宽的表,当底层数据库不支持足够宽的表时,它们使用多个表,并在这些表上显示视图。如果没有冗余连接消除,这个基于视图的可扩展实现的性能将非常差。
当表上的约束与查询谓词不兼容时,语义优化还可以完全规避查询执行。
- Subquery flattening and other heuristic rewrites(子查询扁平化和其他启发式重写):查询优化器是当前一代商业dbms中最复杂的组件之一。为了限制复杂性,大多数优化器对单独的SELECTFROM-WHERE查询块进行隔离操作,并且不会跨块进行优化。因此,许多系统将查询重写为更适合优化器的形式,而不是使查询优化器进一步复杂化。这种转换有时称为查询规范化。规范化的一个示例类是将语义等价的查询重写为规范形式,以确保语义等价的查询将被优化以生成相同的查询计划。另一个重要的启发式方法是尽可能平坦嵌套查询,以最大限度地暴露查询优化器的单块优化机会。在SQL的某些情况下,由于重复语义、子查询、空值和相关性等问题,这变得非常棘手。在早期,子查询扁平化是一种纯粹的启发式重写,但现在一些产品基于基于成本的分析来重写决策。其他改写也可以跨查询块进行。例如,谓词传递性允许跨子查询复制谓词。扁平化相关子查询对于在并行体系结构中实现良好的性能尤其重要:相关子查询导致跨查询块的“嵌套循环”风格比较,这将子查询的执行序列化,而不管并行资源是否可用。[52,68,80]
4.3 Query Optimizer
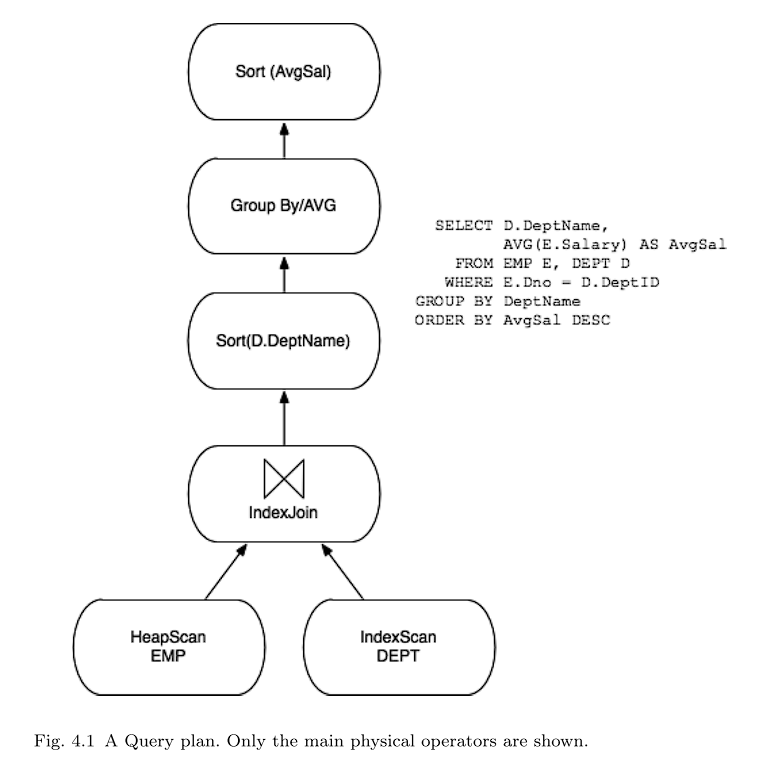
查询优化器的工作是将内部查询表示转换为执行查询的有效查询计划(图4.1)。可以将查询计划看作是一个数据流图,它通过查询操作符的图来输送表数据。在许多系统中,查询首先被分解为SELECT-FROM-WHERE查询块。然后使用与Selinger等人在System R优化器的著名论文中描述的技术类似的技术来优化每个单独的查询块。完成后,通常在每个查询块的顶部添加一些操作符,作为后处理来计算GROUP BY、ORDER BY、HAVING和DISTINCT子句(如果它们存在)。然后将不同的块以直接的方式拼接在一起。[79]
生成的查询计划可以用多种方式表示。最初的System R原型将查询计划编译成机器码,而早期的INGRES原型生成可解释的查询计划。查询解释被INGRES的作者在20世纪80年代早期的回顾性论文中列为“错误”,但摩尔定律和软件工程在某种程度上证明了INGRES的决定是正确的。具有讽刺意味的是,编译成机器码被System R项目的一些研究人员列为错误。当System R代码库被制作成商业DBMS系统(SQL/DS)时,开发团队的第一个变化是用解释器取代机器码执行器。[85]
为了实现跨平台的可移植性,现在每个主要的DBMS都将查询编译成某种可解释的数据结构。它们之间唯一的区别是中间形式的抽象程度。某些系统中的查询计划是一个非常轻量级的对象,与关系代数表达式没有什么不同,它用访问方法、连接算法等名称进行了注释。其他系统使用较低级别的“操作码”语言,在本质上更接近Java字节码,而不是关系代数表达式。为了简化我们的讨论,我们将在本文的其余部分集中讨论类似代数的查询表示。
虽然Selinger的论文被广泛认为是查询优化的“圣经”,但它是初步的研究。所有的系统都在许多方面显著地扩展了这项工作。主要扩展包括:
-
Plan space(规划空间):System R优化器通过只关注“左深”查询计划(其中连接的右侧输入必须是基表)和“延迟笛卡尔积”(确保笛卡尔积仅在数据流中的所有连接之后出现)来限制其计划空间。在今天的商业系统中,众所周知,“浓密”树(嵌套的右侧输入)和早期使用笛卡尔积在某些情况下是有用的。因此,在某些情况下,大多数系统都会考虑这两种选择。
-
Selectivity stimation(选择性估计):Selinger论文中的选择性估计技术基于简单的表和索引基数,并且根据当前生成系统的标准是不可靠的。今天的大多数系统通过直方图和其他汇总统计来分析和总结属性中值的分布。由于这涉及到访问每列中的每个值,因此可能会相对昂贵。因此,一些系统使用抽样技术来获得分布的估计,而不需要穷举扫描。
基表连接的选择性估计可以通过“连接”连接列上的直方图来实现。为了超越单列直方图,最近提出了更复杂的方案来合并列之间的依赖关系等问题。这些创新已经开始出现在商业产品中,但仍需取得相当大的进展。这些模式采用缓慢的一个原因是许多行业基准中存在一个长期存在的缺陷:像TPC-D和TPC-H这样的基准中的数据生成器在列中生成统计独立的值,因此不鼓励采用处理“真实”数据分布的技术。这个基准测试缺陷已经在TPC-DS基准测试中得到了解决。尽管采用率较低,但改进的选择性估计的好处已得到广泛认可。Ioannidis和Christodoulakis注意到,在优化早期的选择性错误会成倍地传播到计划树中,并导致糟糕的后续估计。[16,45,69,70]
-
Search Algorithms(搜索算法):一些商业系统,特别是微软和Tandem的系统,放弃了Selinger的动态规划优化方法,转而采用基于Cascades中使用的技术的目标导向的“自上而下”搜索方案。在某些情况下,自顶向下搜索可以减少优化器考虑的计划数量,但也会产生增加优化器内存消耗的负面影响。如果实际的成功是质量的标志,那么在自顶向下搜索和动态规划之间的选择是无关紧要的。在最先进的优化器中,这两种方法都可以很好地工作,但不幸的是,这两种方法都有运行时和内存需求,这些需求在查询中的表数量上呈指数级增长。
有些系统依靠启发式搜索方案来处理“太多”表的查询。尽管随机查询优化启发式的研究文献很有趣,但商业系统中使用的启发式往往是专有的,显然不像随机查询优化文献。一个具有教育意义的练习是检查开源MySQL引擎的查询“优化器”,最后检查完全是启发式的,主要依赖于利用索引和键/外键约束。这让人想起Oracle的早期(和臭名昭著的)版本。在某些系统中,只有当用户明确指示优化器如何选择计划(通过SQL中嵌入的所谓优化器“提示”)时,才能执行FROM子句中包含太多表的查询。[25,82,5,18,44,84]
-
Parallelism(并行):目前,每个主要的商业DBMS都对并行处理提供了一些支持。大多数还支持“查询内”并行:通过使用多个处理器加速单个查询的能力。查询优化器需要参与确定如何跨多个cpu调度操作符(和并行化操作符),以及(在无共享或共享磁盘的情况下)跨多个单独的计算机调度操作符。Hong和Stonebraker选择避免并行优化的复杂性问题,并使用两个阶段:首先调用传统的单系统优化器来选择最佳的单系统计划,然后跨多个处理器或机器调度该计划。(注:这里的意思应该是不让查询优化器考虑如何处理多核调度,而是把这个责任转交给了查询执行器。)关于第二个优化阶段的研究已经发表,但尚不清楚这些结果在多大程度上影响了当前的实践。[42,19,21]
一些商业系统实现了上面描述的两阶段方法。其他人则尝试对集群网络拓扑和跨集群的数据分布进行建模,以便在单个阶段生成最佳计划。虽然在某些情况下,单阶段方法可以产生更好的计划,但是尚不清楚使用单阶段方法可能获得的额外查询计划质量是否值得额外的优化器复杂性。因此,许多当前的实现仍然支持两阶段方法。目前这个领域似乎更像是艺术而不是科学。Oracle OPS(现在称为RAC)共享磁盘集群使用两阶段优化器。IBM DB2 Parallel Edition(现在称为DB2 Database Partitioning Feature)最初是使用两阶段优化器实现的,但后来逐渐向单阶段实现发展。
-
Auto-Tuning(自动调谐):各种正在进行的工业研究努力试图提高DBMS自动做出调优决策的能力。其中一些技术基于收集查询工作负载,然后使用优化器通过各种“假设”分析来查找计划成本。例如,如果存在其他索引或数据以不同的方式布局,情况会怎样?正如Chaudhuri和Narasayya所描述的那样,优化器需要进行一些调整以有效地支持此活动。Markl等人的学习优化器(LEO)工作也是这样。[12,57]
4.3.1 A Note on Query Compilation and Recompilation
SQL支持“准备”查询的能力:通过解析器、重写器和优化器传递查询,存储结果查询执行计划,并在随后的“执行”语句中使用它。这甚至可以用于动态查询(例如,从web表单),其中有程序变量在查询常量的位置。唯一的问题是,在选择性估计期间,优化器假定表单提供的变量为“典型”值。当选择非代表性的“典型”值时,可能会导致非常糟糕的查询执行计划。查询准备对于基于相当可预测的数据的表单驱动的预制查询(canned queries)特别有用:在编写应用程序时准备查询,当应用程序运行时,用户不会经历解析、重写和优化的开销。
尽管在编写应用程序时准备查询可以提高性能,但这是一个非常严格的应用程序模型。许多应用程序程序员以及Ruby on Rails等工具包在程序执行期间动态构建SQL语句,因此预编译不是一个选项。因为这很常见,DBMS将这些动态查询执行计划存储在查询计划缓存中。如果随后提交相同(或非常相似)的语句,则使用缓存版本。这种技术近似于没有应用程序模型限制的预编译静态SQL的性能,并且被大量使用。
当数据库随时间变化时,通常需要重新优化准备好的计划。至少,当删除索引时,必须从存储的计划缓存中删除任何使用该索引的计划,以便在下次调用时选择新计划。
其他关于重新优化计划的决策更加微妙,暴露了供应商之间的哲学差异。一些供应商(例如,IBM)非常努力地提供跨调用的可预测性能,而牺牲了每个调用的最佳性能。(注:也就是尽可能减少编译次数,为此牺牲了每次执行的速度。)因此,除非计划不再执行,否则他们不会重新优化计划,就像删除索引的情况一样。其他供应商(例如Microsoft)非常努力地使他们的系统自我调整,并将更积极地重新优化计划。例如,如果表的基数发生重大变化,SQL服务器将触发重新编译,因为此更改可能会影响索引和连接顺序的最佳使用。自调整系统可以说不太可预测,但在动态环境中更有效。
这种哲学上的区别源于这些产品历史客户群的差异。IBM传统上专注于拥有熟练DBA和应用程序程序员的高端客户。在这些高预算的信息技术商店中,数据库的可预测性能至关重要。在花了几个月的时间调整数据库设计和设置后,数据库管理员不希望优化器不可预测地改变它。相比之下,微软战略性地进入低端数据库市场。因此,他们的客户往往拥有较低的信息技术预算和专业知识,并希望数据库管理系统尽可能地“自我调整”。
随着时间的推移,这些公司的业务战略和客户群已经融合,因此它们直接竞争,它们的方法也在一起发展。微软有希望完全控制和查询计划稳定性的大型企业客户。IBM有一些客户没有数据库管理员资源,需要完全自动管理。
4.4 Query Executor

查询执行器在完全指定的查询计划上运行。这通常是一个有向数据流图,它连接封装基表访问和各种查询执行算法的运算符。在某些系统中,这个数据流图已经被优化器编译成低级操作码。在这种情况下,查询执行器基本上是一个运行时解释器。在其他系统中,查询执行器接收数据流图的表示,并基于图布局递归地为运算符调用过程。我们关注后一种情况,因为操作码方法本质上是将我们在这里描述的逻辑编译成程序。
大多数现代查询执行器使用最早的关系系统中使用的迭代器模型。迭代器最简单地以面向对象的方式描述。图4.2显示了迭代器的简化定义。每个迭代器指定其定义数据流图中边的输入。查询计划中的所有运算符-数据流图中的节点-都实现为迭代器类的子类。一个典型系统中的子类集可能包括filescan、indexcan、sor、nested-loops connect、mery-connect、hashconnect、duplicate-elimination和grouped-aggregation。迭代器模型的一个重要特征是迭代器的任何子类都可以用作任何其他子类的输入。因此,每个迭代器的逻辑独立于图中的子级和父级,并且不需要迭代器特定组合的特殊情况代码。
Graefe在他的查询执行调查中提供了有关迭代器的更多详细信息。还鼓励感兴趣的读者检查开源PostgreSQL代码库。PostgreSQL对大多数标准查询执行算法使用了适度复杂的迭代器实现。[24]
4.4.1 Iterator Discussion
迭代器的一个重要特性是它们将数据流与控制流耦合。get _next() 调用是一个标准过程调用,它通过调用堆栈返回对调用者的元组引用。因此,当返回控制时,元组将准确地返回给图中的父级。这意味着只需要一个DBMS线程来执行整个查询图,并且不需要队列或迭代器之间的速率匹配。这使得关系查询执行器易于实现和调试,并且与其他环境中的数据流架构形成对比。例如,网络依赖于各种协议在并发生产者和消费者之间进行排队和反馈。(注:这假设迭代器永远不会阻塞等待I/O请求。在预取无效的情况下,由于I/O阻塞,迭代器模型中可能会出现低效率。这在单系统数据库中通常不是问题,但在远程表或多系统集群中执行查询时经常会出现[23,56]。)
单线程迭代器架构对于单系统(非集群)查询执行也非常有效。在大多数数据库应用程序中,性能指标是查询完成的时间,但其他优化目标也是可能的。例如,最大化DBMS吞吐量是另一个合理的目标。交互式应用程序中流行的另一个目标是第一行的时间。在单处理器环境中,当资源得到充分利用时,给定查询计划的完成时间就实现了。在迭代器模型中,由于其中一个迭代器始终处于活动状态,因此资源利用率最大化。
正如我们之前提到的,大多数现代DBMS都支持并行查询执行。幸运的是,这种支持基本上无需更改迭代器模型或查询执行架构即可提供。并行性和网络通信可以封装在特殊的交换迭代器中,如Graefe所述;这些还以DBMS迭代器不可见的方式实现网络风格的数据“推送”,这些迭代器保留了“拉”风格的get_next() API。一些系统也在其查询执行模型中明确了推送逻辑。[23]
