复习操作系统
-
视频 bilibili : 中山大学OS

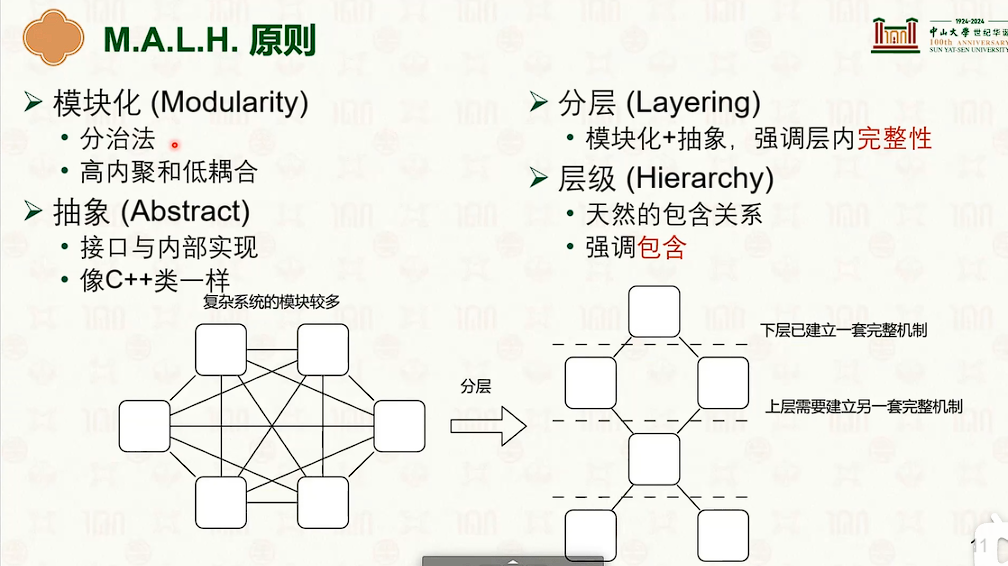
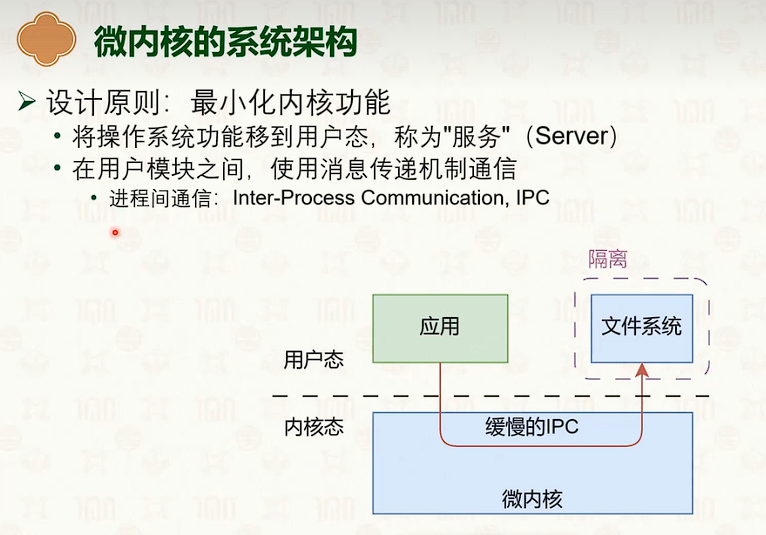
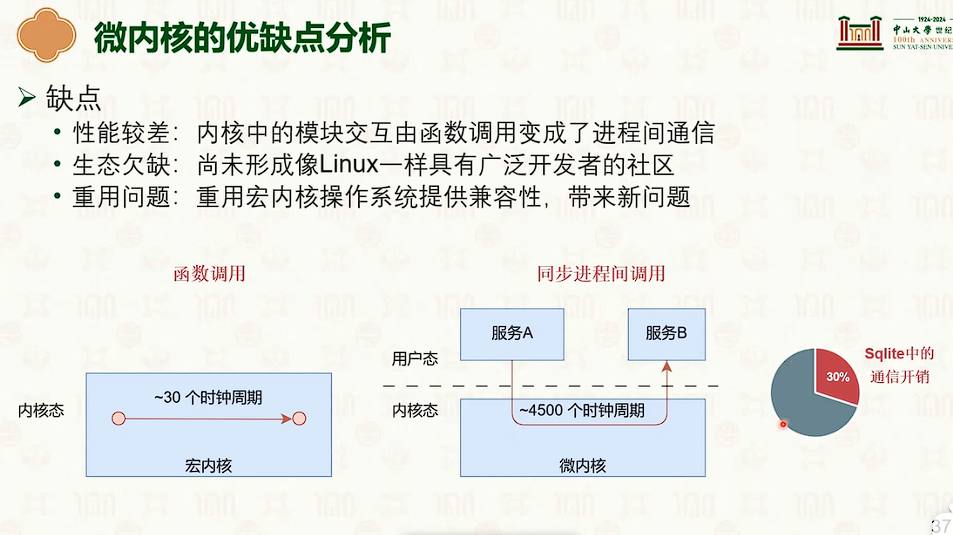
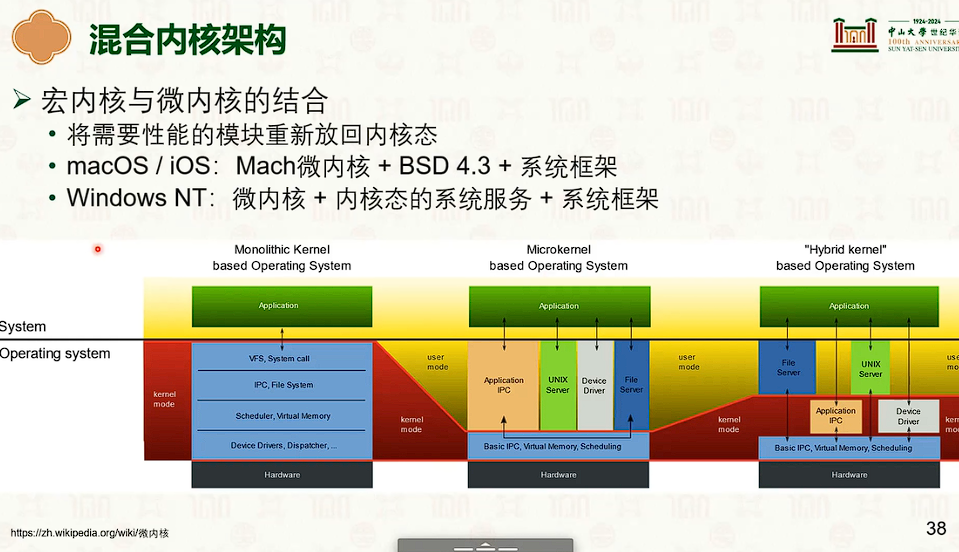
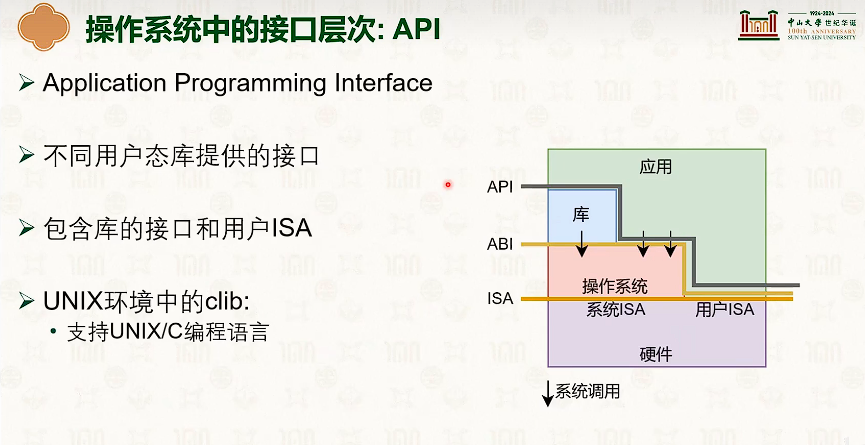
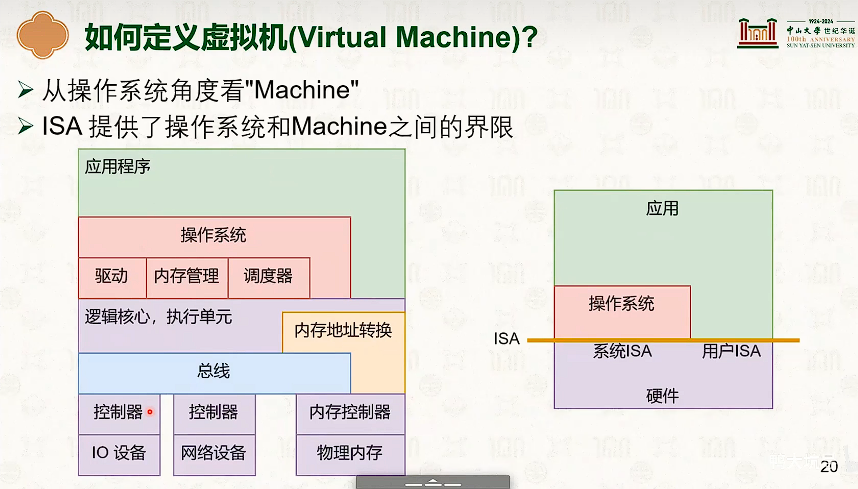
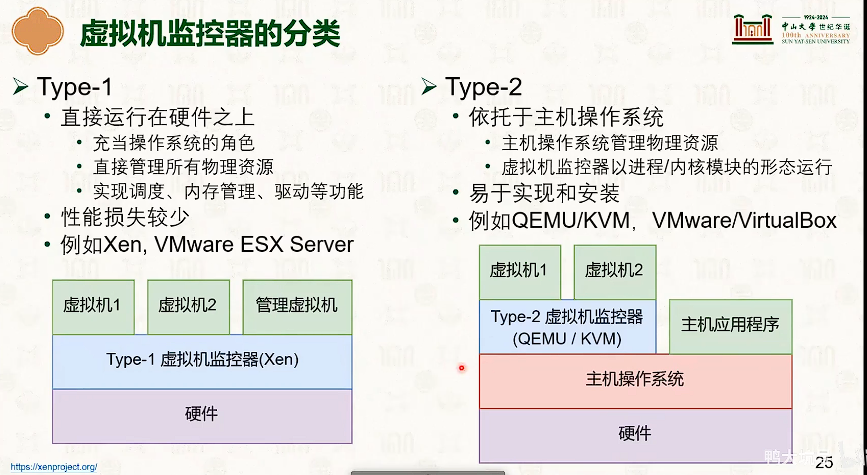
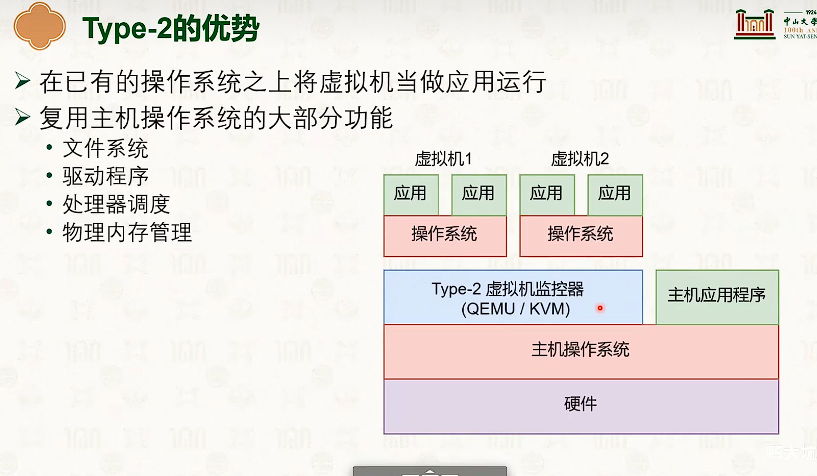
操作系统结构




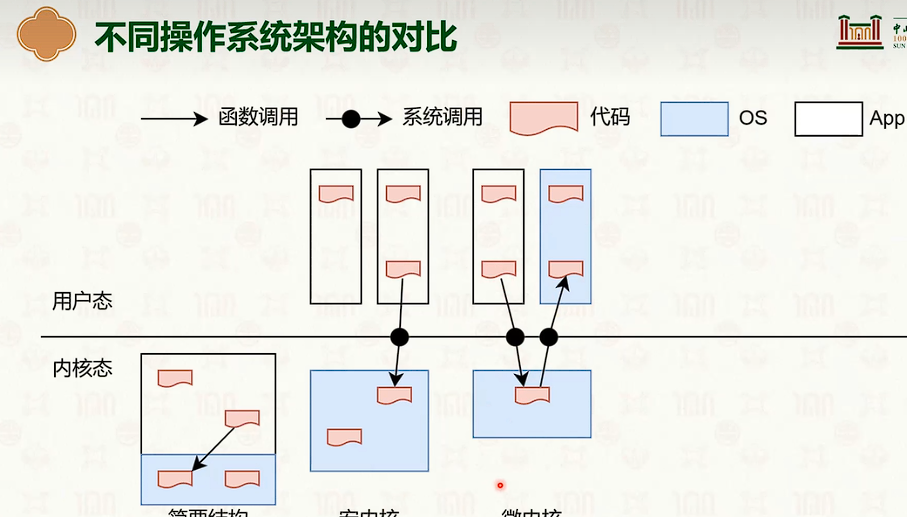
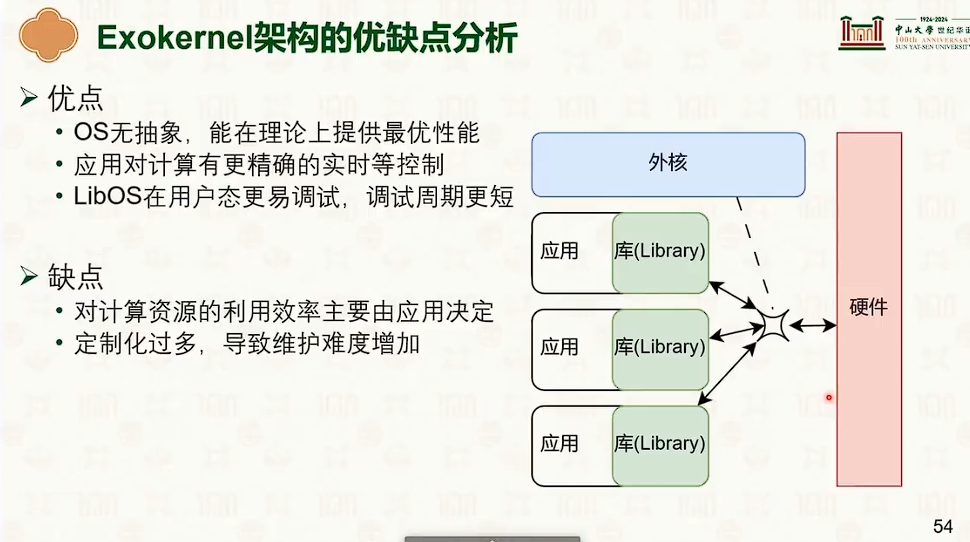
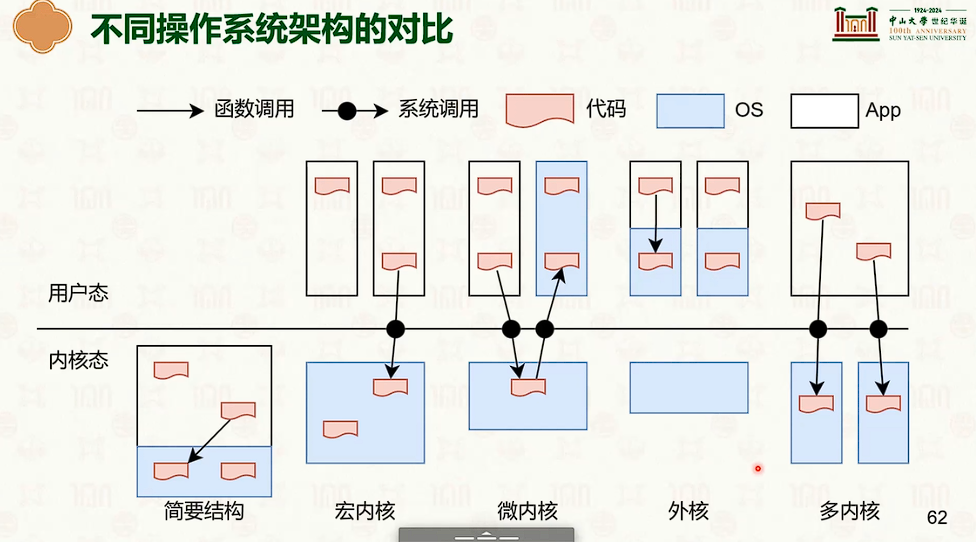
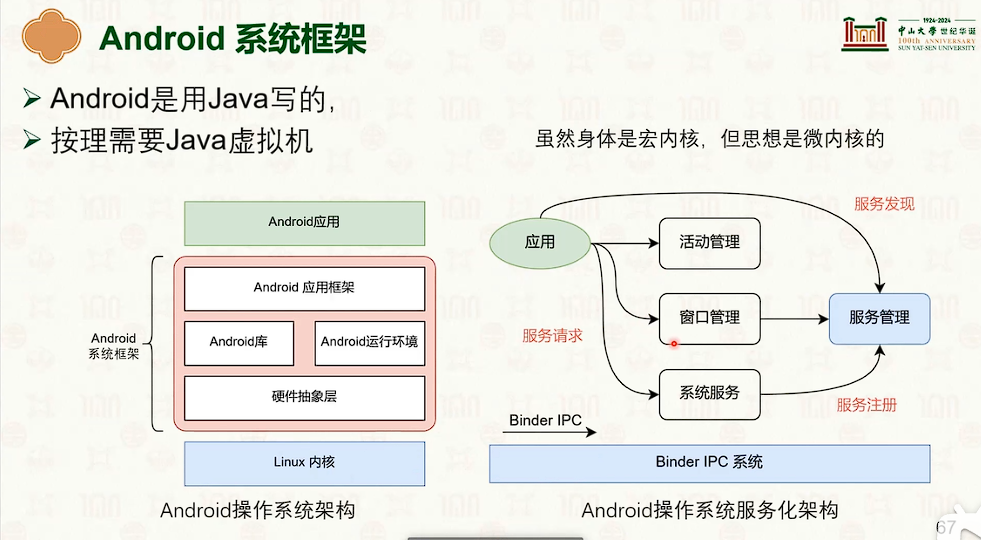
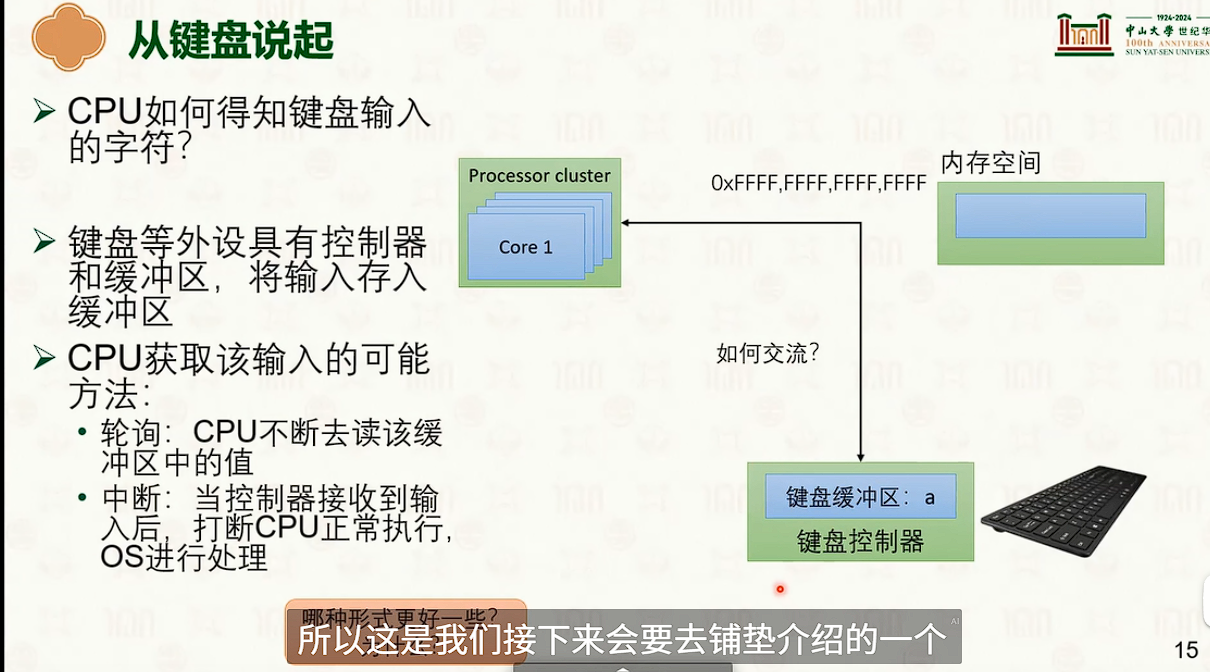
硬件环境与软件抽象:特权模型与中断