4.4.2 Where’s the Data?
我们对迭代器的讨论方便地回避了任何关于动态数据的内存分配问题。我们既没有指定元组如何存储在内存中,也没有指定它们如何在迭代器之间传递。在实践中,每个迭代器都预先分配了固定数量的元组描述符,一个用于每个输入,一个用于输出。元组描述符通常是列引用的数组,其中每个列引用由对内存中其他地方的元组的引用和该元组中的列偏移量组成。(注:元组描述符不是元组本体,相当于一个指针。)基本迭代器超类逻辑从不动态分配内存。这就提出了被引用的实际元组存储在内存中的位置的问题。
这个问题有两个可能的答案。第一个是元组驻留在缓冲池的页面中。我们称之为BP元组。如果迭代器构造了一个引用BP元组的元组描述符,它必须增加元组页面的pin计数——对该页面上元组的活动引用数量的计数。当元组描述符被清除时,它会减少引脚计数。第二种可能性是迭代器实现可以为内存堆上的元组分配空间。我们称之为M元组。迭代器可以通过从缓冲池中复制列(由引脚增量/减量对括起来的副本)和/或通过评估特定查询中的表达式(例如,算术表达式,如“EM. sal * 0.1”)来构造M元组。
一种通用方法是始终将数据立即从缓冲池中复制到M元组中。这种设计使用M元组作为唯一的机上元组结构并简化了执行器代码。该设计还避免了由于缓冲池pin和unpin调用被长时间执行(以及许多行代码)分开而导致的错误。这种类型的一个常见bug是忘记完全取消页面的别针(“缓冲区泄漏”)。不幸的是,如第4.2节所述,独占使用M元组可能是一个主要的性能问题,因为内存副本通常是高性能系统中的严重瓶颈。(注:?第4.2节好像没讲这个啊)
另一方面,在某些情况下构造M元组是有意义的。只要BP元组被迭代器直接引用,BP元组所在的页面就必须保持固定在缓冲池中。这会消耗相当于一页的缓冲池内存,并束缚缓冲区替换策略的手脚。如果元组将在很长一段时间内继续被引用,则从缓冲池中复制元组可能会很有用。
这个讨论的结果是,最有效的方法是支持可以同时引用BP元组和M元组的元组描述符。
4.4.3 Data Modification Statements
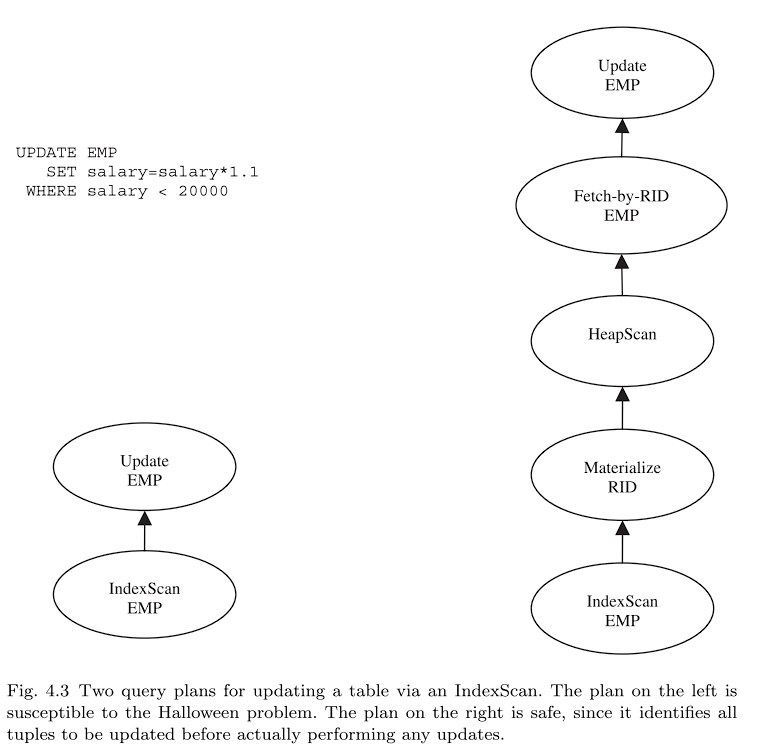
到目前为止,我们只讨论了查询,即只读SQL语句。存在另一类修改数据的DML语句:INSERT、DELETE和UPDATE语句。这些语句的执行计划通常看起来像简单的直线查询计划,以单个访问方法作为源,并在管道的末尾使用数据修改运算符。
然而,在某些情况下,这些计划同时查询和修改相同的数据。读取和写入同一个表(可能多次)的混合需要一些小心。一个简单的例子是臭名昭著的“万圣节问题”,之所以如此称呼,是因为它是由System R小组在10月31日发现的。
万圣节的问题来自于一个特定的执行策略,比如“给工资低于2万美元的人加薪10%”这个查询的一个简单计划将一个索引扫描迭代器通过Emp.salary字段管道到一个更新迭代器中(图4.3的左侧)。这个流水线提供了良好的I/O局部性,因为它会在元组从B+树中获取后对其进行修改。然而,这种流水线也可能导致索引扫描“重新发现(rediscovering)”以前修改过的元组,该元组在修改后在树中向右移动,从而导致每个员工多次加薪。在我们的例子中,所有低薪员工都会得到反复加薪,直到他们挣得超过2万美元。这不是声明的意图。
SQL语义禁止这种行为:单个SQL语句不允许“看到”自己的更新。需要注意确保遵守此可见性规则。一个简单、安全的实现是查询优化器选择避免更新列上索引的计划。在某些情况下,这可能效率很低。另一种技术是使用批量读写方案。这将在数据流中的索引扫描和数据修改运算符之间插入记录ID物化和获取运算符(图4.3的右侧)。物化运算符接收所有要修改的元组的ID并将它们存储在临时文件中。然后它扫描临时文件并通过RID获取每个物理元组ID,并将生成的元组提供给数据修改运算符。如果优化器选择一个索引,在大多数情况下,这意味着只有几个元组被更改。因此,这种技术的明显低效可能是可以接受的,因为临时表可能完全保留在缓冲池中。流水线更新方案也是可能的,但需要来自存储引擎的(有点奇特的)多版本支持。[74]
4.5 Access Methods
访问方法是管理对系统支持的各种基于磁盘的数据结构的访问的例程。这些通常包括无序文件(“堆”)和各种索引。所有主要的商业系统都实现堆和B+树索引。Oracle和PostgreSQL都支持用于相等查找的哈希索引。一些系统开始引入对多维索引的基本支持,例如R-tree。PostgreSQL支持一种称为通用搜索树(GiST)的可扩展索引,目前使用它来实现多维数据的R-tree和文本数据的RD-tree。IBMUDB版本8引入了多维集群(MDC)索引,用于通过多维范围访问数据。以读取为主的数据仓库工作负载为目标的系统通常还包括索引的专门位图变体,正如我们在第4.6节中描述的那样。[32,39,40,66,65]
访问方法提供的基本API是迭代器API。init()例程被扩展为接受表单列运算符constant的“搜索参数”(或在System R的术语中,SARG)。NULL SARG被视为扫描表中所有元组的请求。当没有更多元组满足搜索参数时,访问方法层的get next()调用返回NULL。
将SARG传递到访问方法层有两个原因。第一个原因应该很清楚:像B+树这样的索引访问方法需要SARG才能有效运行。第二个原因是一个更微妙的性能问题,但它适用于堆扫描和索引扫描。假设调用访问方法层的例程检查了SARG。然后每次访问方法从get next()返回时,它必须要么(a)返回驻留在缓冲池中帧中的元组的句柄,并将页面固定在该帧中以避免替换,要么(b)复制元组。如果调用者发现SARG不满足,它负责(a)减少页面上的pin计数,或(b)删除复制的元组。然后它必须重新调用get next()来尝试页面上的下一个元组。这种逻辑在函数调用/返回对中消耗了大量的CPU周期,并且会不必要地将页面固定在缓冲池中(为缓冲帧产生不必要的争用),或者不必要地创建和销毁元组的副本——在流式传输数百万个元组时,这是一个巨大的CPU开销。请注意,典型的堆扫描将访问给定页面上的所有元组,导致每个页面多次迭代此交互。相比之下,如果所有这些逻辑都在访问方法层完成,则可以通过一次测试SARG页面来避免重复的调用/返回以及pin/unpin或复制/删除,并且只从满足SARG的元组的get next()调用中返回。SARGS在存储引擎和关系引擎之间保持了良好的架构边界,同时获得了出色的性能。(注:这就是谓词下推罢,将筛选的逻辑下推到下层算子甚至访问层)因此,许多系统支持非常丰富的SARG支持并广泛使用它们。就主题而言,这是标准DBMS智慧在集合中的多个项目之间摊销工作的一个实例,但在这种情况下,它被应用于CPU性能,而不是磁盘性能。
所有DBMS都需要某种方式来“指向”基表中的行,以便索引条目可以适当地引用行。在许多DBMS中,这是通过使用直接行ID(RID)来实现的,这些行ID是基表中行的物理磁盘地址。这样做的好处是速度快,但缺点是基表行移动非常昂贵,因为指向该行的所有辅助索引都需要更新。查找和更新这些行可能都很昂贵。当更新更改行大小并且当前页面上的空间不可用于新更新的行时,行需要移动。当拆分B+树时,许多行需要移动。DB2使用转发指针来避免第一个问题。这需要第二个I/O来查找移动的页面,但避免了更新辅助索引。DB2通过简单地不支持B+树作为基表元组的主存储来避免第二个问题。MicrosoftSQLServer和Oracle支持B+树作为主存储,并且必须能够有效地处理行移动。采用的方法是避免在辅助索引中使用物理行地址,而是使用行主键(如果表没有唯一键,则使用一些额外的系统提供的位来强制唯一性)而不是物理RID。这在使用辅助索引访问基表行时牺牲了一些性能,但避免了行移动导致的问题。在某些情况下,Oracle通过保留带有主键的物理指针来避免这种方法的性能损失。如果该行没有移动,将使用物理指针快速找到它。但是,如果它已经移动,将使用较慢的主键技术。
Oracle通过允许行跨越页面来避免移动堆文件中的行。因此,当一行更新为不再适合原始页面的更长值时,而不是被迫移动行,它们存储适合原始页面的内容,其余部分可以跨越到下一个页面。
与所有其他迭代器相比,访问方法与围绕事务的并发和恢复逻辑具有深度交互,如第4节所述。
4.6 Data Warehouses
数据仓库——用于决策支持的大型历史数据库,定期加载新数据——已经发展到需要专门的查询处理支持,在下一节中,我们将概述它们往往需要的一些关键功能。这个主题与两个主要原因相关:
- 数据仓库是DBMS技术的一个非常重要的应用。有人声称仓库占所有DBMS活动的1/3。[26,63]
- 本节到目前为止讨论的传统查询优化和执行引擎在数据仓库上不能很好地工作。因此,需要扩展或修改才能获得良好的性能。
关系DBMS最初是在20世纪70年代和80年代设计的,目的是满足业务数据处理应用程序的需求,因为这是当时的主要需求。20世纪90年代初,数据仓库和“业务分析”市场出现,并从那时起急剧增长。
到20世纪90年代,联机事务处理取代了批处理业务数据,成为数据库使用的主要模式。此外,大多数联机事务处理系统都有计算机操作员银行提交交易,要么通过与最终客户的电话交谈,要么通过从纸上输入数据。自动柜员机已经普及,允许客户在没有操作员干预的情况下直接进行某些交互。此类交易的响应时间对产品至关重要。随着网络迅速用最终客户的自助服务取代运营商,这种响应时间要求在今天变得更加紧迫和多样化。
大约在同一时间,零售领域的企业有了捕获所有历史销售交易的想法,并将它们存储一两年。买家可以利用这些历史销售数据来找出“什么热门,什么不热门”这些信息可以用来影响购买模式。同样,这些数据可以用来决定促销什么商品,哪些商品打折,哪些商品寄回给制造商。当时的普遍看法是,零售领域的历史数据仓库在几个月内通过更好的库存管理、货架和商店布局来收回成本。
当时很明显,数据仓库应该部署在与联机事务处理系统不同的硬件上。使用这种方法论,冗长(通常不可预测)的商业智能查询不会破坏联机事务处理的响应时间。此外,数据的性质非常不同;数据仓库处理历史,联机事务处理“现在”。最后,发现历史数据所需的模式通常与当前数据所需的模式不匹配,需要进行数据转换才能从一个模式转换为另一个模式。
出于这些原因,构建了工作流系统,从操作联机事务处理系统中“抓取”数据并将其加载到数据仓库中。这种系统被命名为“提取、转换和加载”(ETL)系统。流行的ETL产品包括IBM的数据阶段和Informatica的PowerCenter。在过去十年中,ETL供应商通过数据清理工具、重复数据删除工具和其他以质量为导向的产品扩展了他们的产品。
正如我们下面讨论的,在数据仓库环境中必须处理几个问题。
4.6.1 Bitmap Indexs
B+树针对记录的快速插入、删除和更新进行了优化。相比之下,数据仓库执行初始加载,然后数据在几个月或几年内保持静态。此外,数据仓库通常具有具有少量值的列。例如,考虑存储客户的性别。只有两个值,这可以用位图中每条记录的一位来表示。相比之下,B+树将需要(值,记录指针)对每条记录,并且通常每条记录消耗40位。
位图对于合取筛选也有优势,例如:
在这种情况下,可以通过相交位图来确定结果集。有许多更复杂的位图算术技巧可以用来提高常见分析查询的性能。[65]
在当前产品中,位图索引补充了Oracle中用于索引存储数据的B+树,而DB2提供了更有限的版本。Sybase IQ广泛使用位图索引,当然,位图的缺点是更新成本很高,因此它们的实用性仅限于仓库环境。
4.6.2 Fast Load
通常,数据仓库会在半夜加载当天的事务数据。对于只在白天营业的零售场所来说,这是一个明显的策略。夜间大量加载的第二个原因是避免在用户交互期间出现更新。考虑一个业务分析师的情况,他希望制定某种棘手查询,也许是为了调查飓风对客户购买模式的影响。这个查询的结果可能会建议后续查询,例如调查大风暴期间(注:类似于双十一)的购买模式。这两个查询的结果应该是兼容的,即答案应该在同一个数据集上计算。如果同时加载数据,这对于包括最近历史的查询可能会有问题。考虑一个业务分析师的情况,他希望制定某种临时查询,也许是为了调查大风暴对客户购买模式的影响。这个查询的结果可能会建议后续查询,例如调查大风暴期间的购买模式。这两个查询的结果应该是兼容的,即答案应该在同一个数据集上计算。如果同时加载数据,这对于包括最近历史的查询可能会有问题。
因此,数据仓库快速批量加载是至关重要的。尽管可以使用一系列SQL插入语句对仓库加载进行编程,但这种策略从未在实践中使用过。相反,使用了一个批量加载器,它将大量记录流式传输到存储中,而没有SQL层的开销,并利用特殊的批量加载方法来访问方法,如B+树。按整数计算,批量装载机比SQL插件快一个数量级,所有主要供应商都提供高性能批量装载机。
随着世界转向电子商务和每天24小时的销售,这种批量装载策略变得不那么有意义。但是转向“实时”仓库有几个问题。首先,插入,无论是来自批量加载器还是来自事务,都必须按照第6.3节中的讨论设置写锁。这些与查询获取的读锁发生冲突,并可能导致仓库“冻结”。其次,如上所述跨查询集提供兼容的答案是有问题的。
这两个问题都可以通过避免就地更新和提供历史查询来规避。如果保留更新前后的值,并适当地添加时间戳,那么就可以提供最近一段时间的查询。运行同一历史时间的查询集合将提供兼容的答案。此外,无需设置读锁即可运行相同的历史查询。
如第5.2.1节所述,一些供应商提供了多版本(MVCC)隔离级别,如SNAPSHOT ISOLATION,尤其是Oracle。随着实时仓库变得越来越流行,其他供应商可能会效仿。
4.6.3 Materialized Views
数据仓库通常是巨大的,连接多个大表的查询倾向于“永远”运行。为了提高流行查询的性能,大多数供应商提供物化视图。与本节前面讨论的纯逻辑视图不同,物化视图采用的是可以查询的实际表,但对应于真正的“基本”数据表上的逻辑视图表达式。对物化视图的查询将避免在运行时执行视图表达式中的连接。代替的是,物化视图必须在执行更新时保持最新。
物化视图的使用有三个方面:(a)选择要物化的视图,(b)保持视图的新鲜度(freshness),以及(c)考虑在棘手的查询中使用物化视图。对于(a)是我们在4.3节中提到的自动数据库调优的一个高级方面。对于(c)在各种产品中实现了不同程度;即使对于简单的单块查询,这个问题在理论上也是具有挑战性的,对于具有聚合和子查询的通用SQL来说更是如此。对于(b),大多数供应商提供了多种刷新技术,从每次更新到派生物化视图的表执行物化视图更新,到定期丢弃然后重新创建物化视图。这种策略在运行时开销和物化视图的数据展示一致性之间提供了权衡。[51]
4.6.4 OLAP and Ad-hoc Query Support
一些仓库工作负载有可预测的查询。例如,在每个月底,可能会运行一份汇总报告,以按部门提供零售链中每个销售区域的总销售额。与此工作负载穿插的是由业务分析师动态制定的棘手查询。
显然,适当构造的物化视图可以支持可预测的查询。更一般地说,由于大多数业务分析查询都要求聚合,因此可以计算一个物化视图,即每个商店按部门的聚合销售额。然后,如果指定了上述区域查询,则可以通过“滚动”每个区域中的单个商店来满足它。
这种聚合通常被称为数据立方体(data cubes),是一类有趣的物化视图。在20世纪90年代初,Essbase等产品提供了定制工具,用于以优先立方体格式存储数据,同时提供基于立方体的用户界面来导航数据,这种能力后来被称为在线分析处理(OLAP)。随着时间的推移,数据立方体支持已经被添加到全功能关系数据库系统中,通常被称为关系OLAP(ROLAP)。许多提供ROLAP的DBMS已经发展到在特殊情况下在内部实现一些早期的OLAP风格的存储方案,因此有时被称为HOLAP(混合OLAP)方案。
显然,数据立方体为可预测的、有限类别的查询提供了高性能。但是,它们通常对支持棘手的查询没有帮助。
4.6.5 Optimization of Snowflake Schema Queries
许多数据仓库遵循特定的模式设计方法。具体来说,它们存储事实的集合,在零售环境中,这些事实通常是简单的记录,例如“客户X在时间T从商店Z购买了产品Y”。