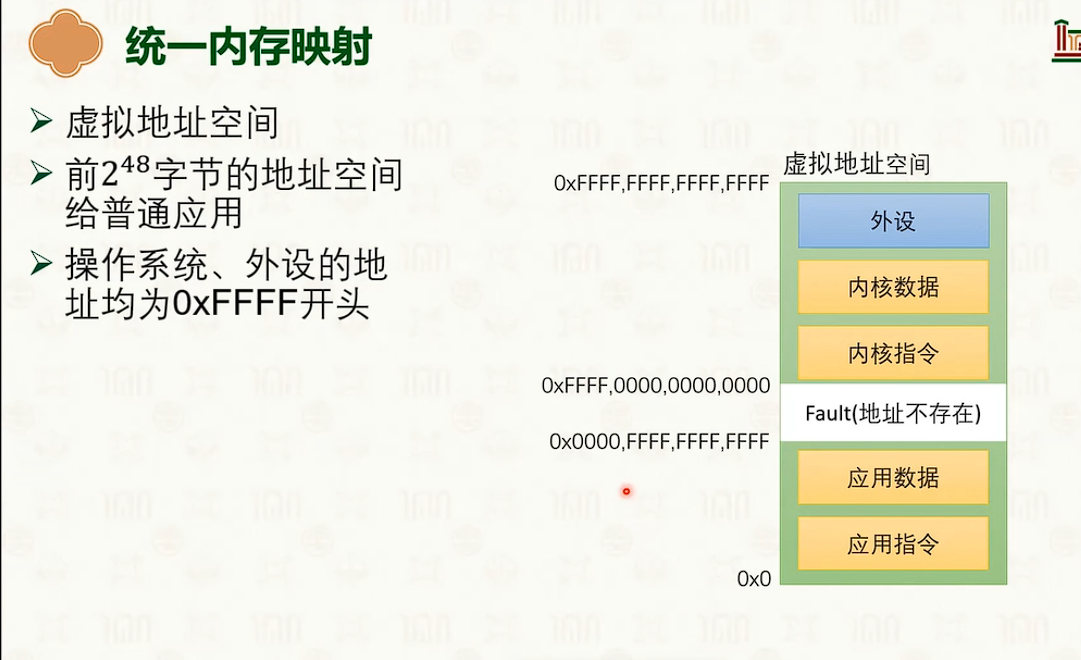
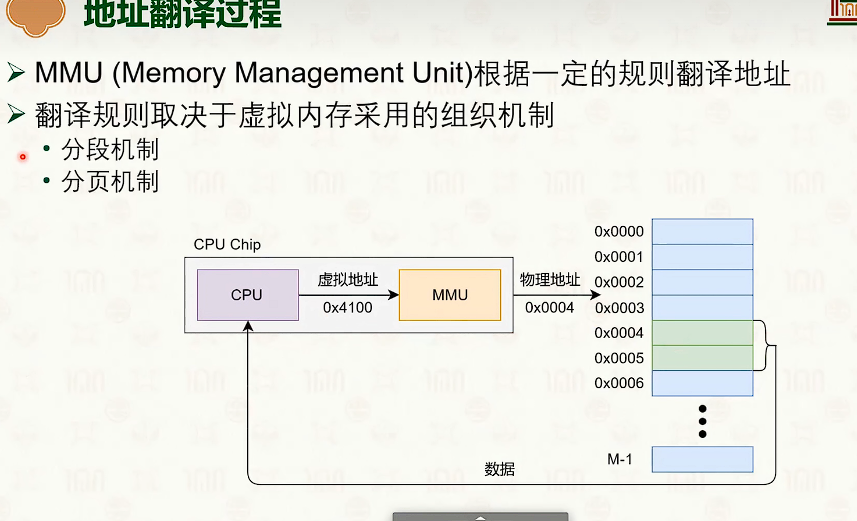
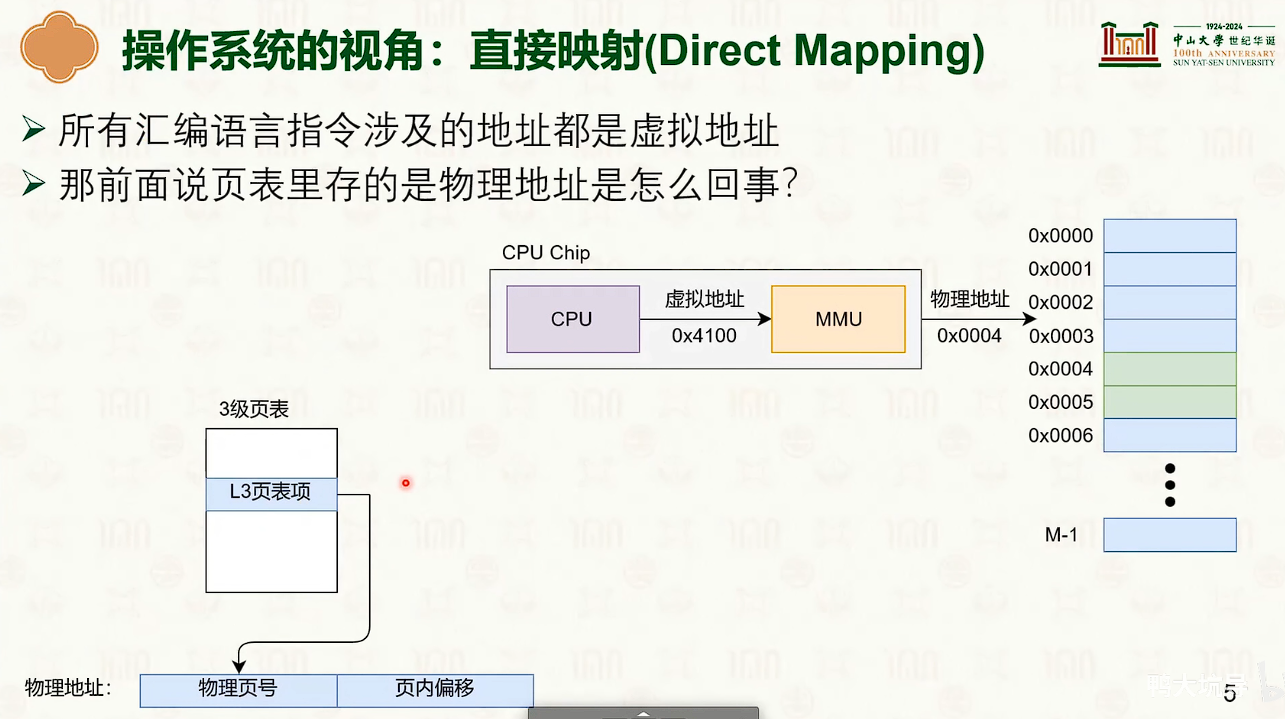
虚拟内存管理