中央事实表记录有关每个事实的信息,例如购买价格、折扣、销售税信息等。事实表中还有一组维度中每个维度的外键。(Also in the fact table are foreign keys for each of a set of dimensions.)维度可以包括客户、产品、商店、时间等。这种形式的模式通常称为星形模式,因为它有一个由维度包围的中心事实表,每个维度与事实表有1-N 的 primary-key-foreign-key关系。在实体关系图中绘制,这样的模式是星形的。
许多维度自然是分层的。例如,如果商店可以聚合到区域中,那么商店维度表在区域维度表中添加了一个外键。类似的层次结构对于涉及时间(月/天/年)、管理层次结构等的属性很典型。在这些情况下,会产生多级星形或雪花模式。
本质上,所有数据仓库查询都需要对这些表中的某些属性过滤雪花模式中的一个或多个维度,然后将结果连接到中央事实表,按事实表或维度表中的某些属性分组,然后计算SQL聚合。
随着时间的推移,供应商在他们的优化器中对此类查询进行了特殊设置,因为它非常流行,并且为如此长时间运行的命令选择一个好的计划至关重要。
4.6.6 Data Warehousing: Conclusions
可以看出,数据仓库需要与联机事务处理环境完全不同的功能。除了B+树之外,还需要位图索引。除了通用优化器,还需要特别关注雪花模式上的聚合查询。需要的不是普通视图,而是物化视图。需要的不是快速事务更新,而是快速批量加载等。[11]
主要的关系供应商从面向联机事务处理的体系结构开始,并随着时间的推移增加了面向仓库的功能。此外,还有各种较小的供应商在这一领域提供DBMS解决方案。其中包括Teradata和Netezza,它们提供运行DBMS的无共享专有硬件。此外,向该领域销售的还有Greenplum(PostgreSQL的并行化)、DATAllegro和EnterpriseDB,它们都在更传统的硬件上运行。
最后,有些人(包括其中一位作者)声称,与传统存储引擎相比,列存储在数据仓库空间中具有巨大优势,传统存储引擎的存储单位是表行。当表“宽”(高密度)时,单独存储每一列特别有效,访问往往只在几列上。列存储还可以实现简单有效的磁盘压缩,因为列中的所有数据都来自同一类型。列存储的挑战在于,表中行的位置需要在所有存储的列中保持一致,或者需要额外的机制来连接列。这对于联机事务处理来说是一个大问题,但对于附加(主要是仓库或系统日志存储库等数据库)来说不是一个主要问题。[36,89,90]
4.7 Database Extensibility
传统上,关系数据库被认为存储的数据类型有限,主要关注公司和行政记录保存中使用的“事实和数据”。然而,今天,它们拥有以各种流行编程语言表示的广泛数据类型。这是通过使核心关系DBMS以各种方式可扩展来实现的。在本节中,我们简要调查了广泛使用的扩展类型,强调了在交付这种可扩展性时出现的一些架构问题。这些特性在不同程度上出现在当今大多数商业DBMS中,也出现在开源PostgreSQL DBMS中。
4.7.1 Abstract Data Types
原则上,关系模型与可以放置在模式列上的标量数据类型的选择无关。但是最初的关系数据库系统只支持一组静态的字母数字列类型,这种限制与关系模型本身有关。关系DBMS可以在运行时扩展到新的抽象数据类型,如早期的IngresADT系统所示,在后续的Postgres系统中更积极。为了实现这一点,DBMS类型系统——也就是解析器——必须从系统目录(system catalog)中驱动,系统目录维护系统已知类型的列表,以及用于操作类型的“方法”(代码)的指针。在这种方法中,DBMS不解释类型,它只是在表达式计算中适当地调用它们的方法;因此得名“抽象数据类型”作为一个典型的例子,可以为二维空间“矩形”注册一个类型,以及矩形交集或联合等操作的方法。这也意味着系统必须为用户定义的代码提供运行时引擎,并安全地执行该代码,而不会有任何导致数据库服务器崩溃或损坏数据的风险。当今所有主要的DBMS都允许用户以现代SQL的命令式“存储过程”子语言定义函数。除了MySQL,大多数都支持至少几种其他语言,通常是C和Java。在Windows平台上,MicrosoftSQLServer和IBMDB2支持编译到Microsoft. Net Common Language Runtime的代码,该代码可以用多种语言编写,最常见的是Visual Basic、C++和C#。PostgreSQL附带对C、Perl、Python和Tcl的支持,并允许在运行时将新语言添加到系统中——有流行的Ruby第三方插件和开源R统计包。[80]
为了使抽象数据类型在DBMS中高效运行,查询优化器必须在选择和连接谓词中考虑“昂贵的”用户定义代码,并且在某些情况下将选择推迟到连接之后。为了使ADT更加高效,能够在其上定义索引是很有用的。至少,B+树需要扩展到ADT上的索引表达式,而不仅仅是列(有时称为“功能索引”),优化器必须扩展以在适用时选择它们。对于线性阶以外的谓词 (<,>,=), B+-树是不够的,系统需要支持可扩展的索引方案;文献中的两种方法是原始的Postgres可扩展访问方法接口和GiST。[13,37,88,39]
4.7.2 Structured Types and XML
ADT被设计为与关系模型完全兼容——它们不会以任何方式改变基本的关系代数,它们只改变属性值的表达式。然而,多年来,有许多建议对数据库进行更积极的更改,以支持非关系结构化类型:即嵌套集合类型,如数组、集合、树和嵌套元组和/或关系。处理结构化类型(如XML)的方法大致有三种。第一种方法是构建一个自定义数据库系统,对具有结构化类型的数据进行操作;从历史上看,这些尝试被在传统关系DBMS中适应结构化类型的方法所掩盖,在XML的情况下也遵循了这一趋势。第二种方法是将复杂类型视为ADT。例如,可以定义一个关系表,其中包含一个XML类型的列,每行存储一个XML文档。这意味着搜索XML的表达式——例如XPath树匹配模式——以查询优化器不透明的方式执行。第三种方法是DBMS在插入时将嵌套结构“规范化”为一组关系,外键将子对象连接到它们的父对象。这种技术,有时称为“粉碎”XML,将所有数据结构公开给关系框架内的DBMS,但增加了存储开销,并且需要连接以在查询时“重新连接”数据。当今大多数DBMS供应商都提供ADT和粉碎存储选项,并允许数据库设计人员在它们之间进行选择。在XML的情况下,在shredded方法中,提供删除嵌套在同一级别的XML元素之间的排序信息的选项也很常见,这可以通过允许连接重新排序和其他关系优化来提高查询性能。
一个相关的问题是对关系模型进行更适度的扩展以处理嵌套表和元组以及数组。例如,这些在Oracle安装中被广泛使用。设计权衡在许多方面与处理XML的权衡相似。
(注:XML有时被称为“半结构化”数据,因为它对文档的结构没有限制。然而,与自由文本不同,它鼓励结构化,包括排序和嵌套集合等非关系复杂性。在数据库中存储和查询XML的复杂性往往来自处理XML文档的结构,而不是处理文档中的非结构化文本的问题。事实上,许多用于XML查询处理的技术都源于对结构丰富的ODMG对象数据库模型及其OQL查询语言的研究。)
4.7.3 Full-Text Search
传统上,关系数据库在处理丰富的文本数据和通常随之而来的关键字搜索方面是出了名的差。原则上,在数据库中对自由文本进行建模是存储文档、定义与形式元组(word、docentID、位置)的“倒排文件”关系以及在word列上构建B+树索引的简单事情。这大致是任何文本搜索引擎中发生的事情,模块化了一些单词的语言规范化,以及一些额外的每个元组属性以帮助排序搜索结果。但是除了模型之外,大多数文本索引引擎还实现了许多特定于此模式的性能优化,这些优化在典型的DBMS中没有实现。其中包括“非规范化”模式以使每个单词仅出现一次,并带有每个单词出现的列表,即(word, list<docentID,point>)。这允许对列表进行积极的增量压缩(通常称为“发布列表”),这对于文档中单词的典型倾斜(Zipfian)分布至关重要。此外,文本数据库倾向于以数据仓库的方式使用,绕过任何用于事务的DBMS逻辑。人们普遍认为,像上面这样在DBMS中实现文本搜索的简单方法比自定义文本索引引擎运行得慢大约一个数量级。
然而,今天的大多数DBMS要么包含文本索引子系统,要么可以与单独的引擎捆绑在一起来完成这项工作。文本索引工具通常既可以用于全文文档,也可以用于元组中的短文本属性。在大多数情况下,全文索引是异步更新的(“爬取”),而不是事务性地维护;PostgreSQL在提供带有事务更新的全文索引选项方面很不寻常。在一些系统中,全文索引存储在DBMS之外,因此需要单独的工具进行备份和恢复。在关系数据库中处理全文搜索的一个关键挑战是以一种有用和灵活的方式将关系查询(无序和完整的结果集)的语义学与使用关键字(有序和通常不完整的结果)的排序文档搜索联系起来。例如,当每个关系上都有关键字搜索谓词时,尚不清楚如何对两个关系的连接查询的输出进行排序。这个问题在当前实践中仍然相当棘手。给定查询输出的语义,另一个挑战是关系查询优化器推理文本索引的选择性和成本估计,以及判断其答案集在用户交互界面中排序和分页并且可能无法完全检索的查询的适当成本模型。所有报告都显示,许多流行的DBMS都在积极探讨最后一个主题。
4.7.4 Additional Extensibility Issues
除了数据库可扩展性的三个驱动使用场景之外,我们还在引擎中提出了两个核心组件,它们通常可以扩展以用于各种用途。
有许多关于可扩展查询优化器的建议,包括支持IBMDB2优化器的设计,以及支持Tandem和Microsoft优化器的设计。所有这些方案都提供了生成或修改查询计划的规则驱动子系统,并允许独立注册新的优化规则。当向查询执行器添加新功能时,或者当为特定查询重写或计划优化开发新想法时,这些技术有助于更容易扩展优化器。这些通用架构对于启用上述许多特定的可扩展类型功能很重要。[54,68,25]
自早期系统以来出现的另一种跨领域可扩展性形式是数据库能够将远程数据源“包装”在模式中,就好像它们是本机表一样,并在查询处理期间访问它们。这方面的一个挑战是优化器处理不支持扫描的数据源,但会响应为变量赋值的请求;这需要将与索引SARG匹配的优化器逻辑推广到查询谓词。另一个挑战是执行器有效地处理远程数据源,这些数据源在生成输出时可能很慢或突发;这概括了让查询执行器执行异步磁盘I/O的设计挑战,将访问时间可变性增加了一个数量级或更多。[22,92]
4.8 Standard Practice
基本上所有关系数据库查询引擎的粗略架构看起来都类似于System R原型。多年来,查询处理研究和开发一直专注于该框架内的创新,以加速越来越多类别的查询和模式。系统之间的主要设计差异出现在优化器搜索策略(自上而下与自下而上)和查询执行器控制流模型中,尤其是对于无共享和共享磁盘并行性(迭代器和交换运算符与异步生产者/消费者方案)。在更细粒度的层面上,优化器、执行器和访问方法中使用的方案组合存在很大差异,以实现不同工作负载的良好性能,包括联机事务处理、仓储决策支持和OLAP。商业产品中的这种“秘密调味汁”决定了它们在特定情况下的性能,但就第一个近似值而言,所有商业系统在广泛的工作负载中都做得很好,并且在特定工作负载中看起来很慢。[3]
在开源领域,PostgreSQL具有相当复杂的查询处理器,具有传统的基于成本的优化器、广泛的执行算法集以及商业产品中没有的许多可扩展性功能。MySQL的查询处理器要简单得多,它是围绕索引上的嵌套循环连接构建的。MySQL查询优化器专注于分析查询,以确保常见操作是轻量级和高效的——特别是键/外键连接、外部连接到连接的重写以及只要求结果集前几行的查询。通读MySQL手册和查询处理代码并将其与更复杂的传统设计进行比较是很有启发性的,记住MySQL在实践中的高采用率,以及它似乎擅长的任务。[22,92]
4.9 Discussion and Additional Material
由于查询优化和执行的干净模块化,多年来在这种环境中开发了大量的算法、技术和技巧,关系查询处理研究至今仍在继续。令人高兴的是,大多数已经在实践中使用的想法(以及许多没有使用过的想法)都可以在研究文献中找到。查询优化研究的一个很好的起点是Chaudhuri的简短调查。对于查询处理研究,Graefe提供了一个非常全面的调查。[10,24]
除了传统的查询处理之外,近年来还有大量工作将丰富的统计方法整合到大型数据集的处理中。一个自然的扩展是使用抽样或汇总统计来提供聚合查询的数字近似值,可能以不断改进的在线方式。然而,尽管研究结果相当成熟,但这在市场上的应用相对缓慢。Oracle和DB2都提供了简单的基表采样技术,但没有提供涉及多个表的查询的统计稳健估计。大多数供应商没有关注这些特性,而是选择丰富他们的OLAP特性,这限制了可以快速回答的查询,但为用户提供了100%正确的答案。[20,38]
另一个重要但更基本的扩展是在DBMS中包括“数据挖掘”技术。流行的技术包括统计聚类、分类、回归和关联规则。除了研究文献中研究的这些技术的独立实现之外,在将这些技术与丰富的关系查询集成时还存在架构挑战。[14,77]
最后,值得注意的是,更广泛的计算社区最近对数据并行感到兴奋,如谷歌的Map-Reduce、微软的Dryad和雅虎支持的开源Hadoop代码等框架所体现的那样!这些系统非常像shared-nothing-parallel关系查询执行器,由应用程序逻辑的程序员实现自定义查询运算符。它们还包括管理参与节点故障的简单但合理设计的方法,这种故障在大规模范围内很常见。也许这一趋势最有趣的方面是它被创造性地用于计算中的各种数据密集型问题,包括文本和图像处理以及统计方法。看看这些框架的用户是否借鉴了数据库引擎的其他想法将会很有趣——例如,雅虎早期的工作是用声明式查询和优化器扩展Hadoop。建立在这些框架上的创新也可以被并入数据库引擎。
5 Storage Management
目前商业上使用的DBMS存储管理器有两种基本类型:(1)DBMS直接与磁盘的低级块模式设备驱动程序交互(通常称为原始模式访问),或(2)DBMS使用标准操作系统文件系统设施。这一决定会影响DBMS在空间和时间上控制存储的能力。我们依次考虑这两个维度,并继续更详细地讨论存储层次结构的使用。
5.1 Spatial Control
进出磁盘的顺序带宽比随机访问快10到100倍,而且这一比例正在增加。磁盘密度每18个月翻一番,带宽大约随着密度的平方根而上升(并与旋转速度成线性关系)。然而,磁盘臂移动的改善速度要慢得多——大约7%/年。因此,对于DBMS存储管理器来说,在磁盘上放置块以便需要大量数据的查询可以顺序访问它是至关重要的。由于DBMS可以比底层操作系统更深入地了解其工作负载访问模式,因此DBMS架构师对磁盘上数据库块的空间定位进行完全控制是有意义的。[67]
DBMS控制其数据空间局部性的最佳方法是将数据直接存储到“原始”磁盘设备并完全避开文件系统。这之所以有效,是因为原始设备地址通常与存储位置的物理接近度密切对应。大多数商业数据库系统都提供此功能以获得最佳性能。这种技术虽然有效,但确实有一些缺点。首先,它要求DBA将整个磁盘分区专用于DBMS,这使得它们对需要文件系统接口的实用程序(备份等)不可用。其次,“原始磁盘”访问接口通常是特定于操作系统的,这会使DBMS更难移植。然而,这是大多数商业DBMS供应商多年前克服的障碍。最后,RAID、存储区域网络(SAN)和逻辑卷管理器等存储行业的发展变得流行起来。我们现在正处于“虚拟”磁盘设备在当今大多数场景中成为常态的地步——“原始”设备接口实际上正在被设备或软件拦截,这些设备或软件在一个或多个物理磁盘上积极地重新定位数据。因此,DBMS显式物理控制的好处随着时间的推移而被稀释。我们将在第7.3节中进一步讨论这个问题。
原始磁盘访问的另一种选择是DBMS在操作系统文件系统中创建一个非常大的文件,并将数据定位为该文件中的偏移量。该文件本质上被视为磁盘驻留页面的线性数组。这避免了原始设备访问的一些缺点,并且仍然提供了相当好的性能。在大多数流行的文件系统中,如果在空磁盘上分配一个非常大的文件,则该文件中的偏移量将与存储区域的物理距离相当接近。大多数虚拟化存储系统还设计为在附近物理位置的文件中放置接近偏移量。因此,随着时间的推移,使用大文件而不是原始磁盘时失去的相对控制变得不那么重要。使用文件系统接口对时间控制有其他影响,我们将在下一小节中讨论。