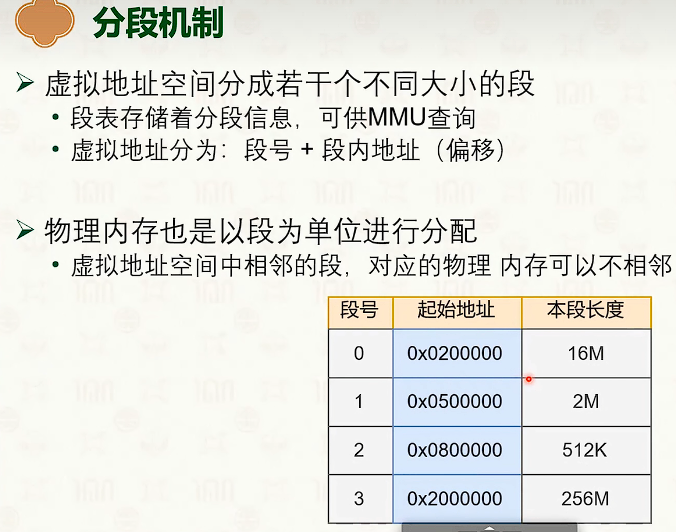
分段虚拟内存
把虚拟地址切分成若干个大小的段。
- 段表存储着分段信息,可供MMU查询
- 虚拟地址分为:段号+段内偏移。
- 段的大小不一
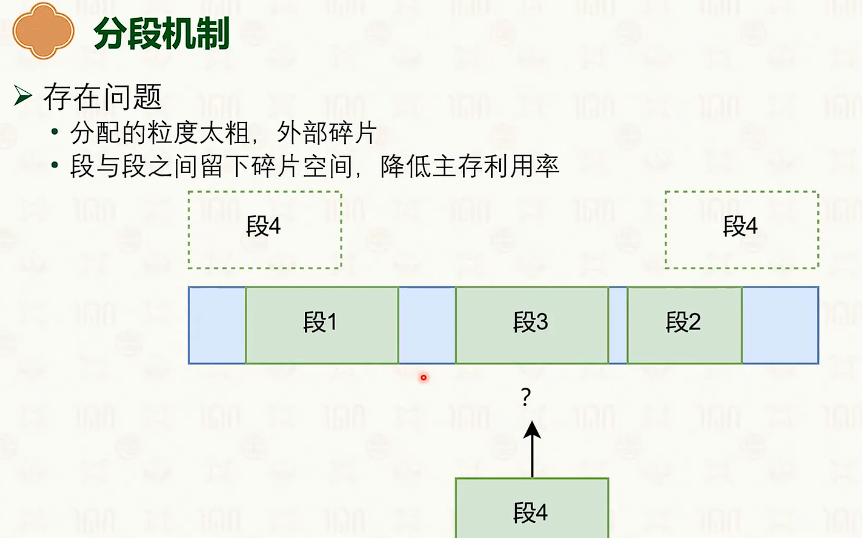
虽然外部碎片大,但是没有内部碎片
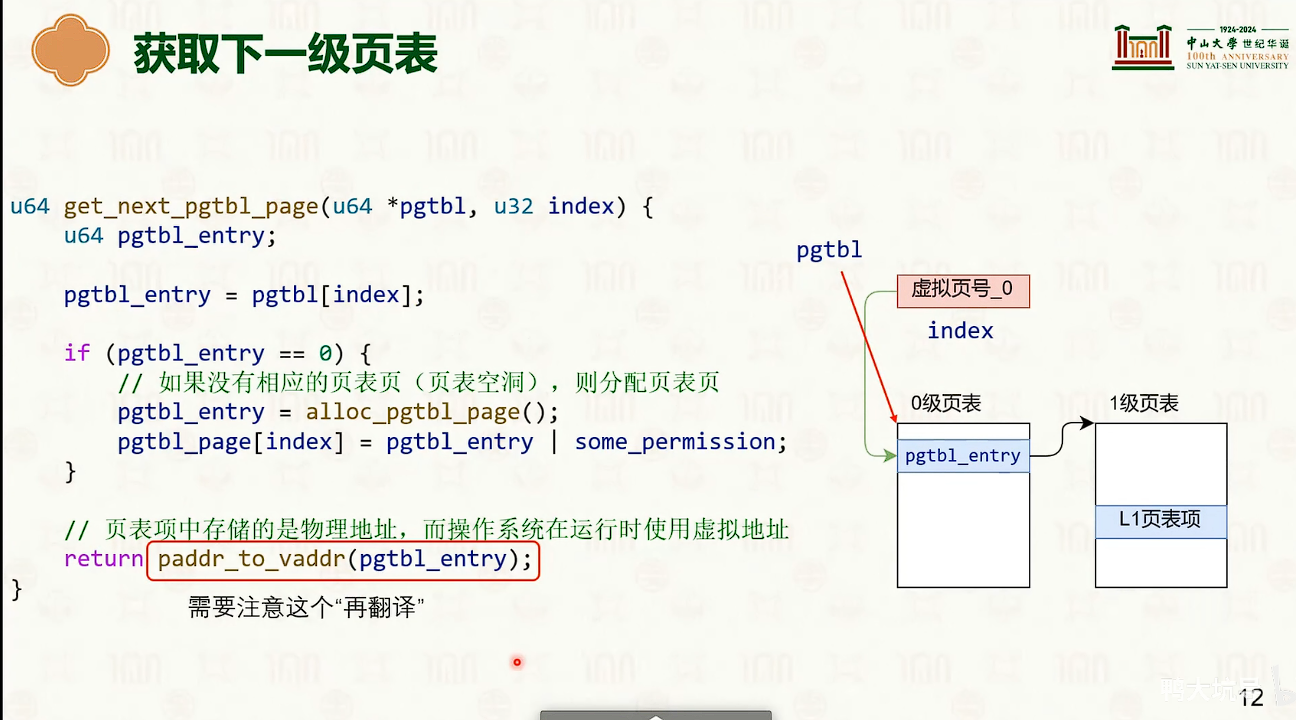
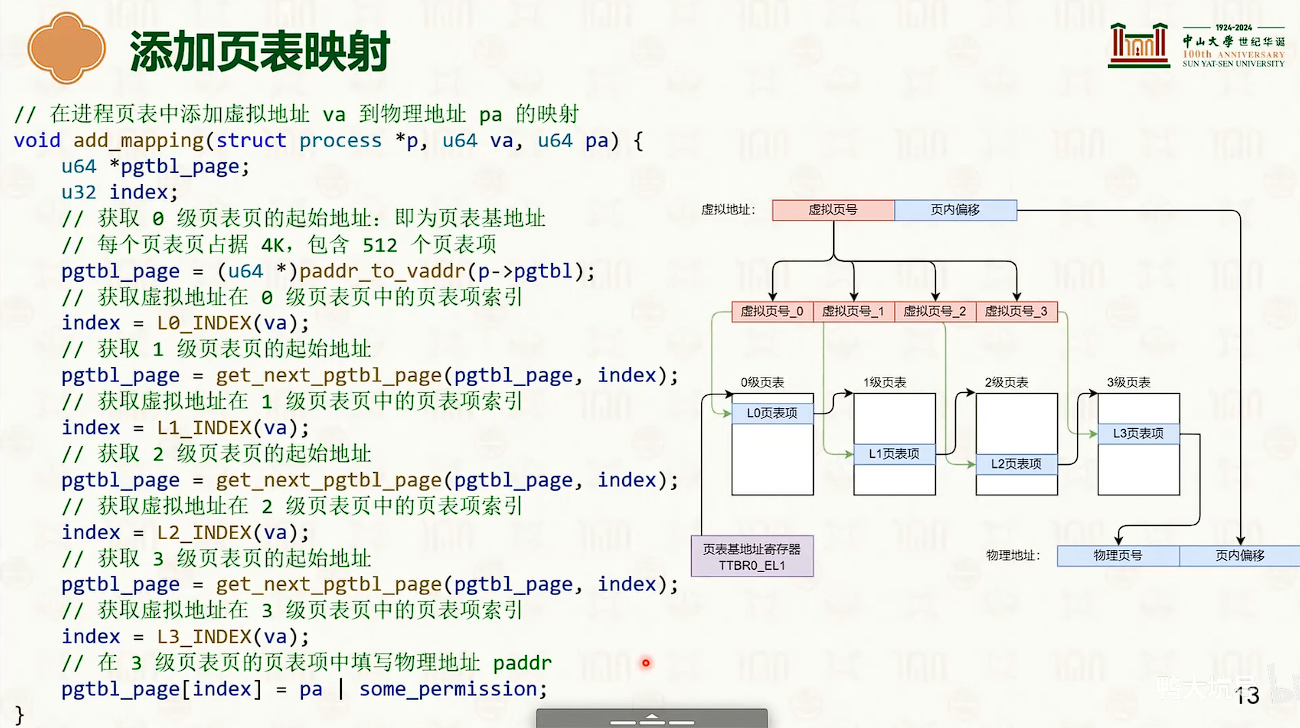
分页虚拟内存
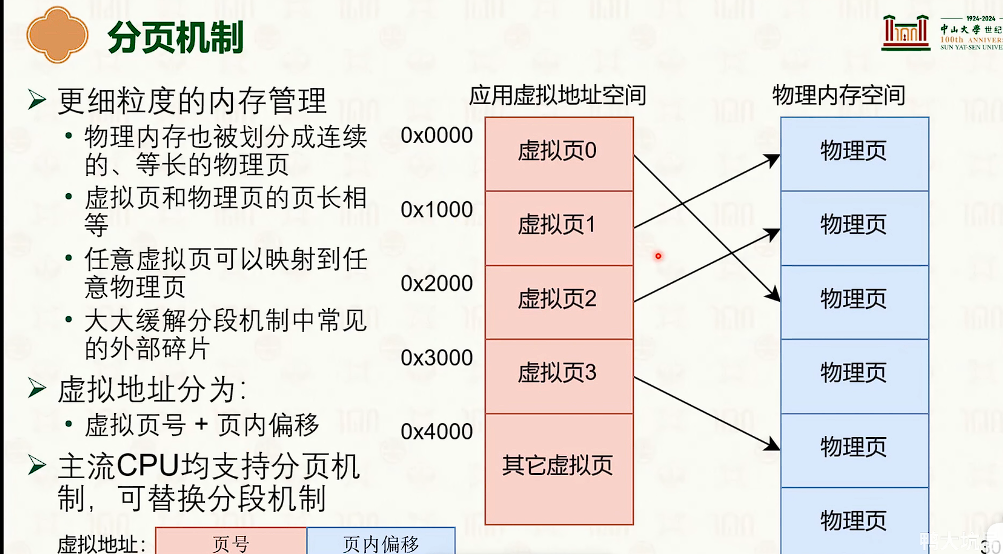
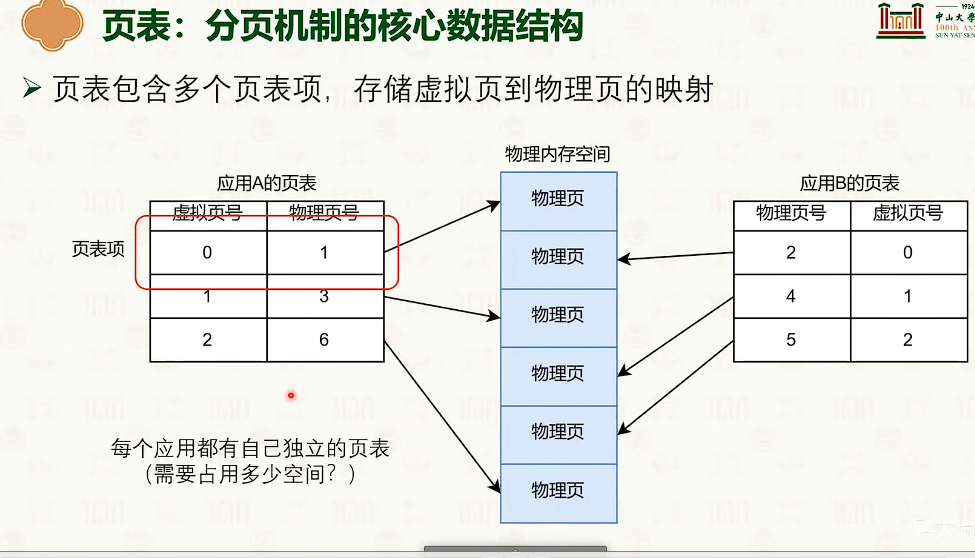
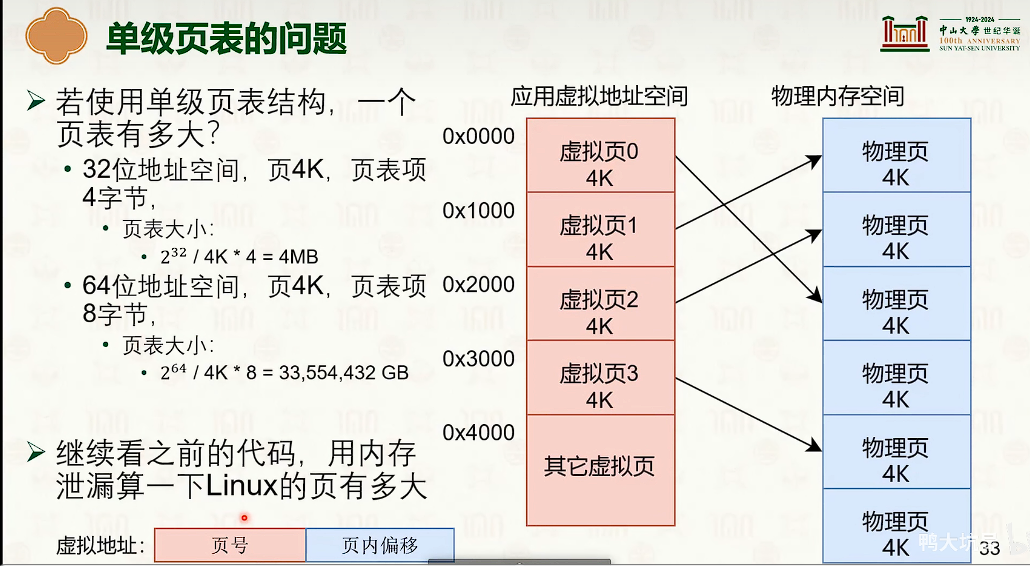
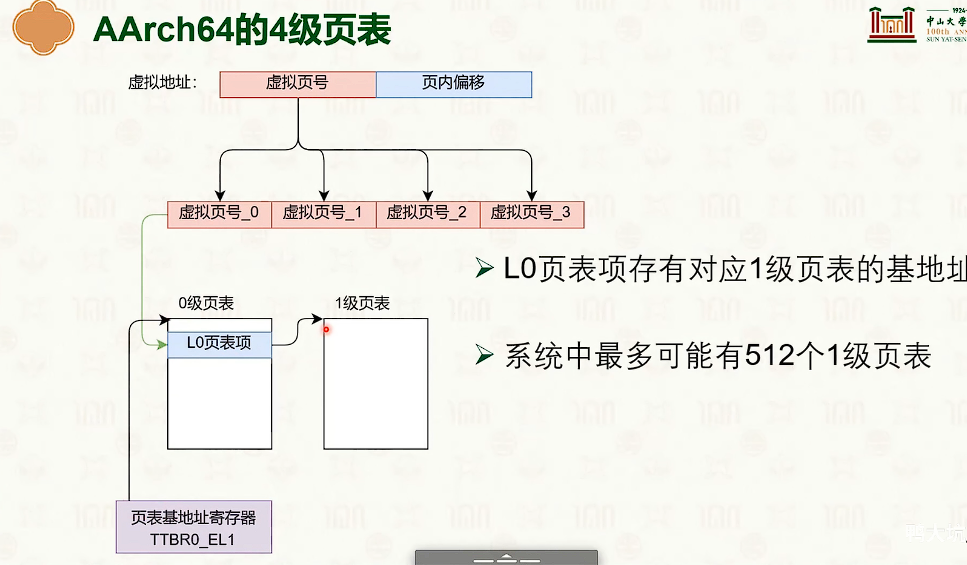
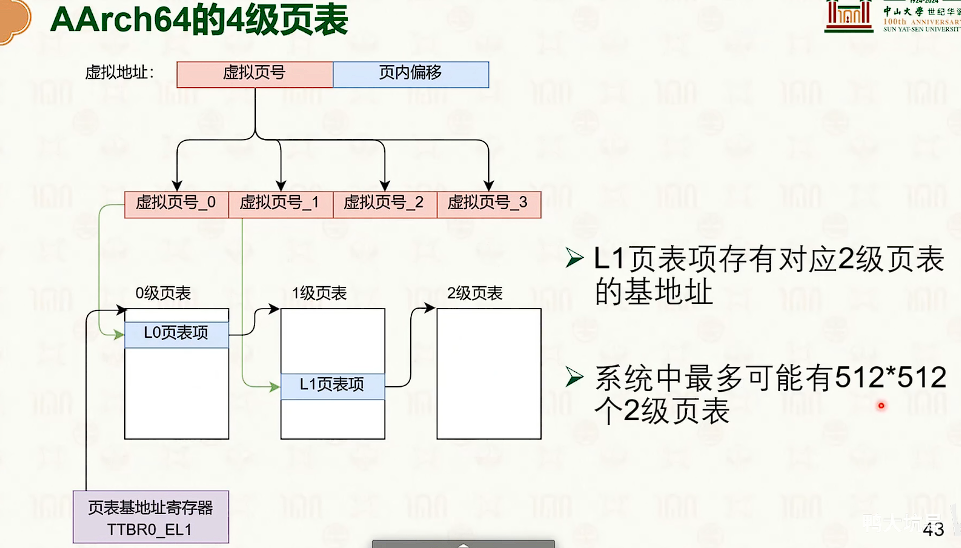
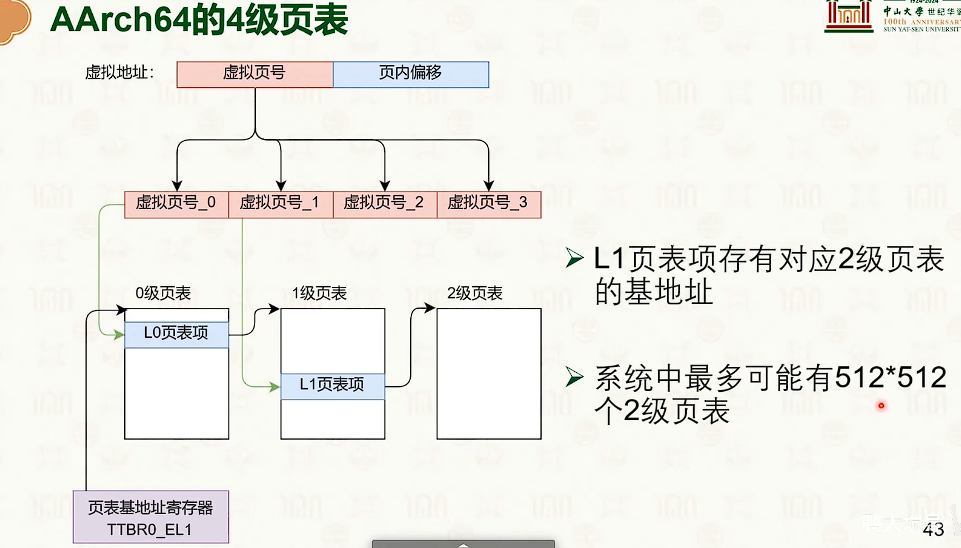
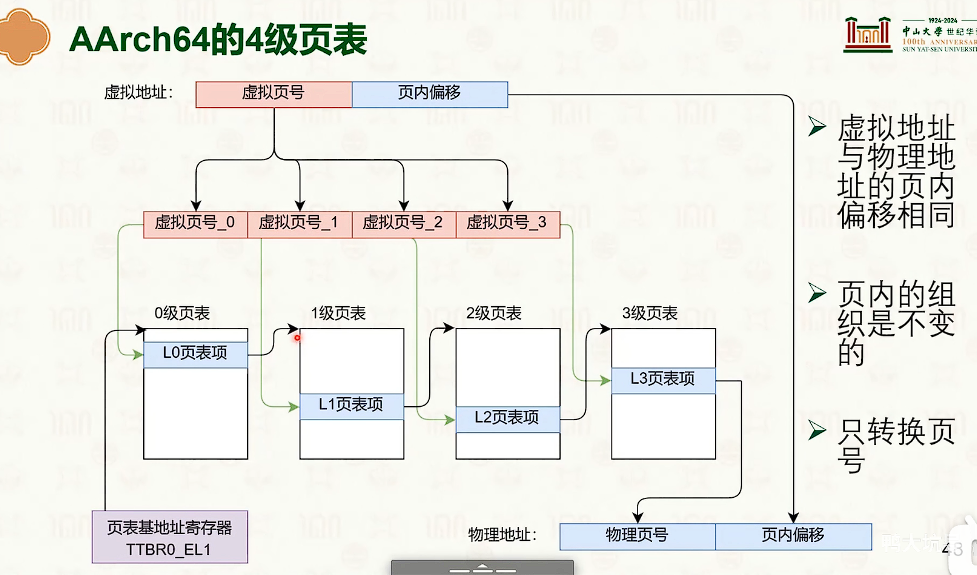
-
紫色表示硬件
-
蓝色表示物理地址
-
红色表示虚拟地址
-
分页虚拟内存没什么外部碎片,但是有一定的内部碎片。
-
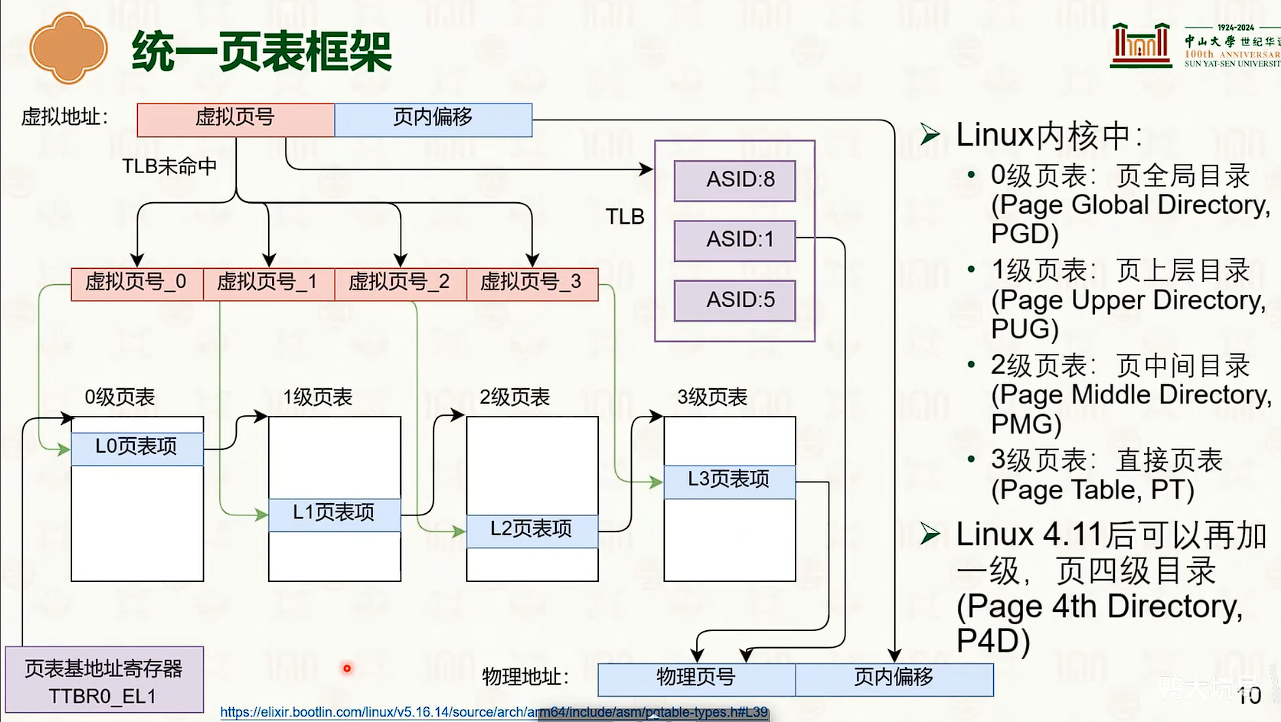
操作系统创建,操作系统管理,MMU查询