作为一个数据点,我们最近比较了使用主要商业DBMS之一的中型系统上的直接原始访问和大文件访问,发现在运行TPC-C基准测试时只有6%的降级,并且对较少的I/O密集型工作负载几乎没有负面影响。DB2报告说,当使用直接I/O(DIO)及其变体(如并发I/O(CIO))时,文件系统开销低至1%。因此,DBMS供应商通常不再推荐原始存储,很少有客户在这种配置下运行。它仍然是主要商业系统中主要用于基准测试使用的受支持功能。[91]
一些商业DBMS还允许将数据库页面大小自定义设置为适合预期工作负载的大小。IBM DB2和Oracle都支持此选项。其他商业系统如Microsoft SQL Server由于由此带来的管理复杂性增加而不支持多个页面大小。如果支持可调页面大小,则所选择的大小应该是文件系统(如果使用原始I/O,则为原始设备)使用的页面大小的倍数。“5分钟规则”论文中讨论了页面大小的适当选择,该论文随后更新为“30分钟规则”。如果正在使用文件系统而不是原始设备访问,则可能需要特殊接口来写入与文件系统不同大小的页面;例如,POSIX mmap/msync调用提供了这种支持。[27]
5.2 Temporal Control:Buffering
除了控制数据在磁盘上的位置之外,数据库管理系统还必须控制数据何时物理写入磁盘。正如我们将在第5节中讨论的,数据库管理系统包含关于何时向磁盘写入块的关键逻辑。大多数操作系统文件系统还提供内置的输入/输出缓冲机制来决定何时对文件块进行读写。如果数据库管理系统使用标准文件系统接口进行写入,操作系统缓冲会通过静默推迟或重新排序写入来混淆数据库管理系统逻辑的意图。这可能会给数据库管理系统带来重大问题。
第一组问题涉及数据库的ACID事务承诺的正确性:如果不明确控制磁盘写入的时间和顺序,DBMS无法保证软件或硬件故障后的原子恢复。正如我们将在第5.3节中讨论的,预写日志协议要求对日志设备的写入必须先于对数据库设备的相应写入,并且在提交日志记录可靠地写入日志设备之前,提交请求不能返回给用户。
操作系统缓冲的第二组问题与性能有关,但对正确性没有影响。现代操作系统通常有一些对预读(推测读取)和后写(延迟、批量写入)的内置支持。这些通常不太适合DBMS访问模式。文件系统逻辑依赖于文件中物理字节偏移的连续性来做出预读决策。DBMS级别的I/O设施可以支持基于未来读取请求的逻辑预测I/O决策,这些请求在SQL查询处理级别已知,但在文件系统级别不易识别。例如,当扫描不一定连续的B+树的叶子(行存储在B+树的叶子中)时,可以请求逻辑DBMS级预读。通过让DBMS提前发出I/O请求,在DBMS逻辑中很容易实现逻辑预读。查询执行计划包含有关数据访问算法的相关信息,并包含有关查询未来访问模式的完整信息。类似地,DBMS可能希望根据将锁争用与I/O吞吐量等问题混合在一起的考虑,自行决定何时刷新日志尾部。这些详细的未来访问模式知识可用于DBMS,但不适用于操作系统文件系统。
最后的性能问题是“双缓冲”和内存副本的高CPU开销。鉴于DBMS必须仔细地进行自己的缓冲以确保正确性,操作系统的任何额外缓冲都是多余的。这种冗余导致了两个开销。首先,它通过有效地减少用于做有用工作的可用存储器来浪费系统内存。其次,它通过导致额外的复制步骤来浪费时间和处理资源:在读取时,数据首先从磁盘复制到操作系统缓冲区,然后再次复制到DBMS缓冲池。在写入时,这两个复制都是不需要的。
在内存中复制数据可能是一个严重的瓶颈。副本会导致延迟,消耗CPU周期,并且会淹没CPU数据缓存。对于那些没有操作或实现过数据库系统的人来说,这一事实通常是惊讶的,他们认为与磁盘I/O相比,主存操作是“免费的”。但是在实践中,经过良好调整的事务处理DBMS的吞吐量通常不受I/O限制。在高端安装中,这是通过购买足够的磁盘和RAM来实现的,以便缓冲池吸收重复的页面请求,并且磁盘I/O在磁盘臂之间以可以满足系统中所有处理器数据需求的速率共享。一旦这种“系统平衡”实现,I/O延迟不再是主要的系统吞吐量瓶颈,剩余的主存瓶颈成为系统中的限制因素。内存副本正在成为计算机架构中的主要瓶颈:这是由于每美元每秒原始CPU周期(遵循摩尔定律)和RAM访问速度(明显落后于摩尔定律)之间的性能演进差距。[67]
操作系统缓冲的问题在数据库研究文献和业界已经有一段时间了。大多数现代操作系统现在都提供钩子(hooks)(例如,POSIX mmap套件调用或平台特定的DIO和CIO API集),以便数据库服务器等程序可以绕过文件缓存的双重缓冲。这确保了在请求时写入磁盘,避免双重缓冲,并且DBMS可以控制页面替换策略。[86]
5.3 Buffer Management
为了提供对数据库页面的有效访问,每个DBMS都在自己的内存空间中实现了一个大型共享缓冲池。在早期,缓冲池是静态分配给管理选择的值,但现在大多数商业DBMS根据系统需求和可用资源动态调整缓冲池大小。缓冲池被组织成一个帧数组,其中每个帧是一个数据库磁盘块大小的内存区域。块从磁盘复制到缓冲池而不改变格式,在内存中以这种本机格式进行操作,然后写回。这种无需翻译的方法避免了“编组”和“解组”数据到磁盘/从磁盘的CPU瓶颈;也许更重要的是,固定大小的帧避开了通用技术导致的外部碎片和压缩的内存管理复杂性。
与缓冲池帧阵列相关联的是一个哈希表,它将(1)当前保存在内存中的页码映射到它们在帧表中的位置,(2)该页在后备磁盘存储上的位置,以及(3)关于该页的一些元数据。元数据包括一个脏位,以指示页面自从磁盘读取后是否发生了变化,以及页面替换策略在缓冲池已满时选择要驱逐的页面所需的任何信息。大多数系统还包括一个引脚计数,以表明页面没有资格参与页面替换算法。当pin计数不为零时,页面被“固定”在内存中,不会被强制磁盘或被盗(stolen)。这允许DBMS的工作线程通过在操作页面之前增加pin计数,然后再递减来固定缓冲池中的页面。其目的是在任何固定时间点固定缓冲池的一小部分。一些系统还提供将表固定在内存中的能力作为管理选项,这可以缩短对小型、大量使用的表的访问时间。但是,固定页面会减少可用于正常缓冲池活动的页面数量,并且随着固定页面百分比的增加会对性能产生负面影响。
关系系统早期的许多研究集中在页面替换策略的设计上,因为DBMS中发现的数据访问模式的多样性使简单的技术无效。例如,某些数据库操作往往需要全表扫描,当扫描的表比缓冲池大得多时,这些操作往往会清除池中所有常用引用的数据。对于这样的访问模式,引用的新近程度是未来引用概率的预测指标是糟糕的,因此众所周知,像LRU和CLOCK这样的操作系统页面替换方案对于许多数据库访问模式来说表现不佳。提出了多种替代方案,包括一些试图通过查询执行计划信息来调整替换策略的方案。今天,大多数系统使用对LRU方案的简单增强来解释全表扫描的情况。一个出现在研究文献中并已在商业系统中实现的是LRU-2。商业系统中使用的另一种方案是让替换策略取决于页面类型:例如,B+树的根可能会被替换为与堆文件中的页面不同的策略。这让人想起Reiter的域分离方案。[86,15,64,75]
最近的硬件趋势,包括64位寻址和内存价格下降,使得非常大的缓冲池在经济上成为可能。这为利用大型主存储器提高效率开辟了新的机会。作为对位,庞大且非常活跃的缓冲池也给重启恢复速度和高效检查点等问题带来了更多挑战。这些主题将在第6节中进一步讨论。
5.4 Standard Practice
在过去十年中,商业文件系统已经发展到可以很好地支持数据库存储系统的程度。在标准使用模型中,系统管理员在DBMS中的每个磁盘或逻辑卷上创建一个文件系统。然后,DBMS在每个文件系统中分配一个大文件,并通过mmap套件等低级接口控制该文件中数据的放置。DBMS基本上将每个磁盘或逻辑卷视为(几乎)连续数据库页面的线性阵列。在这种配置中,现代文件系统为DBMS提供了合理的空间和时间控制,这种存储模型基本上适用于所有数据库系统实现。原始磁盘支持在大多数数据库系统中仍然是一个常见的高性能选项,然而,它的使用范围正在迅速缩小到仅用于性能基准。
5.5 Discussion and Additional Material
数据库存储子系统是一项非常成熟的技术,但近年来出现了许多关于数据库存储的新考虑,这些考虑有可能在很多方面改变数据管理技术。
一个关键的技术变化是闪存作为一种经济上可行的随机存取持久存储技术的出现。从数据库系统研究的早期开始,就一直在讨论由于新的存储技术取代磁盘而导致的DBMS设计的巨大变化。闪存似乎既在技术上可行,又在经济上得到广泛市场的支持,并且相对于磁盘和RAM而言,它提供了一种有趣的中间成本/性能权衡。闪存是三十多年来在这方面取得成功的第一种新的持久性存储介质,因此它的特性可能会对未来的DBMS设计产生重大影响。[28]
最近出现的另一个传统主题是数据库数据的压缩。关于该主题的早期工作集中在磁盘压缩上,以最大限度地减少读取期间的磁盘延迟,并最大限度地提高数据库缓冲池的容量。随着处理器性能的提高和RAM延迟跟不上步伐,考虑即使在计算期间也保持数据压缩变得越来越重要,以便最大限度地提高数据在处理器缓存中的驻留性。但这需要适合数据处理的压缩表示,以及操作压缩数据的查询处理内部。关系数据库压缩的另一个问题是数据库是可重新排序的元组集,而大多数压缩工作都集中在字节流上,而不考虑重新排序。最近关于这个主题的研究表明,在不久的将来数据库压缩有很大的希望。[73]
最后,在传统的关系数据库市场之外,人们对大规模但稀疏的数据存储技术的兴趣增强了。逻辑上有数千列,其中大部分对于任何给定的行都是空的。这些场景通常通过某种属性-值对或三元组来表示。实例包括Google的BigTable[9]、Microsoft的Active Directory和Exchange产品使用的标记列,以及为“Semantic Web.”提出的资源描述框架(RDF)。这些方法的共同点是使用根据数据表的列而不是行来组织磁盘的存储系统。列化存储的想法在最近的一些数据库研究工作中得到了复兴和详细探索。[9,36,89,90]
6 Transactions:Concurrency Control and Recovery
数据库系统经常被指责为无法拆分为可重用组件的庞大的单体软件系统。在实践中,数据库系统——以及实现和维护它们的开发团队——确实分解为独立的组件,它们之间具有文档化的接口。关系查询处理器和事务存储引擎之间的接口尤其如此。在大多数商业系统中,这些组件由不同的团队编写,并且它们之间有明确定义的接口。
DBMS的真正单一部分是事务性存储管理器,它通常包含四个深度交织的组件:
- 用于并发控制的锁管理器。
- 用于恢复的日志管理器。
- 用于暂存数据库I/O的缓冲池。
- 在磁盘上组织数据的访问方法。
在描述数据库系统中事务存储算法和协议的繁琐细节时,已经用了大量墨水。希望了解这些系统的读者至少应该阅读基本的本科数据库教科书、关于ARIES日志协议的期刊文章以及至少一篇关于事务索引并发和日志记录的严肃文章。更高级的读者会想查阅格雷和路透社关于事务的教科书。要真正成为专家,阅读后必须进行实现工作。我们在这里不详述算法和协议,而是调查这些不同组件的作用。我们专注于教科书中经常被忽略的系统基础设施,强调组件之间的相互依赖关系,这些相互依赖关系导致了使简单协议可行的微妙性和复杂性。[72,46,58,30]
6.1 A Note on ACID
许多人都熟悉“ACID事务”这个术语,这是Haerder和Reuter的助记词。ACID代表原子性、一致性、隔离性和持久性。这些术语没有正式定义,也不是组合在一起以保证事务一致性的数学公理。因此,仔细区分术语及其关系并不重要。但是尽管是非正式的,ACID首字母缩略词对于组织关于事务系统的讨论很有用,并且非常重要,我们在这里回顾一下:[34]
- Atomicity 原子性是事务的“全有或全无”保证——要么事务的所有操作都提交,要么没有。
- Consistency 一致性是一种application-specific的保证;SQL完整性约束通常用于在DBMS中捕获这些保证。给定一组约束提供的一致性定义,事务只有在使数据库处于一致状态时才能提交。
- Isolation 隔离是向应用程序编写者保证两个并发事务不会看到彼此正在进行的(未提交的)更新。因此,应用程序不需要“防御性”编码来担心其他并发事务的“脏数据”;它们可以像程序员拥有对数据库的唯一访问权限一样进行编码。
- Durability 持久性是一种保证,即已提交事务的更新将在数据库中对后续事务可见,而不受后续硬件或软件错误的影响,直到它们被另一个已提交事务覆盖。
粗略地说,现代DBMS通过锁定协议实现隔离。持久性通常通过日志记录和恢复来实现。隔离和原子性通过锁定(以防止瞬态数据库状态的可见性)和日志记录(以确保可见数据的正确性)的组合来保证。一致性通过查询执行器中的运行时检查来管理:如果事务的操作违反了SQL完整性约束,则事务将中止并返回错误代码。
6.2 A Brief Review of Serializability
我们从简要回顾数据库并发控制的主要目标开始讨论事务,并在下一节中继续描述用于在大多数多用户事务存储管理器中实现这一概念的两个最重要的构建块:(1)锁定(locking)和(2)锁定(latching)。
(注:lock表示逻辑上锁定,latch表示实际上的锁定。)
可序列化是教科书中定义明确的并发事务正确性概念,它规定多个提交事务的一系列交错操作必须对应于事务的某些串行执行,就好像根本没有并行执行一样。可序列化是一种描述一组事务所需行为的方法。从单个事务的角度来看,隔离是相同的想法。如果一个事务没有看到任何并发异常——ACID的“I”,则该事务被称为隔离执行。
可序列化由DBMS并发控制模型强制执行。并发控制实施有三种广泛的技术。这些在教科书和早期调查论文中有很好的描述,但我们在这里非常简要地回顾了它们:[7]
- Strict two-phase locking 严格的两阶段锁定(2PL):事务在读取每个数据记录之前获取一个共享锁,在写入每个数据项之前获取一个独占锁。所有锁都保持到事务结束,此时它们都以原子方式释放。事务在等待获取锁时阻塞在等待队列上。
- Multi-Version Concurrency Control 多版本并发控制(MVCC):事务不持有锁,而是保证在过去的某个时间对数据库状态的一致视图,即使自该固定时间点以来行已更改。
- Optimistic Concurrency Control 乐观并发控制(OCC):允许多个事务在不阻塞的情况下读取和更新一个项目。相反,事务维护其读取和写入的历史记录,并且在提交事务之前检查历史记录是否存在可能发生的隔离冲突;如果找到任何冲突,则回滚其中一个冲突事务。
大多数商业关系DBMS通过2PL实现完全的可串行性。锁管理器是负责为2PL提供设施的代码模块。
(注:基于MVCC的SSI实现冲突可串行的论文发表于2008年,本篇论文发表于2007年。)
为了减少锁定和锁定冲突,一些DBMS支持MVCC或OCC,通常作为2PL的附加组件。在MVCC模型中,不需要读锁,但这通常是以不提供完全可串行性为代价的,我们将在第4.2.1节中讨论。为了避免在读后面阻塞写入,允许在行的先前版本被保存后继续写入,或者保证可以通过其他方式快速获得。正在进行的读事务继续使用前一行值,就好像它被锁定并被阻止更改一样。在商业MVCC实现中,这个稳定的读值被定义为读事务开始时的值或该事务最近的SQL语句开始时的值。
虽然OCC避免了等待锁,但在事务之间发生真正的冲突时,它可能会导致更高的惩罚。在处理跨事务的冲突时,OCC类似于2PL,只是它将2PL中的锁等待转换为事务回滚。在冲突不常见的情况下,OCC表现非常好,避免了过于保守的等待时间。然而,由于冲突频繁,过度的回滚和重试会对性能产生负面影响,并使其成为一个糟糕的选择。[2]
6.3 Locking and Latching
数据库锁只是系统中约定用来表示DBMS管理的物理项(如磁盘页)或逻辑项(如元组、文件、卷)的名称。请注意,任何名称都可以有一个与之关联的锁——即使该名称代表一个抽象概念。锁定机制只是提供了一个注册和检查这些名称的地方。每个锁都与一个事务相关联,每个事务都有一个唯一的事务ID。锁有不同的锁“模式”,这些模式与锁模式兼容性表相关联。在大多数系统中,这种逻辑基于Gray关于锁的颗粒度的论文[29]中介绍的众所周知的锁模式。该论文还解释了商业系统中实现的分层锁。分层锁允许使用单个锁来锁定整个表,同时有效且正确地支持同一表中的行颗粒度锁。