- 因为页内偏移量是不需要的,这12bit是没有意义的。
- 对于页表来说,高一些位默认是1111,或者0000,也是没有实际意义。

- 多级页表的设计是时间换空间是trade-off
- 那可以使用MMU中的TLB来加速翻译的过程。
TLB:地址翻译加速
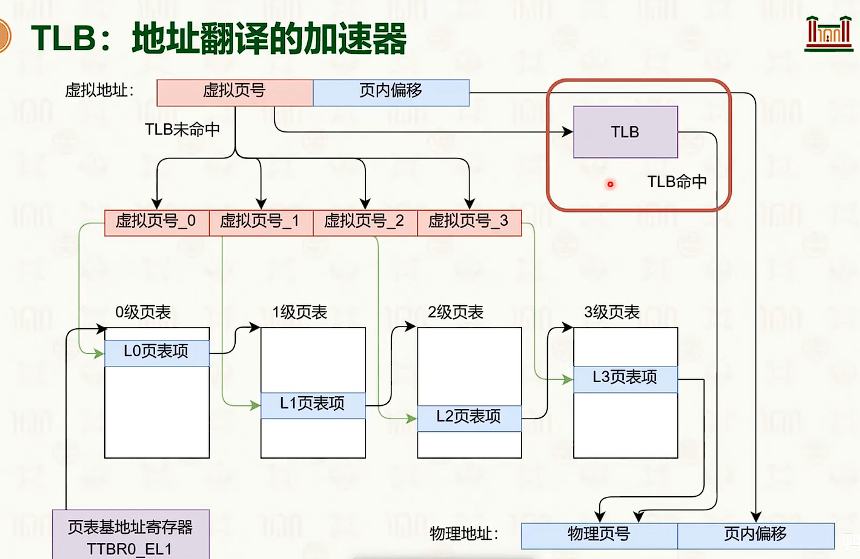
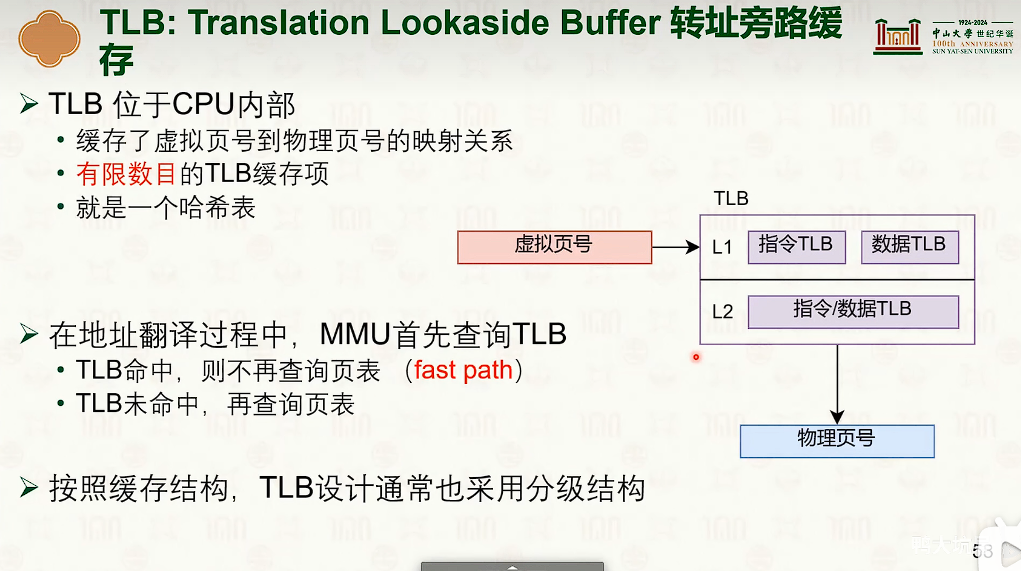
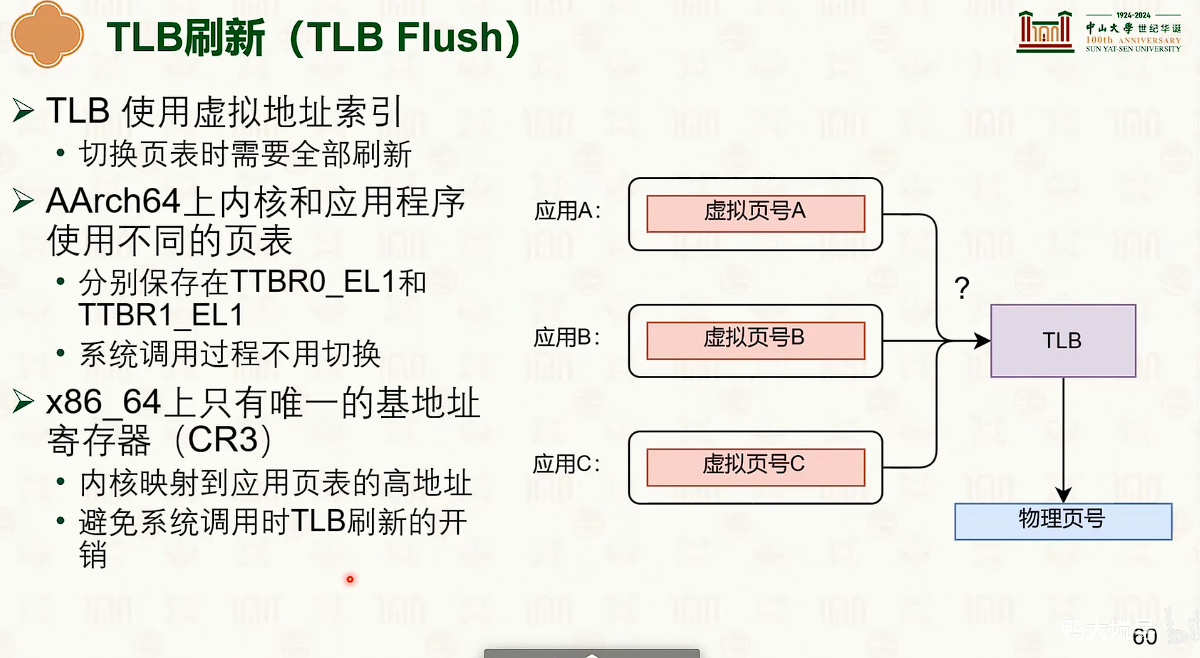
- 为了防止多个进程相互访问内存地址,必须对TLB进行刷新。
- 不过可以设置一些条件。

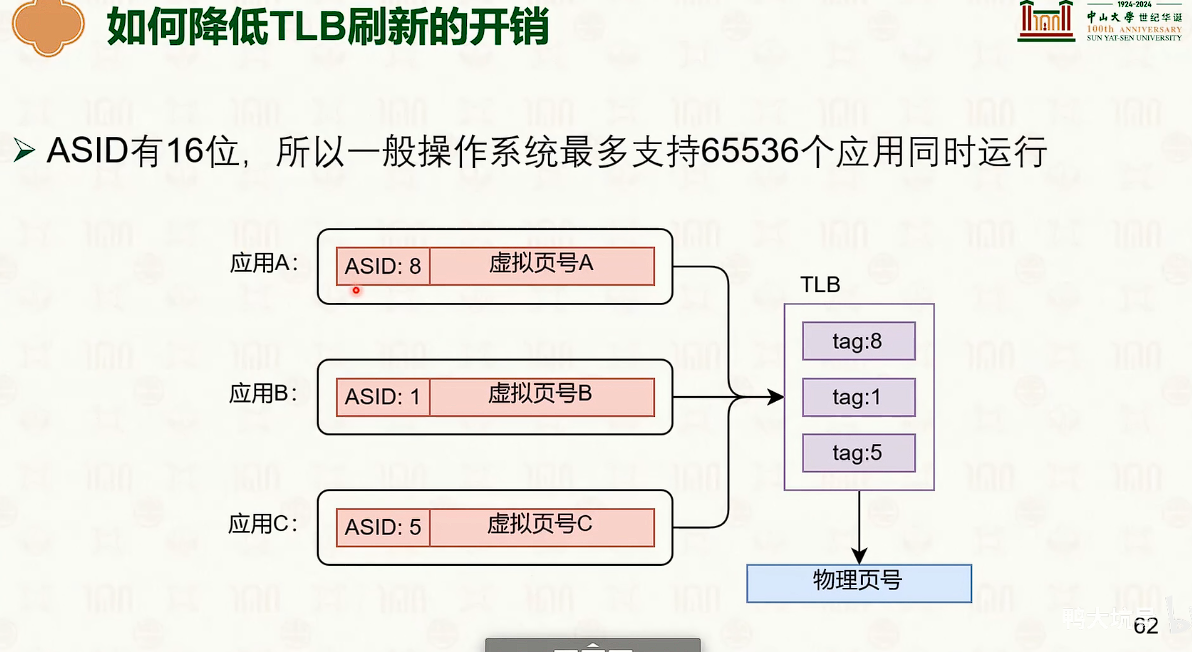
- 内核态的高 16 bit为111,非内核为 000
- 内核态有自己的页表基址寄存器,与非内核态有隔离,所以从内核态到非内核态不需要刷新。
- 对非内核态,使用高16位对进程进行标记。

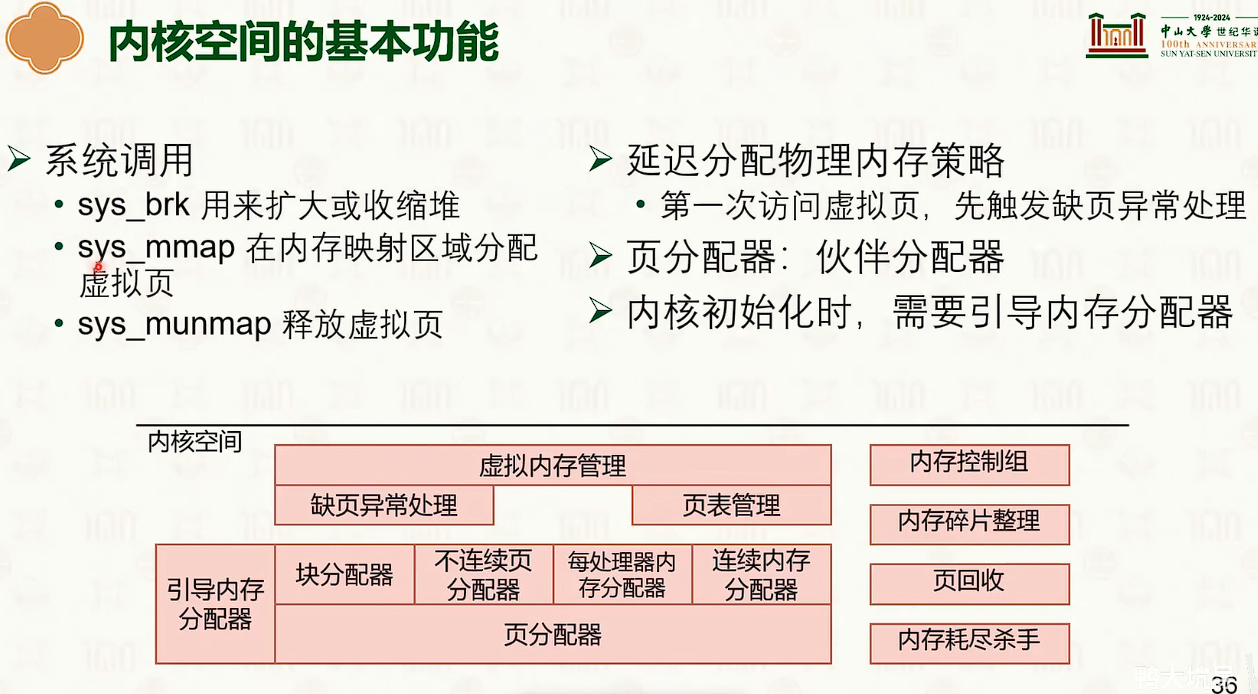
虚拟内存管理:拓展功能

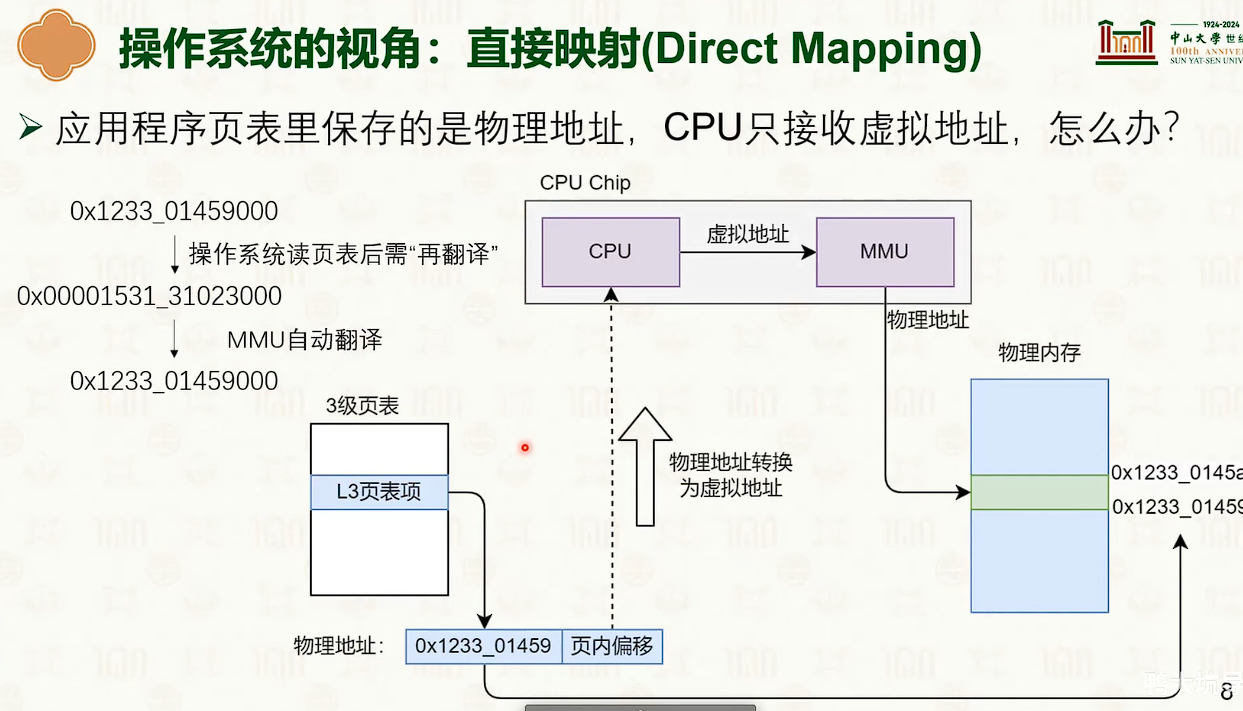
直接映射
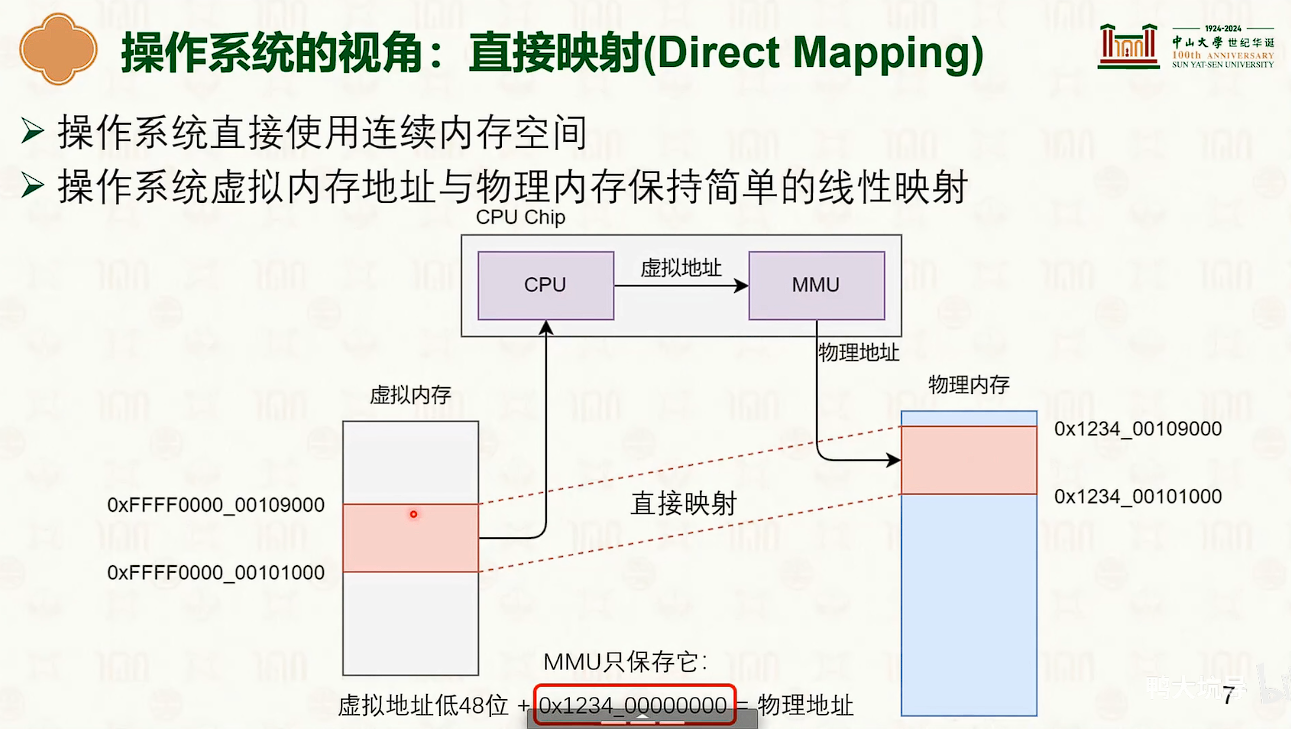
- 操作系统本身不需要复杂的页表。只是有一个自己的页表基址寄存器,简单相加即可。
- 它只需要自己创建和维护一个地址即可,自己进行维护。

立即映射
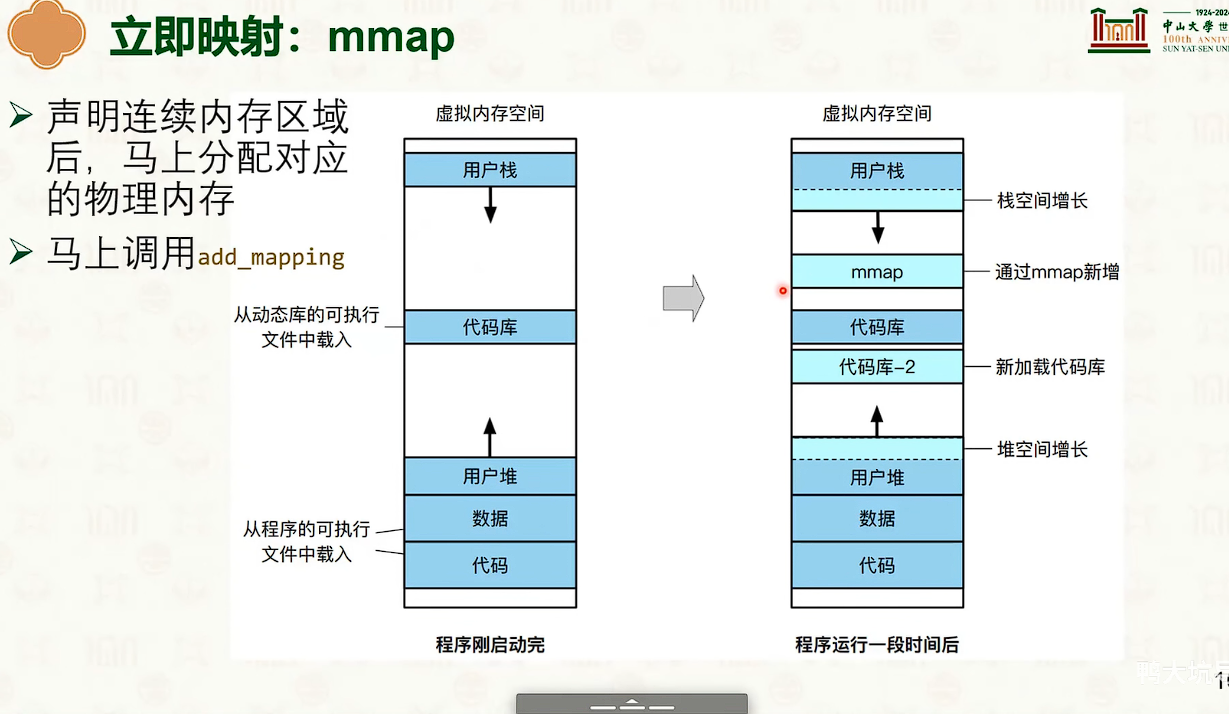
-
mmap立刻映射。立刻分配物理地址。会出现在性能要求高的地方。
-
但是需要在mmap中填写MAP_POPULATE参数,否则默认都是延迟映射
-
栈空间的物理内存分配在发生栈溢出(访问未分配的栈地址)时触发,通过缺页中断处理。

延迟映射
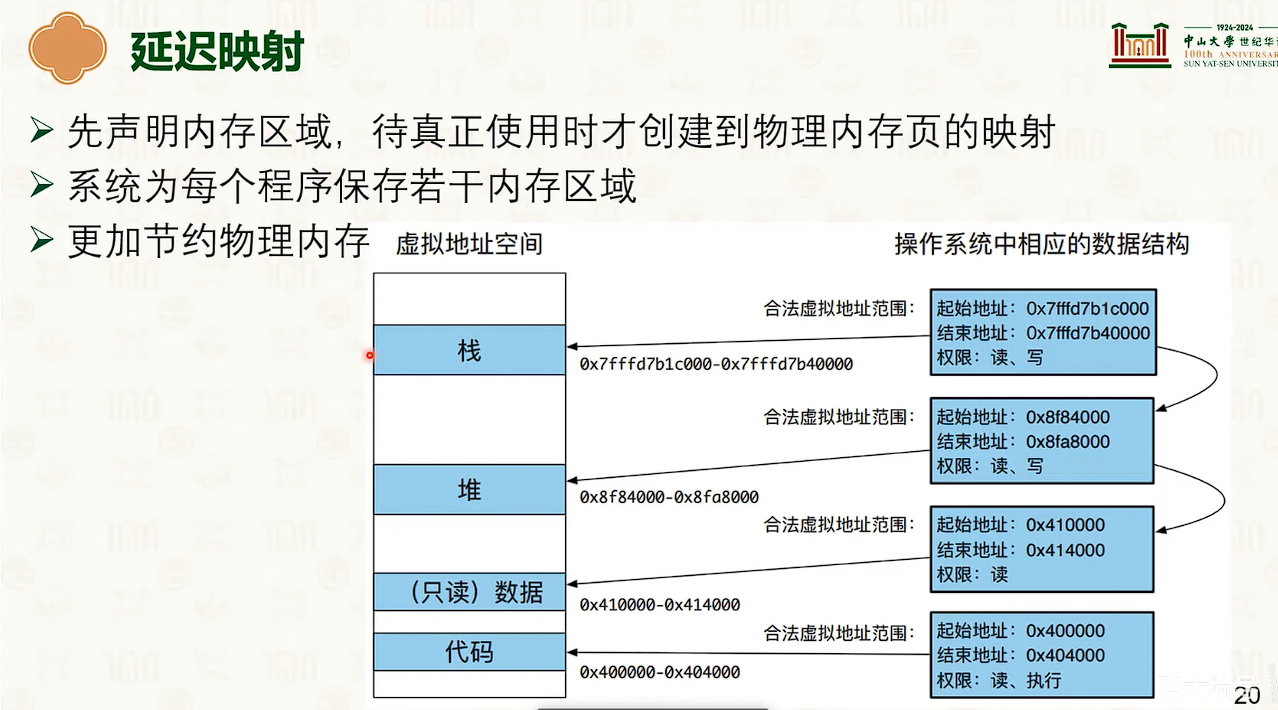

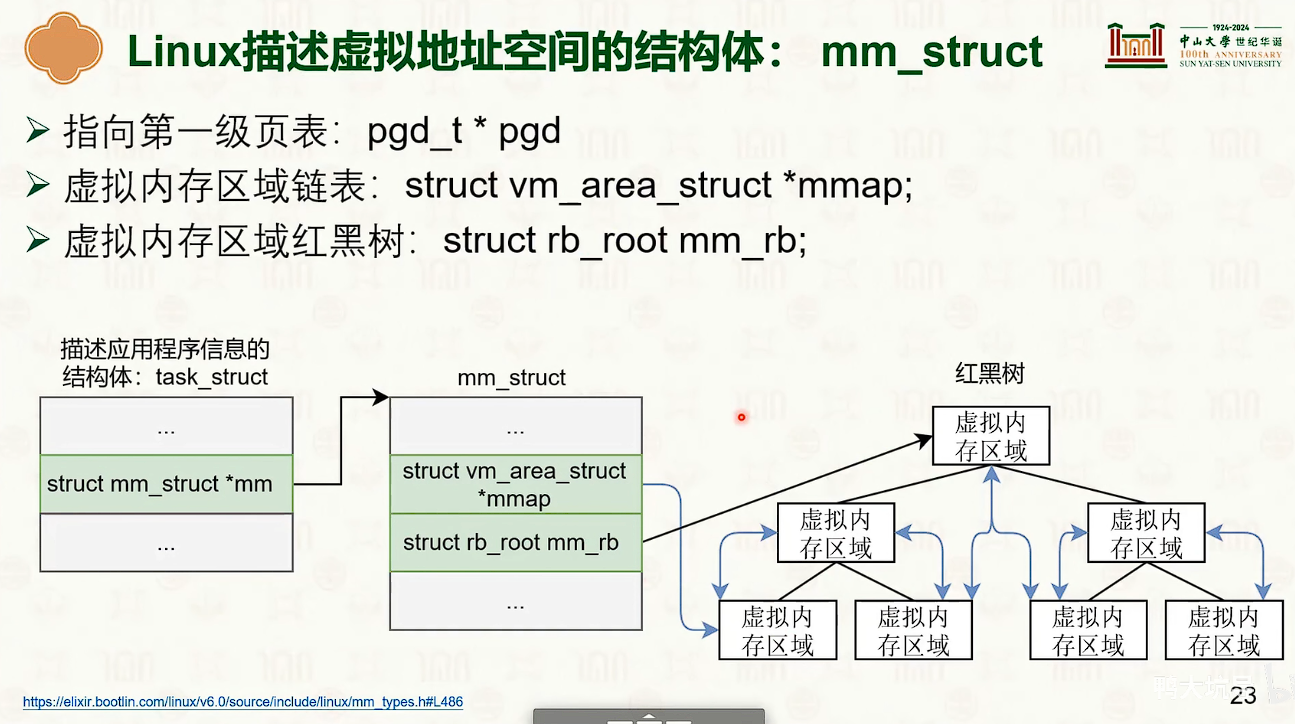
- 默认情况下,如果第一次访问地址都是延迟映射,触发缺页异常。
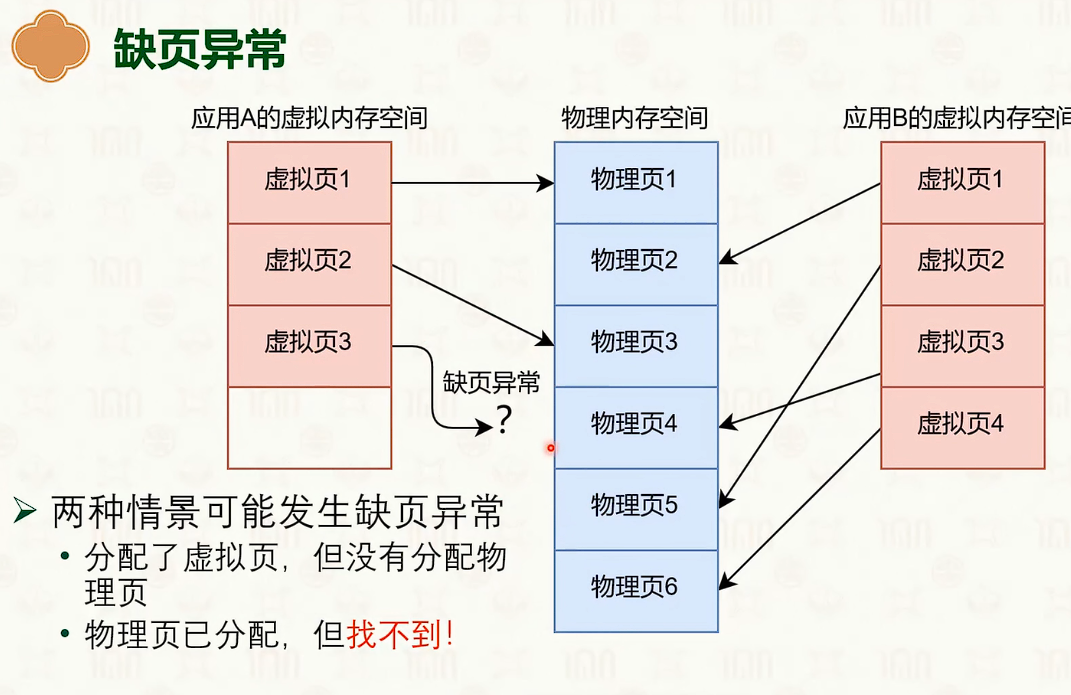
缺页异常
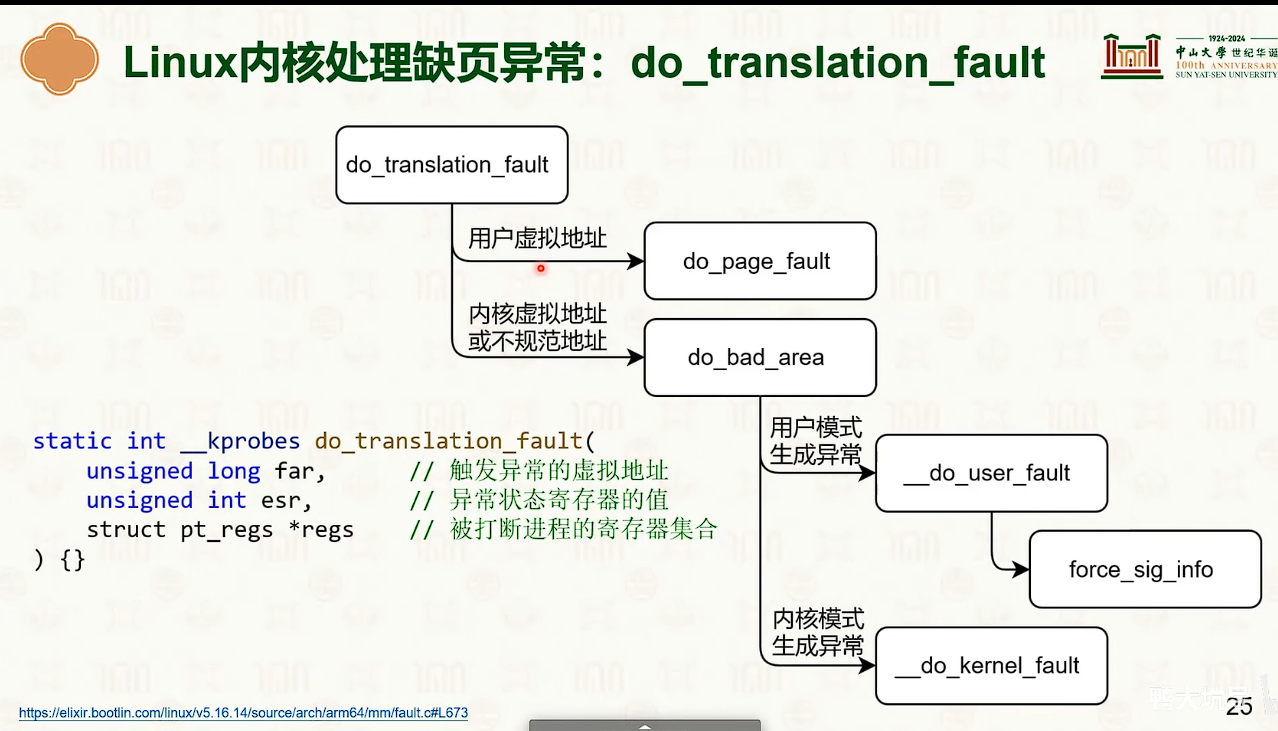
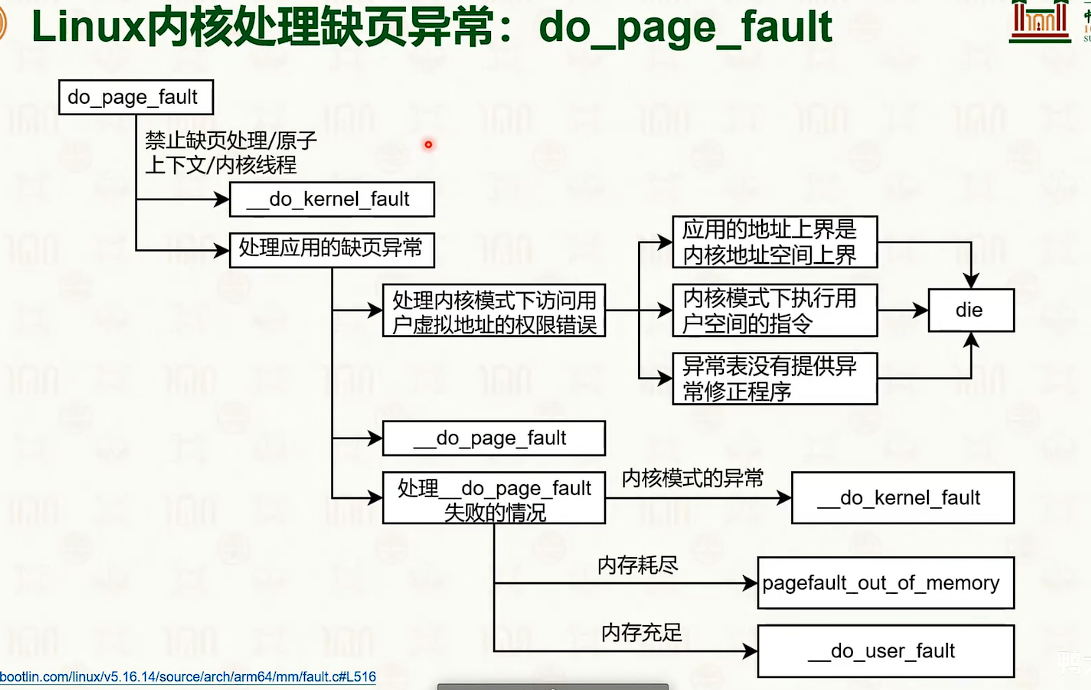
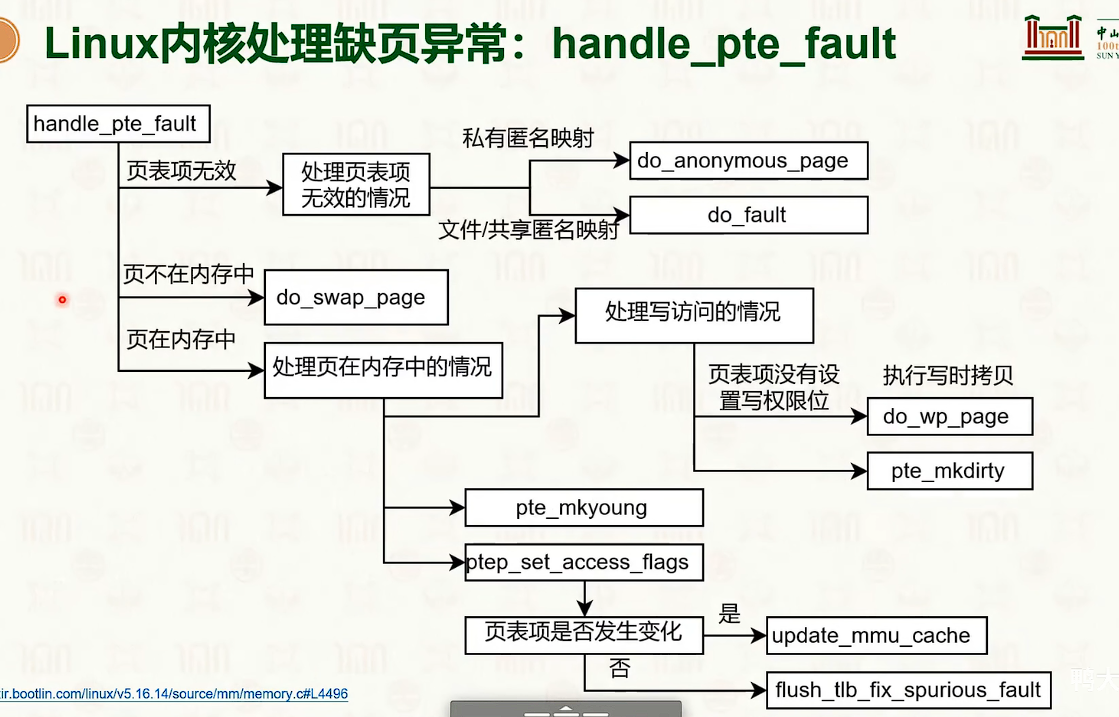