锁管理器支持两个基本调用;lock(lockname, transactionID,mode)和remove_transaction(transactionID)。请注意,由于严格的2PL协议,不应该有单独的调用来单独解锁资源——删除事务()调用将解锁与事务关联的所有资源。然而,正如我们在第5.2.1节中讨论的,SQL标准允许较低程度的事务隔离,因此也需要 **unlock(lockname, transactionID)调用。还有一个lock_upgrade(lockname、transactionID、newmode)调用,以允许事务以两阶段方式“升级”到更高的锁模式(例如,从共享模式到独占模式),而无需丢弃和重新获取锁。此外,一些系统还支持conditional_lock(lockname、transactionID、mode)**调用。conditional_lock() 调用总是立即返回,并指示它是否成功获取锁。如果没有成功,则调用DBMS线程不会排队等待锁。[60]中讨论了条件锁在索引并发中的使用。
为了支持这些调用,锁管理器维护两个数据结构。维护一个全局锁表来保存锁名及其相关信息。锁表是一个由锁名(散列函数)键控的动态哈希表。与每个锁相关联的是指示锁模式的模式标志,以及锁请求对的等待队列(transactionID、mode)。此外,锁管理器维护一个由transactionID键控的事件表,其中包含每个事务T的两个项目:(1)指向T的DBMS线程状态的指针,以允许T的DBMS线程在获取它正在等待的任何锁时被重新调度,以及(2)指向锁表中所有T的锁请求的指针列表,以方便删除与特定事务相关的所有锁(例如,在事务提交或中止时)。
在内部,锁管理器使用死锁检测器DBMS线程,该线程定期检查锁表以检测等待周期(DBMS工作人员的循环,每个工作人员都在等待下一个循环并形成一个循环)。检测到死锁后,死锁检测器中止其中一个死锁事务。决定中止哪个死锁事务是基于研究文献[76]中研究过的启发式方法,在无共享和共享磁盘系统中,要么需要分布式死锁检测[61],要么需要更原始的基于超时的死锁检测器。Gray和Reuter的文本[30]中给出了对锁管理器实现的更详细描述。
作为数据库锁的辅助,还提供了更轻量级的锁存器用于互斥。锁存器(Latch)更类似于监视器[41]或信号量,而不是锁;它们用于提供对内部DBMS数据结构的独占访问。例如,缓冲池页表具有与每个帧关联的锁存器,以保证在任何时候只有一个DBMS线程替换给定的帧。锁存器用于锁的实现,并短暂地稳定可能被并发修改的内部数据结构。
锁存器(Latch)在许多方面与锁(Lock)不同:
- 锁(Lock)保存在锁表中并通过哈希表定位;锁存器(Latch)驻留在它们保护的资源附近的内存中,并通过直接寻址进行访问。
- 在严格的2PL实现中,锁受严格的2PL协议的约束。基于特殊情况的内部逻辑,可以在事务期间获取或丢弃锁存器。
- 锁获取完全由数据访问驱动,因此锁获取的顺序和生命周期主要掌握在应用程序和查询优化器手中。锁存器由DBMS内部的专用代码获取,DBMS内部代码有计划地发出锁存器请求和释放。
- 允许锁产生死锁,通过事务重启检测和解决锁死锁。必须避免锁存器死锁;锁存器死锁的发生代表DBMS代码中的bug。
- 锁存器是使用原子硬件指令实现的,或者在极少数情况下,在不可用的情况下,通过操作系统内核中的互斥实现。
- 锁存器调用最多需要几十个CPU周期,而锁请求需要数百个CPU周期。
- 锁管理器跟踪事务持有的所有锁,并在事务抛出异常时自动释放锁,但操作锁存器的内部DBMS例程必须仔细跟踪它们,并将手动清理作为异常处理的一部分。
- 锁存器不会被跟踪,因此如果任务出现故障,则无法自动释放锁存器。
latch API支持例程latch(object, mode)、unlatch(object)和condition_latch(object,mode)。在大多数DBMS中,锁存器模式的选择仅包括共享或独占。锁存器维护一种模式,以及等待锁存器的DBMS线程的等待队列。latch和unlatch调用按预期工作。conditional_latch()调用类似于上述conditional_lock()调用,也用于索引并发[60]。
6.3.1 Transaction Isolation Levels
在事务概念发展的早期,试图通过提供比可串行性“弱”的语义来增加并发。挑战在于在这些情况下提供语义学的可靠定义。在这方面最有影响力的努力是格雷早期关于“一致性程度”的工作[29]。这项工作试图提供一致性程度的声明性定义和锁定方面的实现。受这项工作的影响,ANSI SQL标准定义了四个“隔离级别”:
- READ UNCOMMITTED:事务可以读取任何版本的数据,无论是否已提交。这是在锁定实现中通过在不获取任何锁的情况下继续读取请求来实现的。(注:在所有隔离级别中,写请求之前都有写锁,这些锁一直保存到事务结束。)
- READ COMMITTED:事务可以读取任何已提交版本的数据。重复读取对象可能会导致不同的(已提交的)版本。这是通过读取请求在访问对象之前获取读锁,并在访问后立即解锁来实现的。
- REPEATABLE READ:事务将只读取已提交数据的一个版本;一旦事务读取一个对象,它将始终读取该对象的相同版本。这是通过读取请求在访问对象之前获取读锁并将锁保持到事务结束来实现的。
- SERIALIZABLE:保证完全可序列化访问。
乍一看,REPEATABLE READ似乎提供了完全的可串行性,但事实并非如此。在System R项目[3]的早期,出现了一个被称为“幻影问题”的问题。在幻影问题中,事务在同一事务中使用相同的谓词多次访问关系,但在重新访问时看到了第一次访问时没有看到的新的“幻影”元组。这是因为元组级颗粒度的两阶段锁定不会阻止将新元组插入表中。表的两阶段锁定可以防止幻象,但在事务仅通过索引访问几个元组的情况下,表级锁定可能会受到限制。当我们讨论索引中的锁定时,我们将在第5.4.3节中进一步研究这个问题。
商业系统通过基于锁的并发控制实现提供了上述四个隔离级别。不幸的是,正如Berenson等人[6]所指出的,Gray的早期工作和ANSI标准都没有实现提供真正声明性定义的目标。两者都以微妙的方式依赖于锁定方案用于并发控制的假设,而不是乐观[47]或多版本[74]并发方案。这意味着所提出的语义定义不明确。鼓励感兴趣的读者阅读Berenson论文,该论文讨论了SQL标准规范中的一些问题,以及Adya等人[1]的研究,该研究为该问题提供了一种新的、更清晰的方法。
除了标准的ANSISQL隔离级别之外,各种供应商还提供了在特定情况下很受欢迎的附加级别。
- CURSOR STABILITY:此级别旨在解决READ COMMITTED的“丢失更新”问题。考虑两个事务T1和T2。T1以READ COMMITTED模式运行,读取对象X(例如银行账户的价值),记住它的值,然后根据记住的值写入对象X(例如在原始账户价值上添加100美元)。如果T2的操作发生在T1的读和T1的写之间,那么T2更新的效果将丢失——在我们的示例中,帐户的最终价值将增加100美元,而不是所需的减少200美元。CURSOR STABILITY模式下的事务持有查询游标上最近读取的项目的锁;当游标移动(例如,通过另一个FETCH)或事务终止时,锁会自动丢弃。CURSOR STABILITY允许事务对单个项目进行读写序列,而不会干预来自其他事务的更新。
- SNAPSHOT ISOLATION:以SNAPSHOT ISOLATION模式运行的事务在事务开始时存在的数据库版本上运行;其他事务的后续更新对事务不可见。这是MVCC在生产数据库系统中的主要用途之一。当事务开始时,它从单调递增的计数器中获取唯一的开始时间戳;当它提交时,它从计数器中获取唯一的结束时间戳。只有当没有具有重叠开始/结束事务对的其他事务写入该事务也写入的数据时,事务才会提交。这种隔离模式依赖于多版本并发实现,而不是锁定。然而,这些方案通常在支持SNAPSHOT ISOLATION的系统中共存。
- READCONSISTENCY:这是Oracle定义的MVCC方案;它与SNAPSHOT ISOLATION略有不同。在Oracle方案中,每个SQL语句(单个事务中可能有许多语句)都看到语句开始时最近提交的值。对于从游标中获取的语句,游标集基于打开时的值。这是通过维护单个元组的多个逻辑版本来实现的,单个事务可能引用单个元组的多个版本。Oracle不会存储可能需要的每个版本,而是只存储最新版本。如果需要旧版本,它会通过获取当前版本并根据需要应用撤消日志记录来“回滚”来生成旧版本。修改是通过长期写锁来维护的,因此当两个事务想要写入同一个对象时,第一个写入者“获胜”,第二个写入者必须等待第一个写入者的事务完成,然后才能继续写入。相比之下,在SNAPSHOT ISOLATION中,第一个提交者“获胜”而不是第一个写入者。
弱隔离方案可以提供比完全可串行性更高的并发性,因此,一些系统甚至使用弱一致性作为默认值。例如,MicrosoftSQLServer默认为READ COMMITTED。缺点是不能保证隔离(在ACID意义上)。因此,应用程序编写者需要推理方案的微妙之处,以确保其事务正确运行。考虑到方案的操作定义语义,这可能很棘手,并且可能导致应用程序更难在DBMS之间移动。
6.4 Log Manager
日志管理器负责维护已提交事务的持久性,促进已中止事务的回滚以确保原子性,以及从系统故障或无序关闭中恢复。为了提供这些功能,日志管理器在磁盘上维护一系列日志记录,在内存中维护一组数据结构。为了支持崩溃后的正确行为,驻留在内存中的数据结构显然需要从日志和数据库中的持久数据中重新创建。
数据库日志记录是一个极其复杂且注重细节的主题。关于数据库日志记录的规范参考是关于ARIES[59]的期刊论文,数据库专家应该熟悉该论文的细节。ARIES的论文不仅解释了日志记录协议,还提供了替代设计可能性的讨论,以及它们可能导致的问题。这使得阅读内容密集,但最终是有益的。作为一个更容易消化的介绍,Ramakrishnan和Gehrke教科书[72]提供了基本ARIES协议的描述,没有侧面讨论或改进。在这里我们讨论恢复中的一些基本思想,并试图解释教科书和期刊描述之间的复杂性差距。
数据库恢复的标准主题是使用预写日志(WAL)协议。WAL协议由三个非常简单的规则组成:
- 对数据库页面的每次修改都应该生成一条日志记录,并且必须在刷新数据库页面之前将日志记录刷新到日志设备。
- 数据库日志记录必须按顺序刷新;在日志记录 r 之前的所有日志记录都被刷新之前,不能刷新日志记录 r。
- 在事务提交请求时,必须在提交请求成功返回之前将提交日志记录刷新到日志设备。
许多人只记得这些规则中的第一条,但这三条都是正确行为所必需的。
第一条规则确保在事务中止的情况下可以撤消未完成事务的操作,以确保原子性。规则(2)和(3)的组合确保持久性:如果已提交事务的操作尚未反映在数据库中,则可以在系统崩溃后重做它们。
鉴于这些简单的原则,高效的数据库日志记录如此微妙和详细令人惊讶。然而,在实践中,上述简单的故事因对极端性能的需求而变得复杂。挑战在于保证提交事务的“快速路径”的效率,同时为中止的事务提供高性能回滚,并在崩溃后快速恢复。当添加application-specific优化时,日志记录会变得更加复杂,例如,为了支持只能递增或递减的字段(“托管事务”)的改进性能。
为了最大限度地提高快速路径的速度,大多数商业数据库系统都以Haerder和Reuter称为“DIRECT, STEAL/NOT-FORCE”[34]的模式运行:(a)就地更新数据对象,(b)即使未固定的缓冲池帧包含未提交的数据,它们也可能被“窃取”(以及写入磁盘的修改数据页),以及(c)在提交请求返回给用户之前,缓冲池页面不需要“强制”(刷新)到数据库。这些策略将数据保存在DBA选择的位置,并且它们赋予缓冲管理器和磁盘调度程序完全的自由度来决定内存管理和I/O策略,而不考虑事务正确性。这些特性可能具有很大的性能优势,但需要日志管理器有效地处理撤消从中止事务中刷新被盗页面以及重做对崩溃时丢失的已提交事务的非强制页面的更改的所有细微之处。一些DBMS使用的一种优化是将DIRECT、STEAL/NOT-FORCE系统的可扩展性优势与DIRECT NOT-STEAL/NOT-FORCE系统的性能结合起来。在这些系统中,除非缓冲池中没有干净的页面,否则页面不会被stolen,在这种情况下,系统会退化回STEAL策略,并增加上述额外开销。
日志记录中的另一个快速路径挑战是保持日志记录尽可能小,以增加日志I/O活动的吞吐量。自然的优化是记录逻辑操作(例如,“将(Bob,$25000)插入EMP”)而不是物理操作(例如,通过元组插入修改的所有字节范围的残影,包括堆文件和索引块上的字节。)权衡是重做和撤消逻辑操作的逻辑变得非常复杂。这会严重降低事务中止和数据库恢复期间的性能。(注:另请注意,如果逻辑日志记录需要参与撤消处理,它们必须始终具有众所周知的逆函数。)在实践中,混合使用物理和逻辑日志记录(所谓的“physiological”日志记录)。在ARIES中,物理日志记录通常用于支持REDO,逻辑日志记录用于支持UNDO。这是ARIES规则的一部分,即在恢复期间“重复历史”以达到崩溃状态,然后从该点回滚事务。
崩溃恢复是在系统故障或意外关闭后将数据库恢复到一致状态所必需的。如上所述,理论上恢复是通过重放历史记录并从第一条日志记录一直步进到最近的记录来实现的。这种技术是正确的,但效率不高,因为日志可能任意长。不是从第一条日志记录开始,而是从这两条日志记录中最旧的一条开始恢复来获得正确的结果:(1)描述缓冲池中最早更改为最旧脏页的日志记录,(2)代表系统中最旧事务开始的日志记录。该点的序列号称为恢复日志序列号(恢复LSN)。由于计算和记录恢复LSN会产生开销,并且由于我们知道恢复LSN是单调增加的,因此我们不需要使其始终保持最新。相反,我们以称为检查点的周期性间隔计算它。
原始的检查点将强制所有脏缓冲池页面,然后计算和存储恢复LSN。对于大型缓冲池,这可能会导致几秒钟的延迟来完成待处理页面的I/O。因此,需要一个更有效的检查点“模糊”方案,以及通过处理尽可能少的日志来正确地将检查点提升到最新一致状态的逻辑。ARIES使用了一个非常聪明的方案,其中实际的检查点记录非常小,包含足够的信息来启动日志分析过程,并能够重新创建崩溃时丢失的主存数据结构。 在ARIES模糊检查点期间,会计算恢复LSN,但不需要同步写入缓冲池页面。使用单独的策略来确定何时异步写入旧的脏缓冲池页面。
请注意,回滚需要写入日志记录。这可能会导致困难的情况,即由于日志空间用完,正在进行的事务无法继续,但也无法回滚。这种情况通常通过空间预留方案来避免,但是,随着系统通过多个版本的发展,这些方案很难获得并保持正确。
最后,由于数据库不仅仅是磁盘页面上的一组用户数据元组,日志记录和恢复的任务更加复杂;它还包括各种“物理”信息,允许它管理其内部基于磁盘的数据结构。我们将在下一节的索引日志上下文中讨论这一点。
6.5 Locking and Logging in Indexes
索引是访问数据库中数据的物理存储结构。索引本身对数据库应用程序开发人员是不可见的,除非它们提高了性能或强制执行唯一性约束。开发人员和应用程序不能直接观察或操作索引中的条目。这允许通过更有效(和复杂)的事务方案来管理索引。索引并发和恢复需要保留的唯一不变量是索引始终从数据库返回事务一致的元组。
6.5.1 Latching in B+-Trees
关于这个问题,一个经过充分研究的例子出现在B+树锁存中。B+树由通过缓冲池访问的数据库磁盘页组成,就像数据页一样。因此,索引并发控制的一种方案是在索引页上使用两阶段锁。这意味着每个触及索引的事务都需要锁定B+树的根,直到提交时间——这是限制并发的方法。已经开发了各种基于锁存器的方案来解决这个问题,而无需在索引页上设置任何事务锁。这些方案中的关键见解是,只要所有并发事务继续在叶子上找到正确的数据,就可以以非事务方式修改树的物理结构(例如拆分页面)。大致有三种方法:
- Conservative schemes 保守方案:只有在可以保证在使用页面内容时不发生冲突的情况下,才允许希望访问相同页面的多个事务。比如一个冲突:是一个读取事务,它想要遍历树的一个完全打包的内部页面,而并发插入事务在该页面下方运行,并且可能需要拆分该页面[4]。与下面的最新想法相比,这些保守方案牺牲了太多的并发。