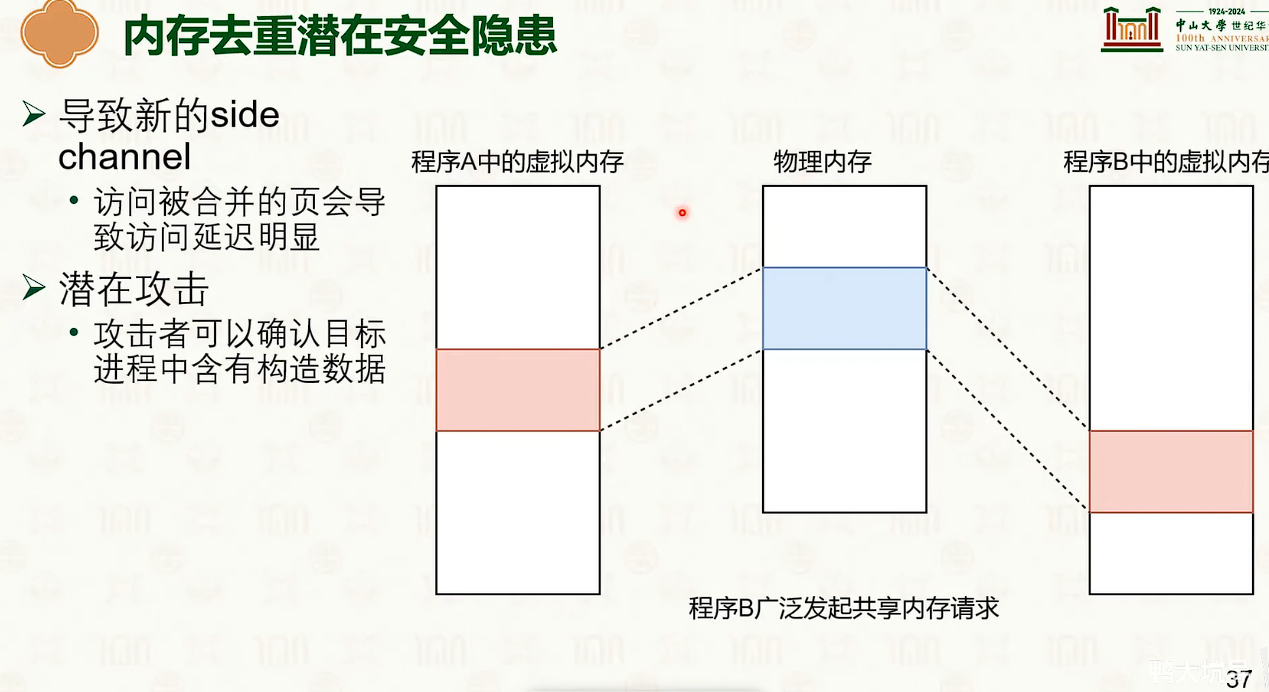
共享内存
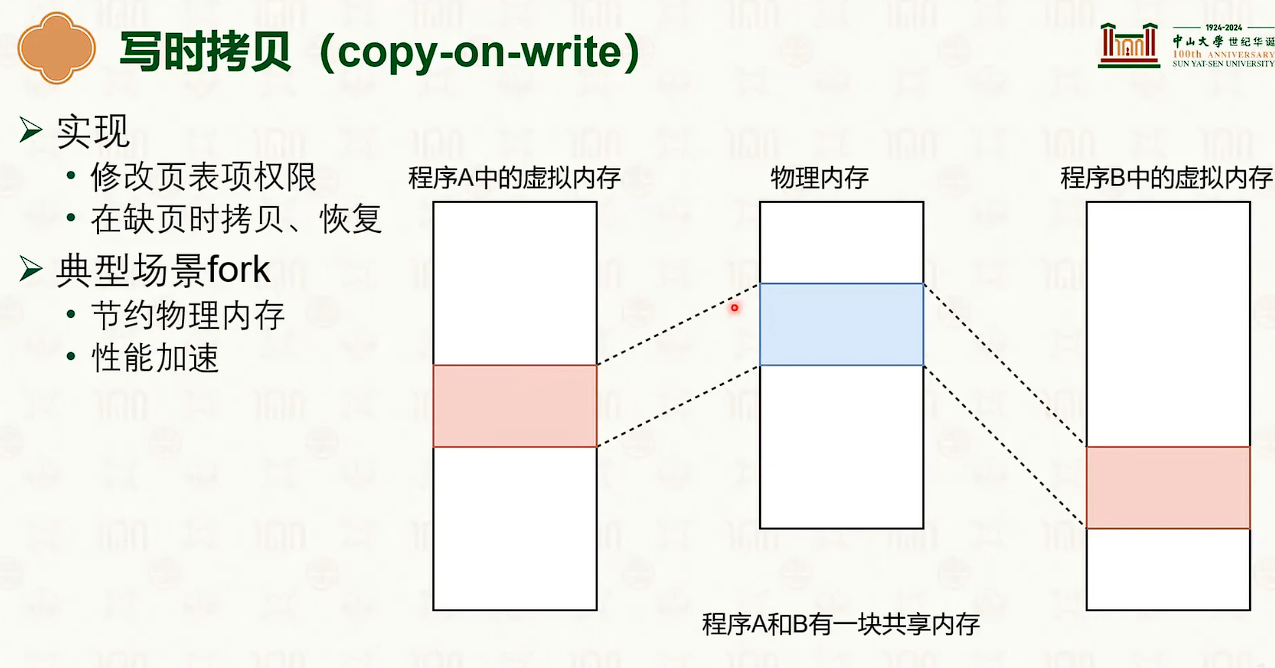
- 共享内存存在权限操作,如果权限冲突。
- 那么在写的时候会触发copy on write,之后触发重映射


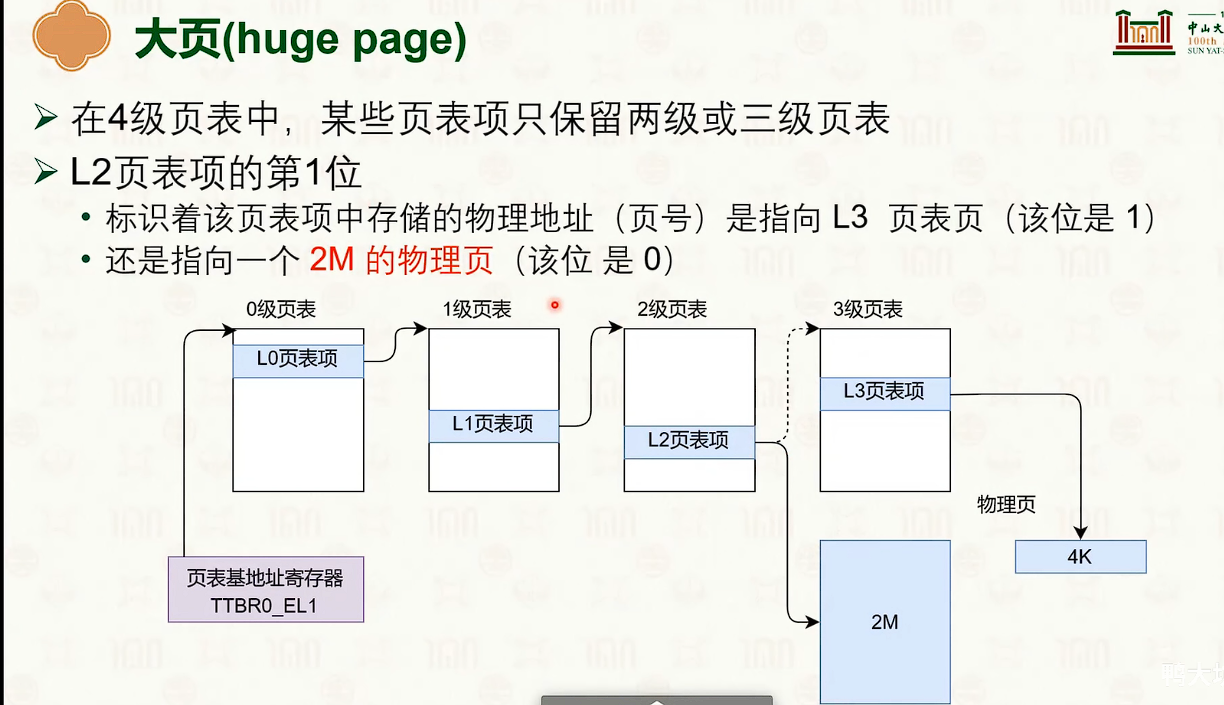
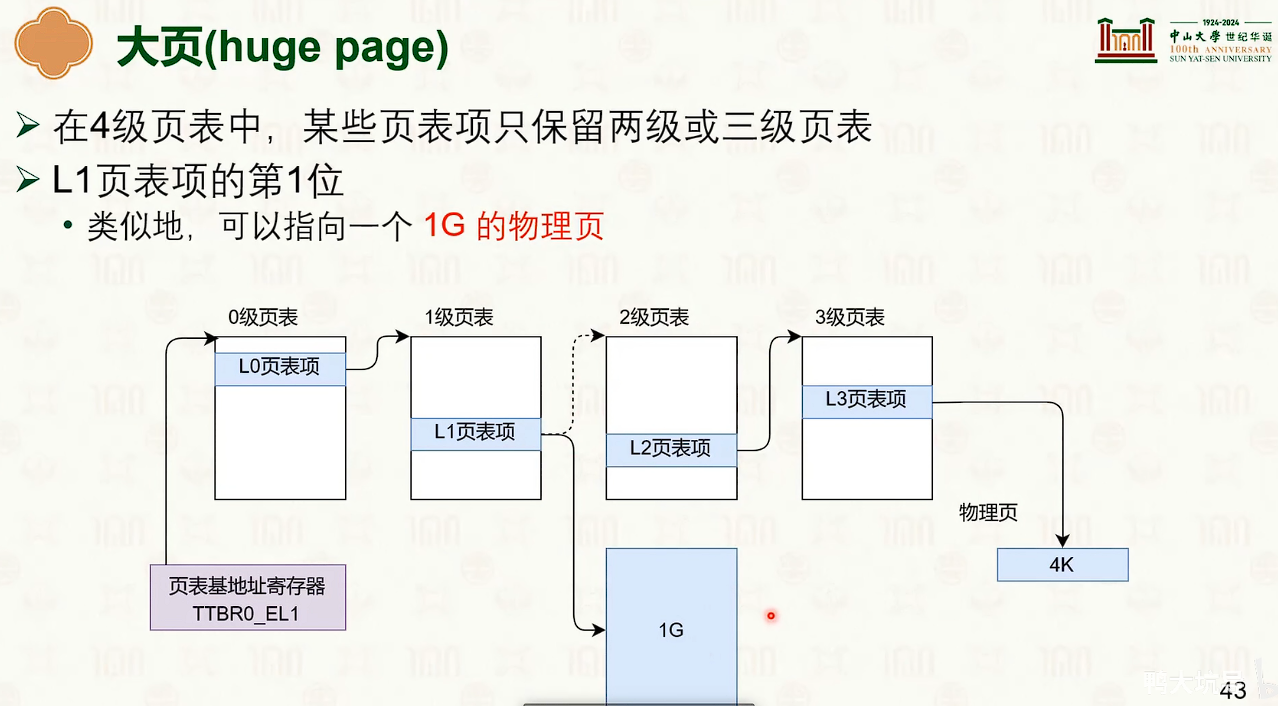
大页