- Latch-coupling schemes锁存器耦合方案:树遍历逻辑在访问每个节点之前对其进行锁存器,只有当要访问的下一个节点被成功锁存器时才会解锁一个节点。这种方案有时被称为“螃蟹”锁,因为“抓住”树中的一个节点,“抓住”它的子节点,释放父节点,然后重复。锁存器耦合用于一些商业系统;IBM的ARIES IM版本描述得很好[60]。ARIES-IM包括一些相当复杂的细节和角落情况——有时它必须在拆分后重新启动遍历,甚至设置(非常短期的)树范围的锁存器。
- Right-link schemes 右链接方案:简单的附加结构被添加到B+树中,以最小化对锁存器和重新遍历的要求。特别是,从每个节点到其右侧邻居添加了一个链接。在遍历期间,右链接方案没有锁存器耦合——每个节点都被锁存器、读取和取消锁存器。右链接方案的主要直觉是,如果遍历事务跟随指向节点 n 的指针并发现 n 在此期间被拆分,遍历事务可以检测到这一事实,并通过右链接“向右移动”以在树中找到新的正确位置[46,50]。一些系统也支持使用反向链接的反向遍历。
Kornacker等人[46]详细讨论了锁存器耦合和右链接方案之间的区别,并指出锁存器耦合仅适用于B+树,不适用于更复杂数据上的索引树,例如,没有单一线性顺序的地理数据。PostgreSQL通用搜索树(GiST)实现基于Kornacker等人的可扩展右链接方案。
6.5.2 Logging for Physical Structures
除了特殊情况下的并发逻辑,索引还使用特殊情况下的日志记录逻辑。这种逻辑使日志记录和恢复更加高效,但代价是增加了代码复杂性。主要思想是,当关联的事务中止时,结构索引更改不需要撤消;这种更改通常对其他事务看到的数据库元组没有影响。例如,如果在插入事务期间拆分了B+树页面,但随后中止了,则在中止处理期间没有迫切需要撤消拆分。
这就提出了将一些日志记录标记为仅重做的挑战。在日志的任何撤消处理期间,仅重做的更改都可以保留在原处。ARIES为这些场景提供了一种优雅的机制,称为嵌套顶部操作,它允许恢复过程在恢复期间“跳过”日志记录以进行物理结构修改,而无需任何特殊情况代码。
同样的想法也用于其他上下文,包括堆文件。插入堆文件可能需要在磁盘上扩展文件。为了捕获这一点,必须对文件的范围映射进行更改。这是磁盘上的数据结构,指向构成文件的连续块的运行。如果插入事务中止,则不需要撤消对范围映射的这些更改。文件变得更大这一事实是事务上不可见的副作用,实际上可能有助于吸收未来的插入流量。
6.5.3 Next-Key Locking:Physical Surrogates for Logical Properties
我们以最后一个索引并发问题结束本节,该问题说明了一个微妙但重要的想法。挑战在于提供完全可串行性(包括幻像保护),同时允许tuple级别的锁和索引的使用。请注意,这种技术仅适用于完全可串行性,在宽松的隔离模型中不需要或使用。
当事务通过索引访问元组时,可能会出现幻读问题。在这种情况下,事务通常不会锁定整个表,只是锁定通过索引访问的表中的元组(例如,“名称BETWEEN'Bob'AND'Bobby'”)。在没有表级锁的情况下,其他事务可以自由地向表中插入新的元组(例如,“Name='Bobbie'”)。当这些新插入属于查询谓词的值范围时,它们将通过该谓词出现在后续访问中。请注意,幻像问题与数据库元组的可见性有关,因此是锁的问题,而不仅仅是锁存器的问题。原则上,需要的是能够以某种方式锁定原始查询的搜索谓词表示的逻辑空间,例如,按字典顺序落在“Bob”和“Bobby”之间的所有可能字符串的范围。不幸的是,谓词锁定很昂贵,因为它需要一种方法来比较任意谓词的重叠。这不能使用基于哈希的锁表[3]来完成。
解决B+树中幻象问题的常用方法称为next-key锁定。在next-key锁定中,修改索引插入代码,以便插入索引键为k的元组必须在索引中存在的next-key元组上分配排他锁,其中next-key元组的最低键大于k。该协议确保后续插入不会出现在之前返回给活动事务的两个元组之间。它还确保元组不能插入到之前返回的最低键元组的正下方。例如,如果在第一次访问时没有找到“Bob”键,则在同一事务中的后续访问中不应找到“Bob”键。仍然存在一种情况:在之前返回的最高键元组上插入元组。为了防止这种情况,next-key锁定协议要求读取事务也获得索引中next-key元组的共享锁。在这种情况下,next-key元组是不满足查询谓词的最小键元组。更新在逻辑上表现为删除后跟插入,尽管优化既可能又常见。
Next-key 锁定虽然有效,但确实会出现过度锁定,这在某些工作负载中可能会出现问题。例如,如果我们扫描从键1到键10的记录,但被索引的列只存储了键1、5和100,那么从1到100的整个范围都将被读锁定,因为100是10之后的下一个键。
Next-key锁定不仅仅是一种巧妙的技巧。它是使用物理对象(当前存储的元组)作为逻辑概念(谓词)代理的一个例子。好处是简单的系统基础设施,如基于哈希的锁表,可以用于更复杂的目的,只需修改锁协议。当语义信息可用时,复杂软件系统的设计者应该将这种逻辑代理的一般方法保存在他们的“技巧袋”中。
6.6 Interdependencies of Transactional Storage
我们在本节的早些时候声称事务存储系统是单片的、深度交织的系统。在本节中,我们将讨论事务存储系统的三个主要方面之间的一些相互依赖关系:并发控制、恢复管理和访问方法。在一个更快乐的世界里,可以在这些模块之间识别窄API,从而允许这些API背后的实现可交换。我们在本节中的示例表明这并不容易做到。我们不打算在此提供相互依存关系的详尽清单;生成和证明这样一份清单的完整性将是一项非常具有挑战性的工作。然而,我们确实希望说明事务存储的一些扭曲逻辑,从而证明商业DBMS中由此产生的单体实现是合理的。
我们首先考虑并发控制和恢复,而不考虑访问方法的进一步复杂化。即使有了这种简化,组件也是深深交织在一起的。并发和恢复之间关系的一个表现是,预写日志对锁定协议做出了隐含的假设。预写日志记录需要严格的两阶段锁定,并且使用非严格的两阶段锁定将无法正确运行。要了解这一点,请考虑在回滚中止的事务期间会发生什么。恢复代码开始处理中止事务的日志记录,撤消其修改。通常,这需要更改事务先前修改的页面或元组。为了进行这些更改,事务需要在这些页面或元组上有锁。在非严格2PL方案中,如果事务在中止之前丢弃任何锁,它可能无法重新获取完成回滚过程所需的锁。
访问方法使事情变得更加复杂。采用教科书式的访问方法算法(例如线性散列[53]或R-树[32])并在事务系统中实现正确的、高并发的、可恢复的版本是一个重大的智力和工程挑战。出于这个原因,大多数领先的DBMS仍然只实现堆文件和B+树作为事务保护的访问方法;PostgreSQL的GiST实现是一个明显的例外。正如我们上面针对B+树所说明的,事务索引的高性能实现包括用于锁存、锁定和日志记录的复杂协议。严肃的DBMS中的B+树充斥着对并发和恢复代码的调用。即使是像堆文件这样的简单访问方法也有一些棘手的并发和恢复问题,这些问题围绕着描述其内容的数据结构(例如范围映射)。这种逻辑并不适用于所有访问方法——它在很大程度上是根据访问方法的特定逻辑及其特定实现定制的。
访问方法中的并发控制仅针对面向锁定的方案得到了很好的发展。其他并发方案(例如,乐观或多版本并发控制)通常根本不考虑访问方法,或者只是以一种随意和不切实际的方式提及它们[47]。因此,对于给定的访问方法实现,混合和匹配不同的并发机制是很困难的。
访问方法中的恢复逻辑是特定于系统的:访问方法日志记录的时间和内容取决于恢复协议的细节,包括结构修改的处理(例如,它们是否在事务回滚时被撤消,如果不是,如何避免撤消),以及物理和逻辑日志的使用。即使对于像B+树这样的特定访问方法,恢复和并发逻辑也是交织在一起的。 在一个方向上,恢复逻辑依赖于并发协议:如果恢复管理器必须恢复树的物理上一致的状态,那么它需要知道可能会出现哪些不一致的状态,以适当地将这些状态与日志记录联系起来以实现原子性(例如,通过嵌套的顶部操作)。相反,访问方法的并发协议可能依赖于恢复逻辑。例如,B+树的右链接方案假设树中的页面在分裂后永远不会“重新合并”。这种假设要求恢复方案使用嵌套顶部操作等机制来避免撤消由中止事务产生的拆分。
这张图片(注:?图片在哪?)中的一个亮点是缓冲区管理与存储管理器的其他组件相对隔离得很好。只要页面被正确固定,缓冲区管理器就可以自由地封装其其余逻辑并根据需要重新实现它。例如,缓冲区管理器可以自由选择要替换的页面(因为STEAL属性)和页面刷新的调度(因为NOTFORCE属性)。当然,实现这种隔离是并发和恢复复杂性的直接原因。所以这个地方可能没有看起来那么亮。
6.7 Standard Practice
今天的所有生产数据库都支持ACID事务。通常,它们使用预写日志记录来实现持久性,并使用两阶段锁定来实现并发控制。PostgreSQL是一个例外,它始终使用多版本并发控制。(注:不过好在2008年SSI的理论,让PostgreSQL的可用性大大增加,非常值得学习。)Oracle率先有限地使用多版本并发和锁定,作为提供轻松一致性模型的一种方式,如快照隔离和读取一致性;这些模式在用户中的流行导致它们在不止一个商业DBMS中被采用,在Oracle中这是默认设置。B+树索引是所有生产数据库的标准,大多数商业数据库引擎都提供某种形式的多维索引,要么嵌入在系统中,要么作为“插件”模块。只有PostgreSQL通过其GiST实现提供高并发多维和文本索引。
MySQL的独特之处在于,它积极支持各种存储管理器,以至于DBA经常为同一数据库中的不同表选择不同的存储引擎。它的默认存储引擎MyISAM仅支持表级锁定,但被认为是以读为主的工作负载的高性能选择。对于读/写工作负载,推荐使用InnoDB存储引擎;它提供行级锁定。(InnoDB几年前被Oracle收购,但目前仍然是开源的,可以免费使用。)这两个MySQL存储引擎都没有提供为System R[29]开发的众所周知的分层锁定方案,尽管它在其他数据库系统中普遍使用。这使得MySQL DBA在InnoDB和MyISAM之间的选择变得棘手,在一些混合工作负载的情况下,这两个引擎都不能提供良好的锁定颗粒度,这要求DBA开发一个使用多个表和/或数据库复制的物理设计,以支持扫描和高选择性索引访问。MySQL还支持主存和基于集群的存储的存储引擎,一些第三方供应商已经宣布了符合MySQL的存储引擎,但今天MySQL用户群中的大部分精力都集中在MyISAM和InnoDB上。
6.8 Discussion and Additional Material
事务机制现在是一个非常成熟的话题,多年来,大多数可能的技巧都以一种或另一种形式进行了尝试;新设计往往涉及现有想法的排列和组合。也许这一领域最明显的变化是内存价格的快速下降。这增加了将数据库中大部分“热门”部分保留在内存中并以内存速度运行的动机,这使得将数据经常刷新到持久存储以保持较低重启时间的挑战变得复杂。闪存在事务管理中的作用是这种不断发展的平衡行为的一部分。
近年来一个有趣的发展是在操作系统社区中相对广泛地采用了预写日志记录,通常是在日志文件系统的标题下。这些已经成为当今基本上所有操作系统的标准选项。由于这些文件系统通常仍然不支持文件数据的事务,因此了解它们如何以及在哪里使用预写日志记录来实现持久性和原子性是很有趣的。感兴趣的读者可以参考[62,71]进行进一步阅读。这方面另一个有趣的方向是关于静态的工作[78],它试图更好地模块化ARIES风格的日志记录和恢复,并使其可供系统程序员用于各种用途。
7 Shared Components
在本节中,我们将介绍几乎所有商业DBMS中都存在的许多共享组件和实用程序,但在文献中很少讨论。
7.1 Catalog Manager
数据库目录保存有关系统中数据的信息,是元数据的一种形式。目录记录系统中基本实体的名称(用户、模式、表、列、索引等)及其关系,并且本身作为一组表存储在数据库中。通过将元数据保持在与数据相同的格式,系统变得更加紧凑和易于使用:用户可以使用相同的语言和工具来调查他们用于其他数据的元数据,管理元数据的内部系统代码与管理其他表的代码基本相同。 这种代码和语言重用是一个重要的教训,在早期实现中经常被忽视,通常是开发人员后来的重大遗憾。其中一位作者在过去十年中再次在工业环境中目睹了这个错误。
出于效率原因,基本目录数据的处理方式与普通表有所不同。目录的高流量部分通常根据需要在主存中具体化,通常是在将目录的平面关系结构“非规范化”为主存对象网络的数据结构中。内存中缺乏数据独立性是可以接受的,因为内存中的数据结构仅由查询解析器和优化器以风格化的方式使用。其他目录数据在解析时缓存在查询计划中,通常也是以适合查询的非规范化形式。此外,目录表经常受到特殊情况事务技巧的影响,以最小化事务处理中的“热点”。
在商业应用中,目录可以变得非常庞大。例如,一个主要的ERP系统应用程序有60,000多个表,每个表有4到8列,通常每个表有两到三个索引。
7.2 Memory Allocator
DBMS内存管理的教科书演示往往完全集中在缓冲池上。在实践中,数据库系统也为其他任务分配大量内存。对这些内存的正确管理既是编程负担,也是性能问题。Selinger风格的查询优化可以使用大量内存,例如,在动态编程期间建立状态。哈希连接和排序等查询运算符在运行时分配大量内存。通过使用基于上下文的内存分配器,商业系统中的内存分配变得更加高效和易于调试。
内存上下文(memory context)是一种内存数据结构,它维护连续虚拟内存区域的列表,通常称为内存池。每个区域都可以有一个小标头,其中包含上下文标签或指向上下文标头结构的指针。内存上下文的基本API包括对以下内容的调用:
- Create a context with a given name or tyep 创建具有给定名称或类型的上下文。上下文类型可能会建议分配器如何有效地处理内存分配。例如,查询优化器的上下文通过小增量增长,而哈希连接的上下文分几批分配内存。基于这些知识,分配器可以选择一次分配更大或更小的区域。
- Allocate a chunk of memory within a context 在上下文中分配一块内存。此分配将返回一个指向内存的指针(很像传统的malloc()调用)。该内存可能来自上下文中的现有区域。或者,如果任何区域中不存在这样的空间,分配器将向操作系统请求一个新的内存区域,标记它,并将其链接到上下文中。
- Delete a chunk of memory within a context 删除上下文中的一块内存。这可能会也可能不会导致上下文删除相应的区域。从内存上下文中删除有些不寻常。更典型的行为是删除整个上下文。
- Delete a context 删除上下文。这首先释放与上下文关联的所有区域,然后删除上下文标头。
- Reset a context 重置上下文。这将保留上下文,但将其返回到原始创建状态,通常通过释放所有先前分配的内存区域。
内存上下文提供了重要的软件工程优势。最重要的是,它们作为垃圾回收机制的较低级别、程序员可控的替代方案。例如,编写优化器的开发人员可以在优化器上下文中为特定查询分配内存,而无需担心稍后如何释放内存。当优化器选择了最佳计划时,它可以从查询的单独执行器上下文中将计划复制到内存中,然后简单地删除查询的优化器上下文。这省去了编写代码来仔细遍历所有优化器数据结构并删除其组件的麻烦。它还避免了此类代码中的错误可能导致的棘手内存泄漏。 此功能对于查询执行的自然“分阶段”行为非常有用,其中控制从解析器到优化器再到执行器,每个上下文中有许多分配,然后是上下文删除。
请注意,内存上下文实际上比大多数垃圾收集器提供了更多的控制,因为开发人员可以控制释放的空间和时间局部性。上下文机制本身提供了空间控制,允许程序员将内存分成逻辑单元。时间控制来自允许程序员在适当的时候发出上下文删除。相比之下,垃圾收集器通常处理程序的所有内存,并自行决定何时运行。这是尝试在Java[81]中编写服务器质量代码的挫折之一。
在malloc()和free()开销相对较高的平台上,内存上下文也提供了性能优势。特别是,内存上下文可以使用如何分配和释放内存的语义知识(通过上下文类型),并且可以相应地调用malloc()和free()以最小化操作系统开销。数据库系统的一些组件(例如,解析器和优化器)分配大量小对象,然后通过上下文删除一次释放它们。在大多数平台上,调用free()许多小对象相当昂贵。内存分配器可以改为调用malloc()来分配大区域,并将生成的内存分配给其调用者。 相对缺乏内存释放意味着不需要malloc()和free()使用的压缩逻辑。并且当上下文被删除时,只需要几个free()调用就可以删除大区域。
感兴趣的读者可能想浏览开源PostgreSQL代码。它使用了一个相当复杂的内存分配器。
7.2.1 A Note on Memory Allocation for Query Operators
供应商对空间密集型运算符(如散列连接和排序)的内存分配方案在哲学上有所不同。一些系统(例如,用于zSeries的DB2)允许DBA控制此类操作将使用的RAM量,并保证每个查询在执行时都获得该数量的RAM。准入控制策略确保了这一保证。在这样的系统中,运算符通过内存分配器从堆中分配内存。这些系统提供了良好的性能稳定性,但迫使DBA(静态地)决定如何平衡各种子系统(如缓冲池和查询运算符)之间的物理内存。
其他系统(例如MS SQLServer)将内存分配任务从DBA手中夺走,并自动管理这些分配。这些系统试图在查询执行的各种组件之间智能地分配内存,包括缓冲池中的页面缓存和查询运算符内存使用。用于所有这些任务的内存池就是缓冲池本身。因此,这些系统中的查询运算符通过DBMS实现的内存分配器从缓冲池中获取内存,并且仅将操作系统分配器用于大于缓冲池页面的连续请求。
这种区别呼应了我们在第6.3.1节中对查询准备的讨论。前一类系统假设DBA从事复杂的调整,并且系统的工作负载可以通过对系统内存“旋钮”的精心选择的调整来实现。在这些条件下,这样的系统应该总是可以预测地表现良好。后一类假设DBA要么没有或不能正确设置这些旋钮,并试图用软件逻辑取代DBA调整。他们还保留自适应地改变其相对分配的权利。这为在不断变化的工作负载上获得更好的性能提供了可能性。 正如第6.3.1节所讨论的,这种区别说明了这些供应商期望如何使用他们的产品,以及他们客户的管理专业知识(和财务资源)。
7.3 Disk Management Subsystems
DBMS教科书倾向于将磁盘视为同质对象。实际上,磁盘驱动器是容量和带宽差异很大的复杂异构硬件。因此,每个DBMS都有一个磁盘管理子系统来处理这些问题,并管理表和其他存储单元在原始设备、逻辑卷或文件之间的分配。
这个子系统的一个职责是将表映射到设备和/或文件。表到文件的一对一映射听起来很自然,但在早期的文件系统中提出了重大问题。首先,操作系统文件传统上不能大于磁盘,而数据库表可能需要跨越多个磁盘。其次,分配太多的操作系统文件被认为是不好的形式,因为操作系统通常只允许几个打开的文件描述符,并且许多用于目录管理和备份的操作系统实用程序不能扩展到非常大量的文件。最后,许多早期的文件系统将文件大小限制为2 GB。这显然是一个不可接受的小表限制。许多DBMS供应商使用原始IO完全绕过了操作系统文件系统,而其他供应商则选择绕过这些限制。因此,所有领先的商业DBMS都可以将一个表分布在多个文件上,或者将多个表存储在一个数据库文件中。随着时间的推移,大多数操作系统文件系统已经超越了这些限制。但是传统的影响仍然存在,现代DBMS仍然通常将操作系统文件视为任意映射到数据库表的抽象存储单元。
更复杂的是处理特定于设备的细节以维护时间和空间控制的代码,如第4节所述。如今,一个庞大而充满活力的行业基于复杂的存储设备,这些设备“假装”是磁盘驱动器,但实际上是大型硬件/软件系统,其API是像SCSI这样的传统磁盘驱动器接口。这些系统包括RAID系统和存储区域网络(SAN)设备,并且往往具有非常大的容量和复杂的性能特征。管理员喜欢这些系统,因为它们易于安装,并且通常通过快速故障转移提供易于管理的位级可靠性。这些功能为客户提供了一种明显的舒适感,超出了DBMS恢复子系统的承诺。 例如,大型DBMS安装通常使用SAN。
不幸的是,这些系统使DBMS实现复杂化。例如,RAID系统在故障后的性能与所有磁盘正常运行时的性能非常不同。这可能会使DBMS的I/O成本模型复杂化。一些磁盘可以在启用写缓存的模式下运行,但这可能会导致硬件故障期间的数据损坏。高级SAN实现大型电池支持的缓存,在某些情况下接近TB,但这些系统带来了超过一百万行微代码和相当大的复杂性。复杂性带来了新的故障模式,这些问题非常难以检测和正确诊断。
RAID系统也因在数据库任务上表现不佳而令数据库设计人员感到沮丧。RAID是为面向字节流的存储(一种UNIX文件)而设计的,而不是数据库系统使用的面向页面的存储。因此,与跨多个物理设备分区和复制数据的数据库特定解决方案相比,RAID设备往往表现不佳。例如,Gamma[43]的链式解聚类方案大致与RAID的发明相吻合,并且在DBMS环境中表现更好。此外,大多数数据库提供DBA命令来控制跨多个设备的数据分区,但RAID设备通过将多个设备隐藏在单个接口后面来破坏这些命令。
许多用户配置他们的RAID设备以最大限度地减少空间开销(“RAID级别5”),而通过磁盘镜像(“RAID级别1”)等更简单的方案,数据库的性能会好得多。RAID级别5的一个特别令人不快的特征是写入性能很差。这可能会给用户带来令人惊讶的瓶颈,DBMS供应商经常会为这些瓶颈解释或提供变通方法。无论好坏,RAID设备的使用(和误用)是商业DBMS必须考虑的事实。因此,大多数供应商花费大量精力调整其DBMS以在领先的RAID设备上正常工作。
在过去十年中,大多数客户部署将数据库存储分配给文件,而不是直接分配给逻辑卷或原始设备。但是大多数DBMS仍然支持原始设备访问,并且在运行大规模事务处理基准测试时经常使用这种存储映射。此外,尽管有上述一些缺点,但今天大多数企业DBMS存储都是SAN托管的。
7.4 Replication Services
通常需要通过定期更新在网络上复制数据库。这通常用于提高可靠性:复制的数据库在主系统出现故障时充当 slightly-out-of-date 的“热备用”。将热备用保持在物理上不同的位置有利于在火灾或其他灾难后继续运行。复制也经常用于为地理上分布的大型企业提供实用形式的分布式数据库功能。大多数此类企业将其数据库划分为大的地理区域(例如,国家或大陆),并在数据的主要副本上本地运行所有更新。查询也在本地执行,但可以在本地操作的新数据和从远程区域复制的slightly-out-of-date数据的混合上运行。
忽略硬件技术(例如EMC SRDF),使用了三种典型的复制方案,但只有第三种提供了高端设置所需的性能和可扩展性。当然,这是最难实现的。
-
Physical Replication 物理复制:最简单的方案是在每个复制周期对整个数据库进行物理复制。由于传送数据的带宽和在远程站点重新安装的成本,这种方案不能扩展到大型数据库。此外,保证数据库事务一致的快照很棘手。因此,物理复制仅用作低端的客户端解决方法。大多数供应商不鼓励通过任何软件支持来实现这种方案。
-
Trigger-Based Replication 基于触发器的复制:在这种方案中,触发器被放置在数据库表上,以便在对表进行任何插入、删除或更新时,在特殊的复制表中安装一条“差异”记录。该复制表被传送到远程站点,修改在那里“重播”。这种方案解决了上述物理复制的问题,但对某些工作负载带来了不可接受的性能损失。
-
Log-Based Replication 基于日志的复制:在可行的情况下,基于日志的复制是首选的复制解决方案。在基于日志的复制中,日志嗅探器进程拦截日志写入并将它们传递到远程系统。基于日志的复制使用两种广泛的技术来实现:(1)读取日志并构建SQL语句以针对目标系统重放,或者(2)读取日志记录并将这些语句发送到目标系统,目标系统处于永久恢复模式,在日志记录到达时重放它们。这两种机制都有价值,因此Microsoft SQL Server、DB2和Oracle都实现了这两种机制。SQLServer调用第一个日志传送和第二个数据库镜像。
该方案克服了以前替代方案的所有问题:它开销低,并且在运行系统上产生最小或不可见的性能开销;它提供增量更新,因此可以根据数据库大小和更新率优雅地扩展;它重用DBMS的内置机制,而无需大量额外的逻辑;最后,它通过日志的内置逻辑自然地提供事务一致的副本。大多数主要供应商都为自己的系统提供基于日志的复制。提供跨供应商工作的基于日志的复制要困难得多,因为在远程端驱动供应商的重放逻辑需要了解该供应商的日志格式。
7.5 Administration,Monitoring,and Utilities
每个DBMS都提供了一组用于管理其系统的实用程序。这些实用程序很少进行基准测试,但通常决定了系统的可管理性。一个技术上具有挑战性且特别重要的特性是使这些实用程序在线运行,即在用户查询和交易进行时。这在近年来由于电子商务的全球影响力而变得更加普遍的24×7操作中很重要。凌晨时分的传统“重组窗口”通常不再可用。因此,大多数供应商近年来在提供在线实用程序方面投入了大量精力。我们在这里介绍这些实用程序:
- Optimizer Statistics Gathering 优化器统计信息收集:每个主要的DBMS都有一些方法来扫描表并构建某种类型的优化器统计信息。一些统计信息,如直方图,在一次传递中构建而不会淹没内存是很重要的。例如,请参阅Flajolet和Martin关于计算列中不同值的数量的工作[17]。
- Physical Reorganization and Index Construction 物理重组和索引构建:随着时间的推移,由于插入和删除的模式会留下未使用的空间,访问方法可能会变得效率低下。此外,用户可能偶尔会要求在后台重新组织表,例如在不同的列上重新集群(排序)它们,或者跨多个磁盘重新分区它们。文件和索引的在线重组可能很棘手,因为在保持物理一致性的同时必须避免保持任何长度的锁。从这个意义上说,它与用于索引的日志记录和锁定协议有一些相似之处,如第5.4节所述。这是几篇研究论文[95]和专利的主题。
- Backup/Export 备份/导出:所有DBMS都支持将数据库物理转储到备份存储的能力。同样,由于这是一个长时间运行的过程,它不能天真地设置锁。相反,大多数系统执行某种“模糊”转储,并使用日志记录逻辑来增强它以确保事务一致性。类似的方案可用于将数据库导出为交换格式。
- Bulk Load 批量加载:在许多情况下,需要将大量数据快速引入数据库。供应商提供了一个针对高速数据导入优化的批量加载实用程序,而不是一次插入一行。通常,存储管理器中的自定义代码支持这些实用程序。例如,B+树的特殊批量加载代码可能比重复调用树插入代码快得多。
- Monitoring, Tuning, and Resource Governers 监控、调优和资源调控器:即使在托管环境中,查询消耗的资源也不是不寻常的。因此,大多数DBMS提供了帮助管理员识别和防止此类问题的工具。通常通过“虚拟表”为DBMS性能计数器提供基于SQL的接口,该接口可以显示按查询或锁、内存、临时存储等资源细分的系统状态。在某些系统中,还可以查询此类数据的历史日志。 许多系统允许在查询超过某些性能限制时注册警报,包括运行时间、内存或锁获取;在某些情况下,触发警报可能导致查询中止。最后,像IBM的预测资源调控器这样的工具试图阻止资源密集型查询运行。
8 Conclusion
从这篇文章中可以清楚地看出,现代商业数据库系统既基于学术研究,也基于为高端客户开发工业级产品的经验。从头开始编写和维护高性能、功能齐全的关系DBMS的任务是对时间和精力的巨大投资。然而,关系DBMS的许多教训转化为新的领域。Web服务、网络附加存储、文本和电子邮件存储库、通知服务和网络监视器都可以从DBMS研究和经验中受益。 数据密集型服务是当今计算的核心,数据库系统设计知识是一项广泛适用的技能,无论是在主要数据库商店的大厅内外。这些新方向也提出了数据库管理中的许多研究问题,并为数据库社区和其他计算领域之间的新交互指明了方向。
References
[1] A. Adya, B. Liskov, and P. O’Neil, “Generalized isolation level definitions,” in16th International Conference on Data Engineering (ICDE), San Diego, CA, February 2000.
[2] R. Agrawal, M. J. Carey, and M. Livny, “Concurrency control performance modelling: Alternatives and implications,” ACMTransactions on Database Systems (TODS), vol. 12, pp. 609–654, 1987.
[3] M. M. Astrahan, M. W. Blasgen, D. D. Chamberlin, K. P. Eswaran, J. Gray, P. P. Griffiths, W. F. Frank King III, R. A. Lorie, P. R. McJones, J. W. Mehl, G. R. Putzolu, I. L. Traiger, B. W.Wade, and V.Watson, “System R: Relational approach to database management,” ACM Transactions on Database Systems (TODS), vol. 1, pp. 97–137, 1976.
[4] R. Bayer and M. Schkolnick, “Concurrency of operations on B-trees,” Acta Informatica, vol. 9, pp. 1–21, 1977.
[5] K. P. Bennett, M. C. Ferris, and Y. E. Ioannidis, “A genetic algorithm for database query optimization,” in Proceedings of the 4th International Conference on Genetic Algorithms, pp. 400–407, San Diego, CA, July 1991.
[6] H. Berenson, P. A. Bernstein, J. Gray, J. Melton, E. J. O’Neil, and P. E. O’Neil, “A critique of ANSI SQL isolation levels,” in Proceedings of ACM SIGMOD International Conference on Management of Data, pp. 1–10, San Jose, CA, May 1995.
[7] P. A. Bernstein and N. Goodman, “Concurrency control in distributed database systems,” ACM Computing Surveys, vol. 13, 1981.
[8] W. Bridge, A. Joshi, M. Keihl, T. Lahiri, J. Loaiza, and N. MacNaughton, “The oracle universal server buffer,” in Proceedings of 23rd International Conference on Very Large Data Bases (VLDB), pp. 590–594, Athens, Greece, August 1997.
[9] F. Chang, J. Dean, S. Ghemawat, W. C. Hsieh, D. A. Wallach, M. Burrows, T. Chandra, A. Fikes, and R. E. Gruber, “Bigtable: A distributed storage system for structured data,” in Symposium on Operating System Design and Implementation (OSDI), 2006.
[10] S. Chaudhuri, “An overview of query optimization in relational systems,” in Proceedings of ACM Principles of Database Systems (PODS), 1998.