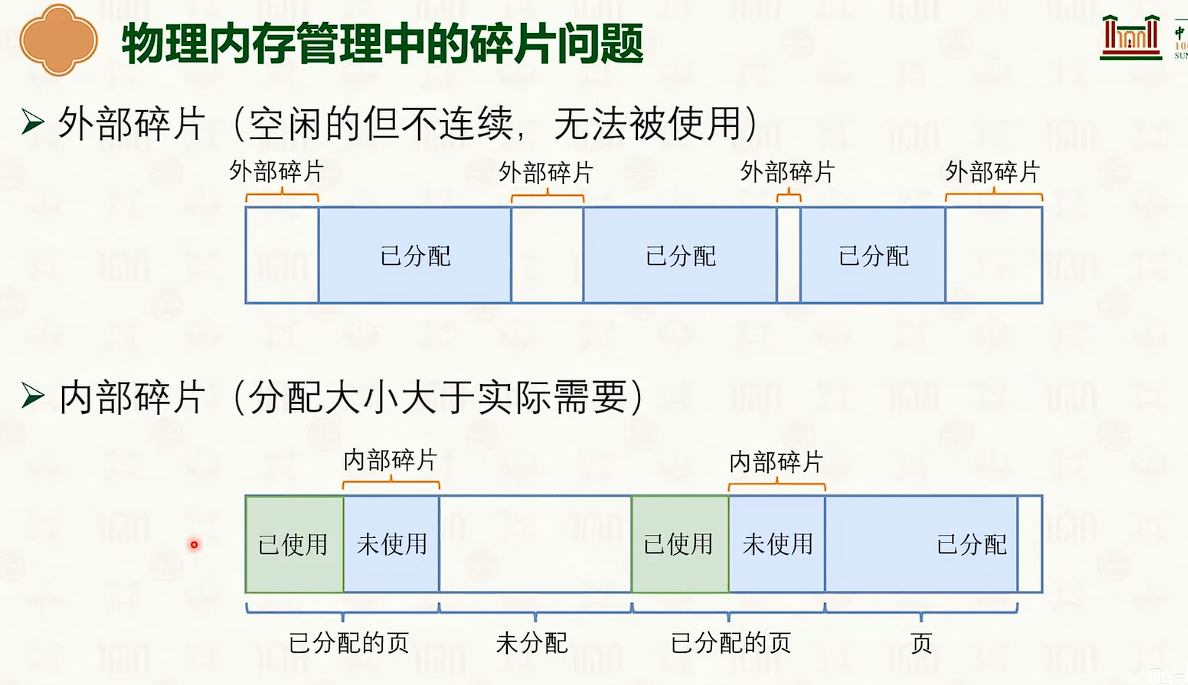
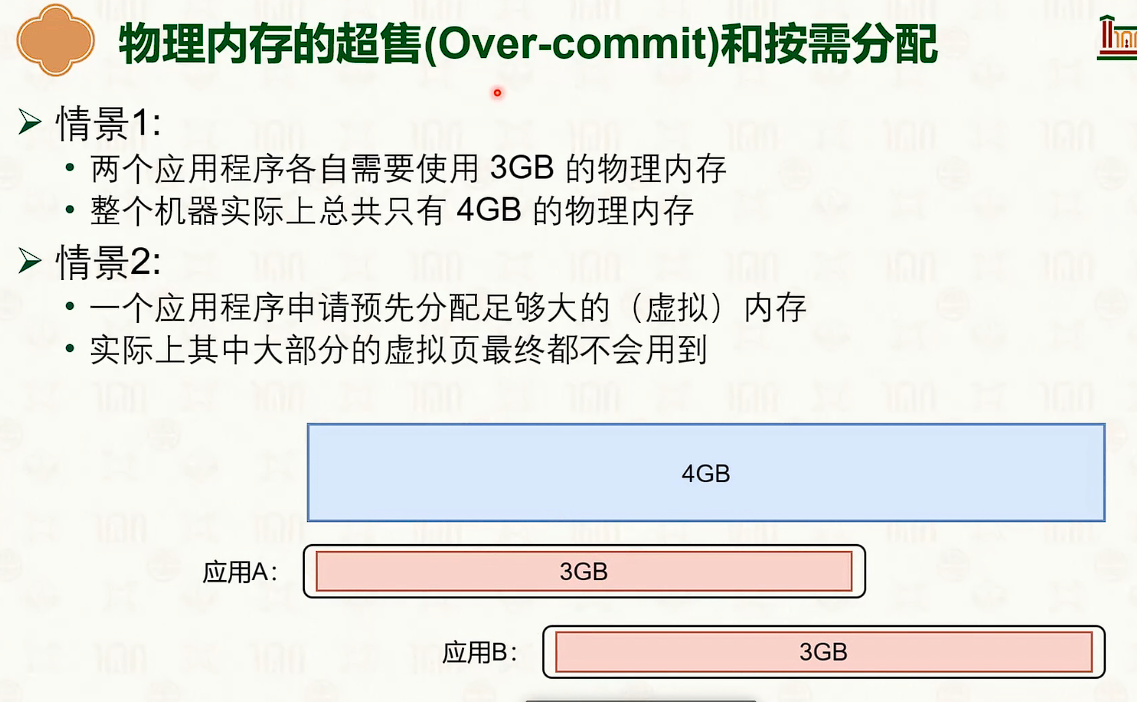
物理内存管理

物理内存管理:伙伴系统
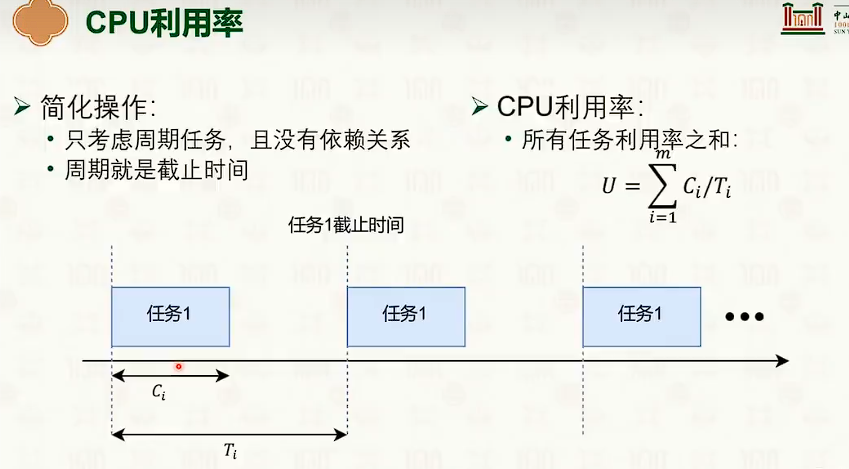
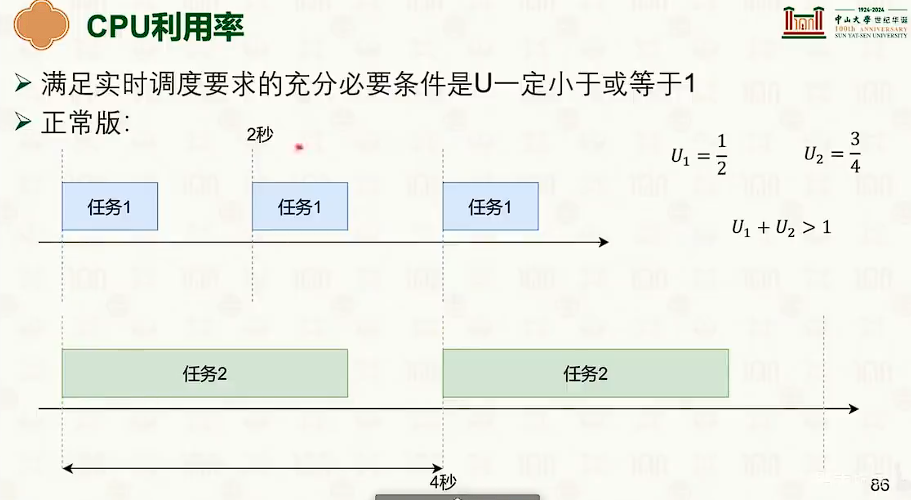
评价维度

- 哈哈哈,malloc lab的经典 trade-off
基于位图的连续物理页分配。

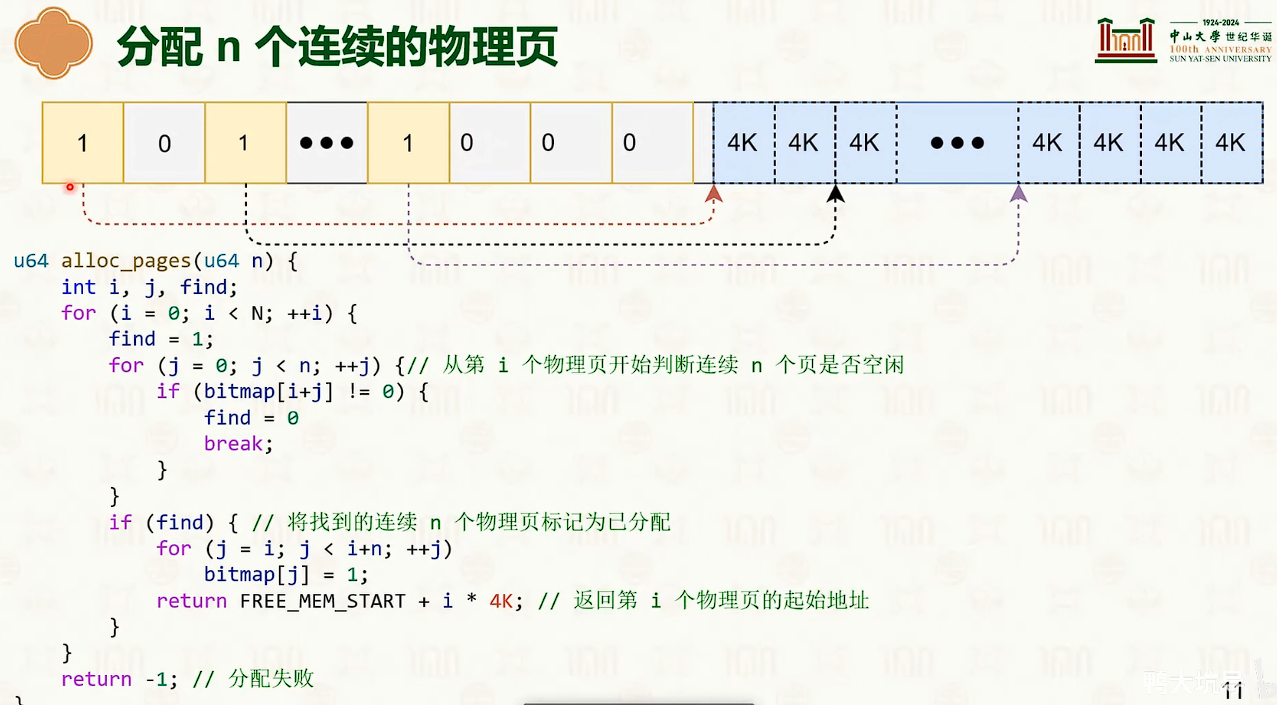
- 比较的时候可能可以使用 int64 的 & 操作,这样每次运算可以计算 64bit
- C语言没有所谓的初始化操作,int a; 可能是五花八门的,但是C++有一个所谓的初始化,int a;八成是0。
- 其他大小一致的以块/页划分的存储结构,可能存在一个类似 bitmap,比如文件系统,可能也是这样的结构。
- 位图的效率低。
- 这里给出的代码是物理地址连续的,但是实际上不一定是物理地址连续的,也就是连续的虚拟地址不一定是连续的物理地址。
伙伴系统
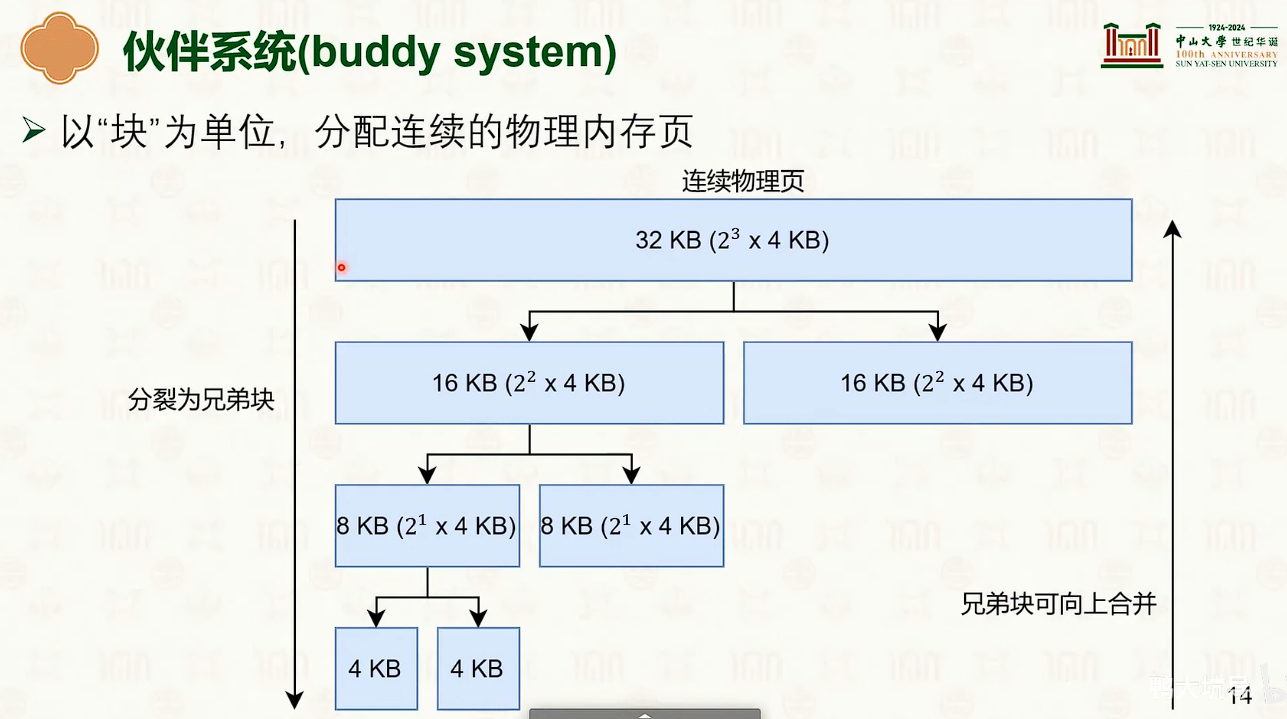
- 看到这个图,想到了csapp中说,现代的分配机制,总是倾向于把空闲块分配成少而大的空闲块,而不是多而小的空闲块。
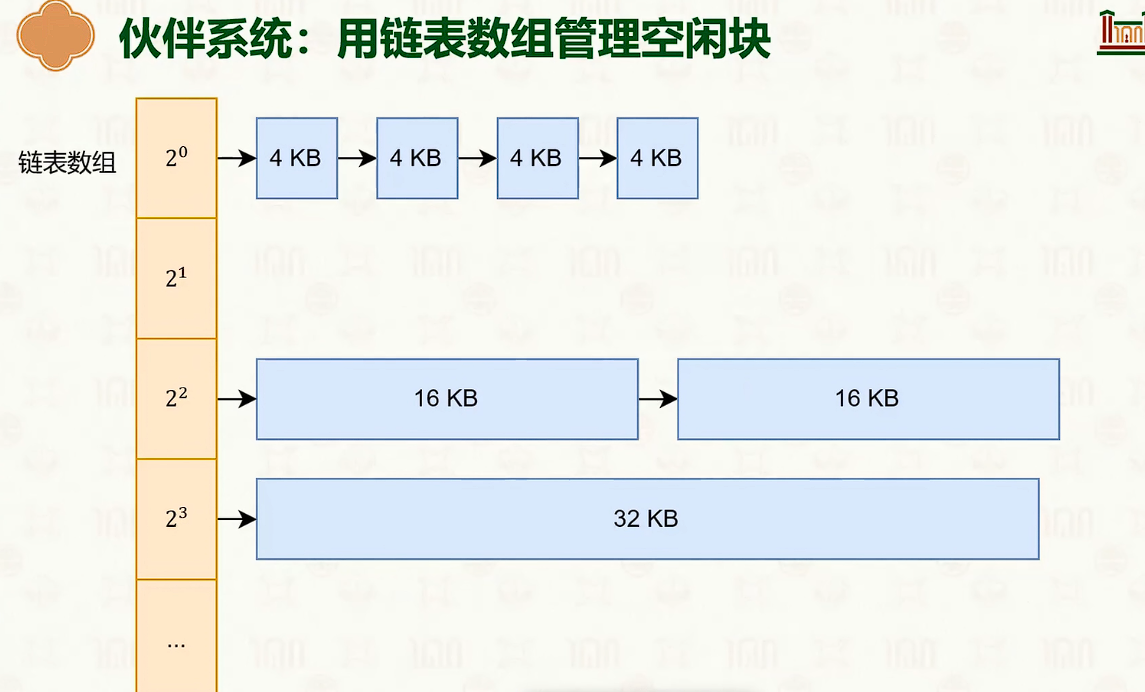
- byd,这不就是malloc lab里面的显示链表法吗。
- 分裂与合并,链表的创建,大小类的合并,最优最先匹配。。。。熟悉的知识。
- 伙伴也就是说物理地址相邻的地址,说白了其实是一样的。
- 在 4K 地址对齐之后,互为伙伴的块,只有1bit不同。
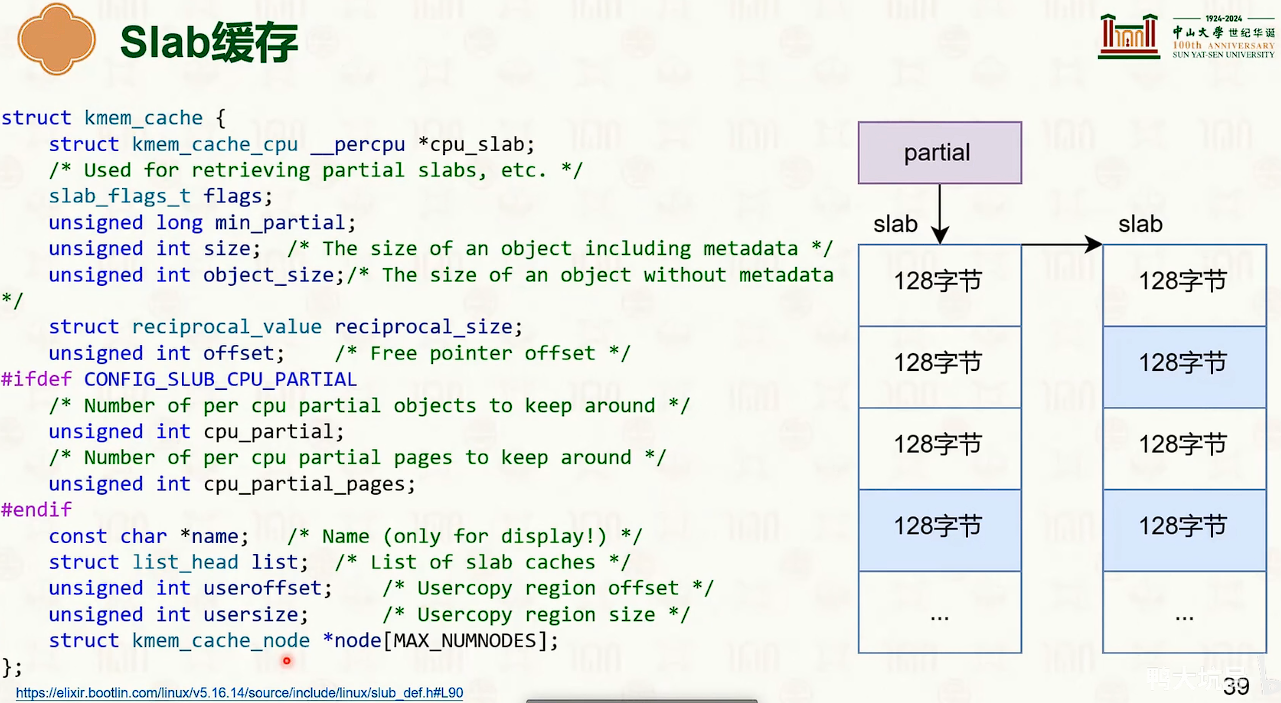
SLAB分配器家族(Linux)