[11] S. Chaudhuri and U. Dayal, “An overview of data warehousing and olap technology,” ACM SIGMOD Record, March 1997.
[12] S. Chaudhuri and V. R. Narasayya, “Autoadmin ‘what-if’ index analysis utility,” in Proceedings of ACM SIGMOD International Conference on Management of Data, pp. 367–378, Seattle, WA, June 1998.
[13] S. Chaudhuri and K. Shim, “Optimization of queries with user-defined predicates,” ACMTransactions on Database Systems (TODS), vol. 24, pp. 177–228, 1999.
[14] M.-S. Chen, J. Hun, and P. S. Yu, “Data mining: An overview from a database perspective,” IEEE Transactions on Knowledge and Data Engineering, vol. 8, 1996.
[15] H.-T. Chou and D. J. DeWitt, “An evaluation of buffer management strategies for relational database systems,” in Proceedings of 11th International Conference on Very Large Data Bases (VLDB), pp. 127–141, Stockholm, Sweden, August 1985.
[16] A. Desphande, M. Garofalakis, and R. Rastogi, “Independence is good: Dependency-based histogram synopses for high-dimensional data,” in Proceedings of the 18th International Conference on Data Engineering, San Jose, CA, February 2001.
[17] P. Flajolet and G. Nigel Martin, “Probabilistic counting algorithms for data base applications,” Journal of Computing System Science, vol. 31, pp. 182–209, 1985.
[18] C. A. Galindo-Legaria, A. Pellenkoft, and M. L. Kersten, “Fast, randomized join-order selection — why use transformations?,” VLDB, pp. 85–95, 1994.
[19] S. Ganguly, W. Hasan, and R. Krishnamurthy, “Query optimization for parallel execution,” in Proceedings of the ACM SIGMOD International Conference on Management of Data, pp. 9–18, San Diego, CA, June 1992.
[20] M. Garofalakis and P. B. Gibbons, “Approximate query processing: Taming the terabytes, a tutorial,” in International Conferenence on Very Large Data Bases, 2001. www.vldb.org/conf/2001/tut4.pdf.
[21] M. N. Garofalakis and Y. E. Ioannidis, “Parallel query scheduling and optimization with time- and space-shared resources,” in Proceedings of 23rd International Conference on Very Large Data Bases (VLDB), pp. 296–305, Athens, Greece, August 1997.
[22] R. Goldman and J. Widom, “Wsq/dsq: A practical approach for combined querying of databases and the web,” in Proceedings of ACM-SIGMOD International Conference on Management of Data, 2000.
[23] G. Graefe, “Encapsulation of parallelism in the volcano query processing system,” in Proceedings of ACM-SIGMOD International Conference on Management of Data, pp. 102–111, Atlantic City, May 1990.
[24] G. Graefe, “Query evaluation techniques for large databases,” Computing Surveys, vol. 25, pp. 73–170, 1993.
[25] G. Graefe, “The cascades framework for query optimization,” IEEE Data Engineering Bulletin, vol. 18, pp. 19–29, 1995.
[26] C. Graham, “Market share: Relational database management systems by operating system, worldwide, 2005,” Gartner Report No: G00141017, May 2006.
[27] J. Gray, “Greetings from a filesystem user,” in Proceedings of the FAST ’05 Conference on File and Storage Technologies, (San Francisco), December 2005.
[28] J. Gray and B. Fitzgerald, FLASH Disk Opportunity for Server-Applications. http://research.microsoft.com/∼Gray/papers/FlashDiskPublic.doc.
[29] J. Gray, R. A. Lorie, G. R. Putzolu, and I. L. Traiger, “Granularity of locks and degrees of consistency in a shared data base,” in IFIP Working Conference on Modelling in Data Base Management Systems, pp. 365–394, 1976.
[30] J. Gray and A. Reuter, Transaction Processing: Concepts and Techniques. Morgan Kaufmann, 1993.
[31] S. D. Gribble, E. A. Brewer, J. M. Hellerstein, and D. Culler, “Scalable, distributed data structures for internet service construction,” in Proceedings of the Fourth Symposium on Operating Systems Design and Implementation (OSDI), 2000.
[32] A. Guttman, “R-trees: A dynamic index structure for spatial searching,” in Proceedings of ACM-SIGMOD International Conference on Management of Data, pp. 47–57, Boston, June 1984.
[33] L. Haas, D. Kossmann, E. L. Wimmers, and J. Yang, “Optimizing queries across diverse data sources,” in International Conference on Very Large Databases (VLDB), 1997.
[34] T. Haerder and A. Reuter, “Principles of transaction-oriented database recovery,” ACM Computing Surveys, vol. 15, pp. 287–317, 1983.
[35] S. Harizopoulos and N. Ailamaki, “StagedDB: Designing database servers for modern hardware,” IEEE Data Engineering Bulletin, vol. 28, pp. 11–16, June 2005.
[36] S. Harizopoulos, V. Liang, D. Abadi, and S. Madden, “Performance tradeoffs in read-optimized databases,” in Proceedings of the 32nd Very Large Databases Conference (VLDB), 2006.
[37] J. M. Hellerstein, “Optimization techniques for queries with expensive methods,” ACM Transactions on Database Systems (TODS), vol. 23, pp. 113–157, 1998.
[38] J. M. Hellerstein, P. J. Haas, and H. J. Wang, “Online aggregation,” in Proceedings of ACM-SIGMOD International Conference on Management of Data, 1997.
[39] J. M. Hellerstein, J. Naughton, and A. Pfeffer, “Generalized search trees for database system,” in Proceedings of Very Large Data Bases Conference (VLDB), 1995.
[40] J. M. Hellerstein and A. Pfeffer, “The russian-doll tree, an index structure for sets,” University of Wisconsin Technical Report TR1252, 1994.
[41] C. Hoare, “Monitors: An operating system structuring concept,” Communications of the ACM (CACM), vol. 17, pp. 549–557, 1974.
[42] W. Hong and M. Stonebraker, “Optimization of parallel query execution plans in xprs,” in Proceedings of the First International Conference on Parallel and Distributed Information Systems (PDIS), pp. 218–225, Miami Beach, FL, December 1991.
[43] H.-I. Hsiao and D. J. DeWitt, “Chained declustering: A new availability strategy for multiprocessor database machines,” in Proceedings of Sixth International Conference on Data Engineering (ICDE), pp. 456–465, Los Angeles, CA, November 1990.
[44] Y. E. Ioannidis and Y. Cha Kang, “Randomized algorithms for optimizing large join queries,” in Proceedings of ACM-SIGMOD International Conference on Management of Data, pp. 312–321, Atlantic City, May 1990.
[45] Y. E. Ioannidis and S. Christodoulakis, “On the propagation of errors in the size of join results,” in Proceedings of the ACMSIGMOD International Conference on Management of Data, pp. 268–277, Denver, CO, May 1991.
[46] M. Kornacker, C. Mohan, and J. M. Hellerstein, “Concurrency and recovery in generalized search trees,” in Proceedings of ACM SIGMOD International Conference on Management of Data, pp. 62–72, Tucson, AZ, May 1997.
[47] H. T. Kung and J. T. Robinson, “On optimistic methods for concurrency control,” ACM Tranactions on Database Systems (TODS), vol. 6, pp. 213–226, 1981.
[48] J. R. Larus and M. Parkes, “Using cohort scheduling to enhance server performance,” in USENIX Annual Conference, 2002.
[49] H. C. Lauer and R. M. Needham, “On the duality of operating system structures,” ACMSIGOPS Operating Systems Review, vol. 13, pp. 3–19, April 1979.
[50] P. L. Lehman and S. Bing Yao, “Efficient locking for concurrent operations on b-trees,” ACMTransactions on Database Systems (TODS), vol. 6, pp. 650–670, December 1981.
[51] A. Y. Levy, “Answering queries using views,” VLDB Journal, vol. 10, pp. 270–294, 2001.
[52] A. Y. Levy, I. Singh Mumick, and Y. Sagiv, “Query optimization by predicate move-around,” in Proceedings of 20th International Conference on Very Large Data Bases, pp. 96–107, Santiago, September 1994.
[53] W. Litwin, “Linear hashing: A new tool for file and table addressing,” in Sixth International Conference on Very Large Data Bases (VLDB), pp. 212–223, Montreal, Quebec, Canada, October 1980.
[54] G. M. Lohman, “Grammar-like functional rules for representing query optimization alternatives,” in Proceedings of ACM SIGMOD International Conference on Management of Data, pp. 18–27, Chicago, IL, June 1988.
[55] Q. Luo, S. Krishnamurthy, C. Mohan, H. Pirahesh, H. Woo, B. G. Lindsay, and J. F. Naughton, “Middle-tier database caching for e-business,” in Proceedings of ACM SIGMOD International Conference on Management of Data, 2002.
[56] S. R. Madden and M. J. Franklin, “Fjording the stream: An architecture for queries over streaming sensor data,” in Proceedings of 12th IEEE International Conference on Data Engineering (ICDE), San Jose, February 2002.
[57] V. Markl, G. Lohman, and V. Raman, “Leo: An autonomic query optimizer for db2,” IBM Systems Journal, vol. 42, pp. 98–106, 2003.
[58] C. Mohan, “Aries/kvl: A key-value locking method for concurrency control of multiaction transactions operating on b-tree indexes,” in 16th International Conference on Very Large Data Bases (VLDB), pp. 392–405, Brisbane, Queensland, Australia, August 1990.
[59] C. Mohan, D. J. Haderle, B. G. Lindsay, H. Pirahesh, and P. M. Schwarz,“Aries: A transaction recovery method supporting fine-granularity locking and partial rollbacks using write-ahead logging,” ACM Transactions on Database Systems (TODS), vol. 17, pp. 94–162, 1992.
[60] C. Mohan and F. Levine, “Aries/im: An efficient and high concurrency index management method using write-ahead logging,” in Proceedings of ACM SIGMOD International Conference on Management ofData, (M. Stonebraker, ed.), pp. 371–380, San Diego, CA, June 1992.
[61] C. Mohan, B. G. Lindsay, and R. Obermarck, “Transaction management in the r* distributed database management system,” ACMTransactions on Database Systems (TODS), vol. 11, pp. 378–396, 1986.
[62] E. Nightingale, K. Veerarghavan, P. M. Chen, and J. Flinn, “Rethink the sync,” in Symposium on Operating Systems Design and Implementation (OSDI), November 2006.
[63] OLAP Market Report. Online manuscript. http://www.olapreport.com/market.html.
[64] E. J. O’Neil, P. E. O’Neil, and G. Weikum, “The lru-k page replacement algorithm for database disk buffering,” in Proceedings of ACM SIGMOD International Conference on Management of Data, pp. 297–306, Washington, DC, May 1993.
[65] P. E. O’Neil and D. Quass, “Improved query performance with variant indexes,” in Proceedings of ACM-SIGMOD International Conference on Management of Data, pp. 38–49, Tucson, May 1997.
[66] S. Padmanabhan, B. Bhattacharjee, T. Malkemus, L. Cranston, and M. Huras, “Multi-dimensional clustering: A new data layout scheme in db2,” in ACM SIGMOD International Management of Data (San Diego, California, June 09–12, 2003) SIGMOD ’03, pp. 637–641, New York, NY: ACM Press, 2003.
[67] D. Patterson, “Latency lags bandwidth,” CACM, vol. 47, pp. 71–75, October 2004.
[68] H. Pirahesh, J. M. Hellerstein, and W. Hasan, “Extensible/rule- based query rewrite optimization in starburst,” in Proceedings of ACM-SIGMOD International Conference on Management of Data, pp. 39–48, San Diego, June 1992.
[69] V. Poosala and Y. E. Ioannidis, “Selectivity estimation without the attribute value independence assumption,” in Proceedings of 23rd International Conference on Very Large Data Bases (VLDB), pp. 486–495, Athens, Greece, August 1997.
[70] M. P¨oss, B. Smith, L. Koll´ar, and P.-˚A. Larson, “Tpc-ds, taking decision support benchmarking to the next level,” in SIGMOD 2002, pp. 582–587.
[71] V. Prabakharan, A. C. Arpaci-Dusseau, and R. Arpaci-Dusseau, “Analysis and evolution of journaling file systems,” in Proceedings of USENIX Annual Technical Conference, April 2005.
[72] R. Ramakrishnan and J. Gehrke, “Database management systems,” McGrawHill, Boston, MA, Third ed., 2003.
[73] V. Raman and G. Swart, “How to wring a table dry: Entropy compression of relations and querying of compressed relations,” in Proceedings of International Conference on Very Large Data Bases (VLDB), 2006.
[74] D. P. Reed, Naming and Synchronization in a Decentralized Computer System. PhD thesis, MIT, Dept. of Electrical Engineering, 1978.
[75] A. Reiter, “A study of buffer management policies for data management systems,” Technical Summary Report 1619, Mathematics Research Center, University of Wisconsin, Madison, 1976.
[76] D. J. Rosenkrantz, R. E. Stearns, and P. M. Lewis, “System level concurrency control for distributed database systems,” ACMTransactions on Database Systems (TODS), vol. 3, pp. 178–198, June 1978.
[77] S. Sarawagi, S. Thomas, and R. Agrawal, “Integrating mining with relational database systems: Alternatives and implications,” in Proceedings of ACM-SIGMOD International Conference on Management of Data, 1998.
[78] R. Sears and E. Brewer, “Statis: Flexible transactional storage,” in Proceedings ofSymposium on Operating Systems Design and Implementation (OSDI), 2006.
[79] P. G. Selinger, M. Astrahan, D. Chamberlin, R. Lorie, and T. Price, “Access path selection in a relational database management system,” in Proceedings of ACM-SIGMOD International Conference on Management of Data, pp. 22–34, Boston, June 1979.
[80] P. Seshadri, H. Pirahesh, and T. Y. C. Leung, “Complex query decorrelation,” in Proceedings of 12th IEEE International Conference on Data Engineering (ICDE), New Orleans, February 1996.
[81] M. A. Shah, S. Madden, M. J. Franklin, and J. M. Hellerstein, “Java support for data-intensive systems: Experiences building the telegraph dataflow system,” ACM SIGMOD Record, vol. 30, pp. 103–114, 2001.
[82] L. D. Shapiro, “Exploiting upper and lower bounds in top-down query optimization,” International Database Engineering and Application Symposium (IDEAS), 2001.
[83] A. Silberschatz, H. F. Korth, and S. Sudarshan, Database System Concepts. McGraw-Hill, Boston, MA, Fourth ed., 2001.
[84] M. Steinbrunn, G. Moerkotte, and A. Kemper, “Heuristic and randomized optimization for the join ordering problem,” VLDB Journal, vol. 6, pp. 191–208, 1997.
[85] M. Stonebraker, “Retrospection on a database system,” ACMTransactions on Database Systems (TODS), vol. 5, pp. 225–240, 1980.
[86] M. Stonebraker, “Operating system support for database management,” Communications of the ACM (CACM), vol. 24, pp. 412–418, 1981.
[87] M. Stonebraker, “The case for shared nothing,” IEEE Database Engineering Bulletin, vol. 9, pp. 4–9, 1986.
[88] M. Stonebraker, “Inclusion of new types in relational data base systems,” ICDE, pp. 262–269, 1986.
[89] M. Stonebraker, D. J. Abadi, A. Batkin, X. Chen, M. Cherniack, M. Ferreira, E. Lau, A. Lin, S. Madden, E. O’Neil, P. O’Neil, A. Rasin, N. Tran, and S. Zdonik, “C-store: A column oriented dbms,” in Proceedings of the Conference on Very Large Databases (VLDB), 2005.
[90] M. Stonebraker and U. Cetintemel, “One size fits all: An idea whose time has come and gone,” in Proceedings of the International Conference on Data Engineering (ICDE), 2005.
[91] Transaction Processing Performance Council 2006. TPC Benchmark C Standard Specification Revision 5.7, http://www.tpc.org/tpcc/spec/tpcc current.pdf, April.
[92] T. Urhan, M. J. Franklin, and L. Amsaleg, “Cost based query scrambling for initial delays,” ACM-SIGMOD International Conference on Management of Data, 1998.
[93] R. von Behren, J. Condit, F. Zhou, G. C. Necula, and E. Brewer, “Capriccio: Scalable threads for internet services,” in Proceedings of the Ninteenth Symposium on Operating System Principles (SOSP-19), Lake George, New York, October 2003.
[94] M. Welsh, D. Culler, and E. Brewer, “Seda: An architecture for well- conditioned, scalable internet services,” in Proceedings of the 18th Symposium on Operating Systems Principles (SOSP-18), Banff, Canada, October 2001.
[95] C. Zou and B. Salzberg, “On-line reorganization of sparsely-populated b+trees,” pp. 115–124, 1996.