SLAB分配器
SLUB分配器
SLOB分配器
- 伙伴系统分配的最小单位是一个物理页 4K。
- 但是常用的结构体大小常常不大。 -> SLAB 分配器,快而小。
- 避免过多的内部碎片。

- 设置一个特殊的大小的198字节再进一步进行精细分配。

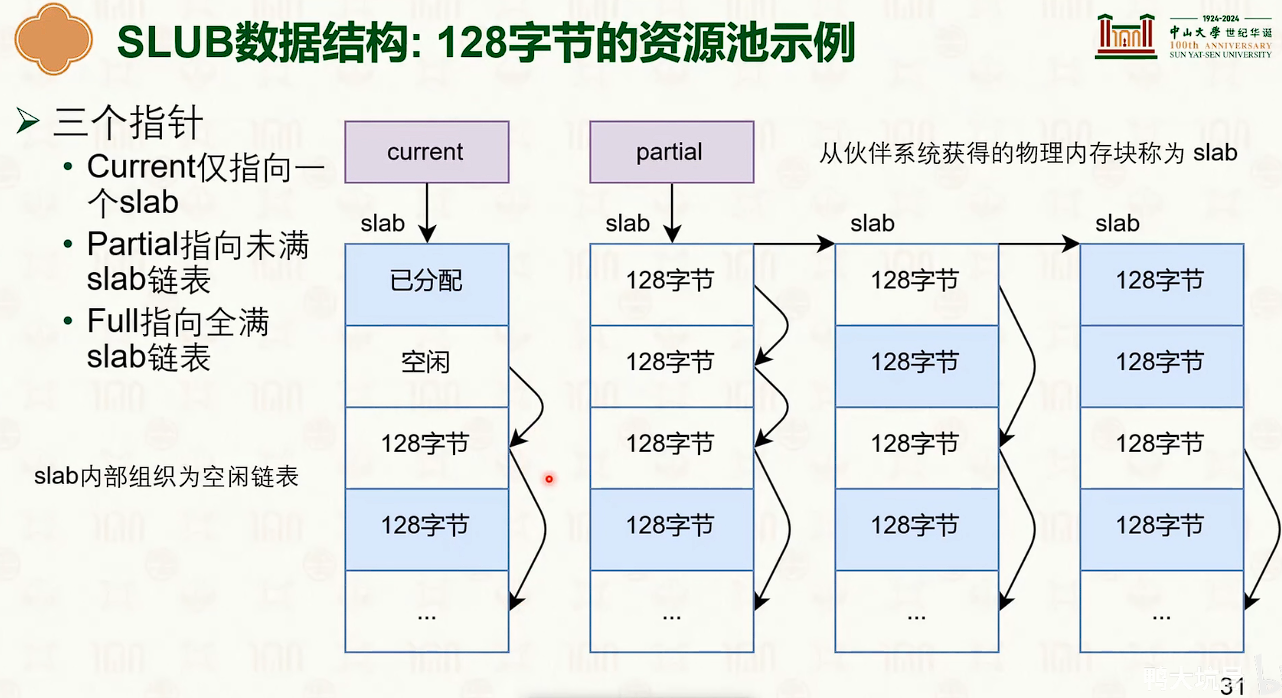
- SLAB表示这个数组
- SLUB指这整个数据结构
- 分配时
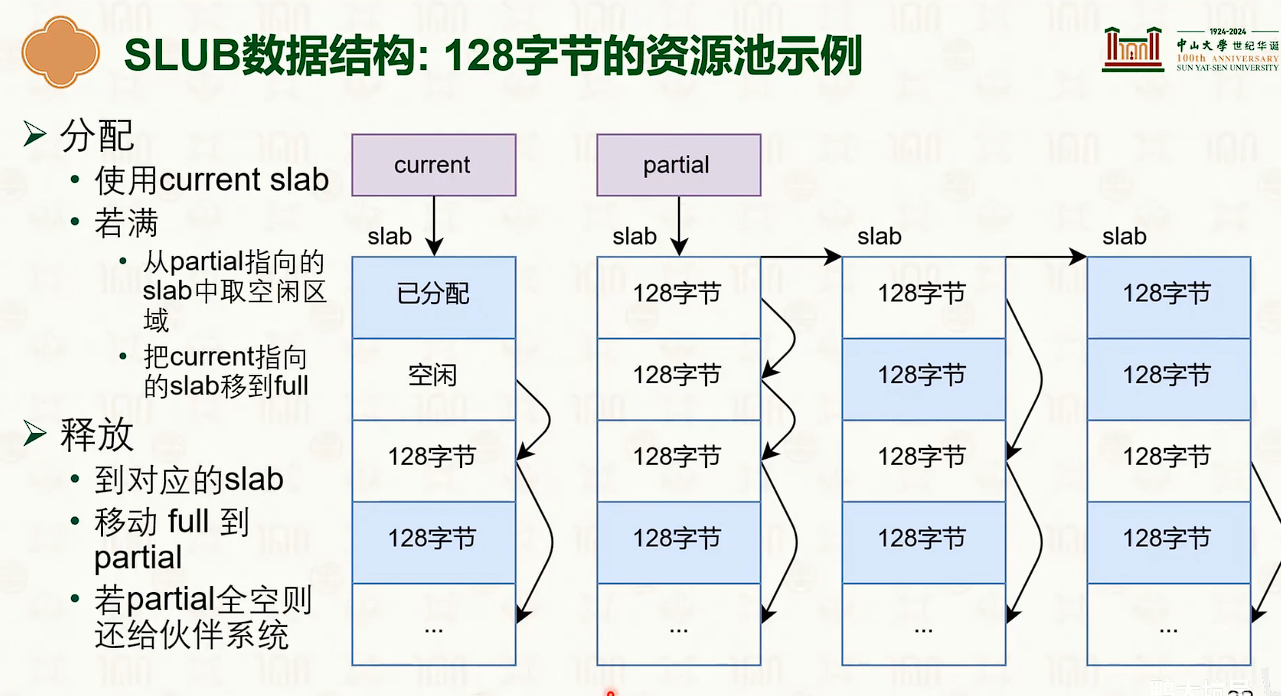
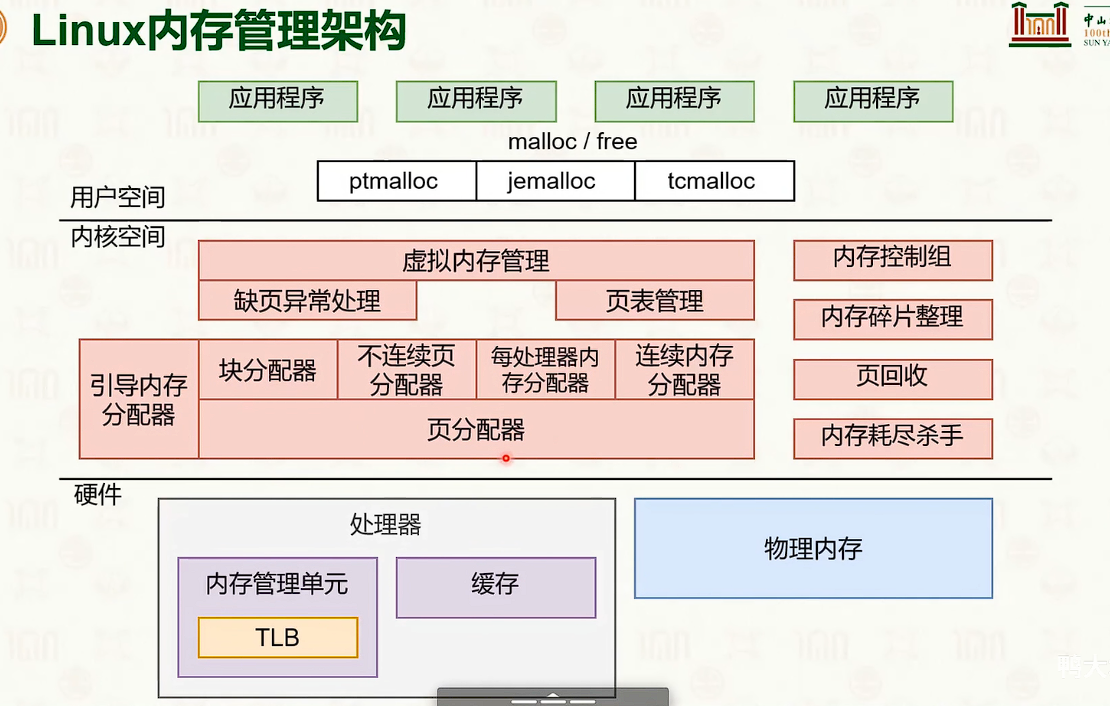

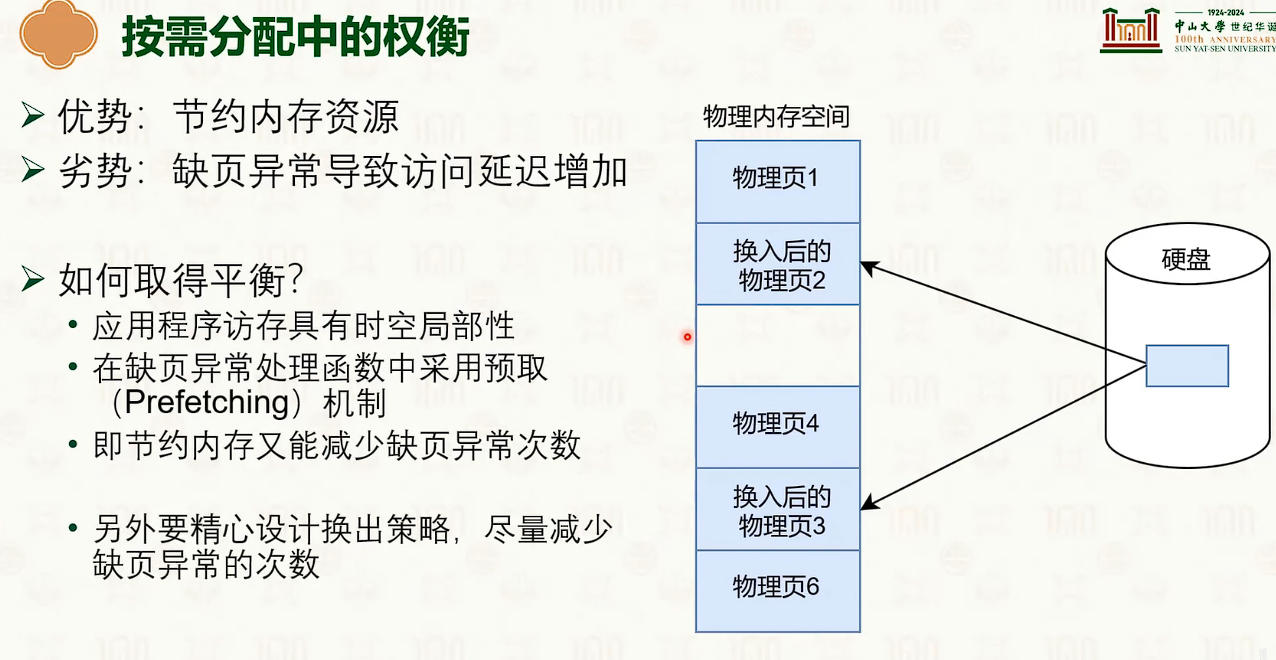
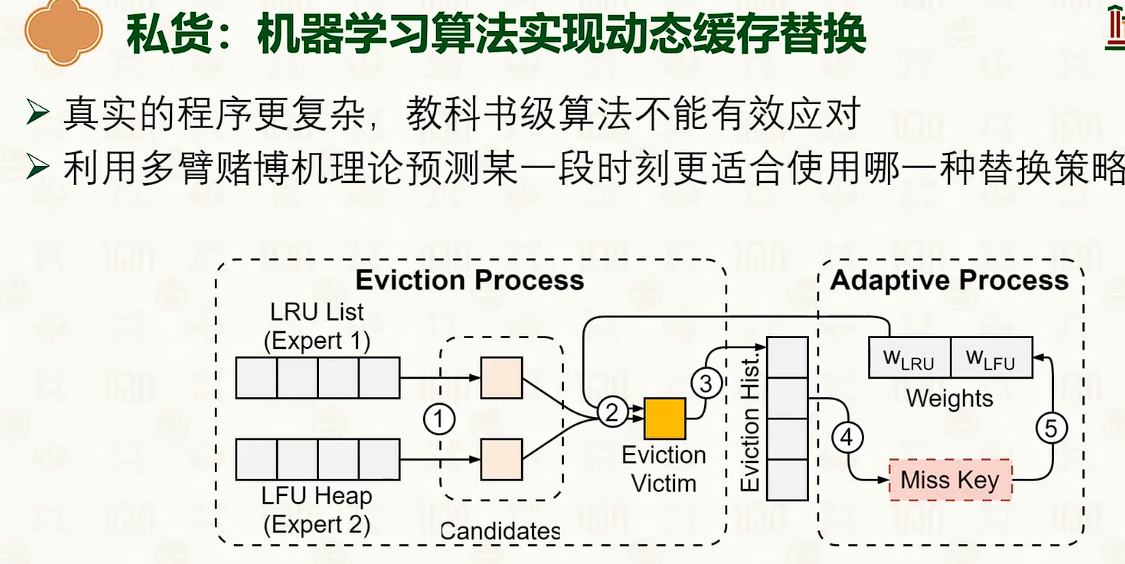
物理内存管理:页替换

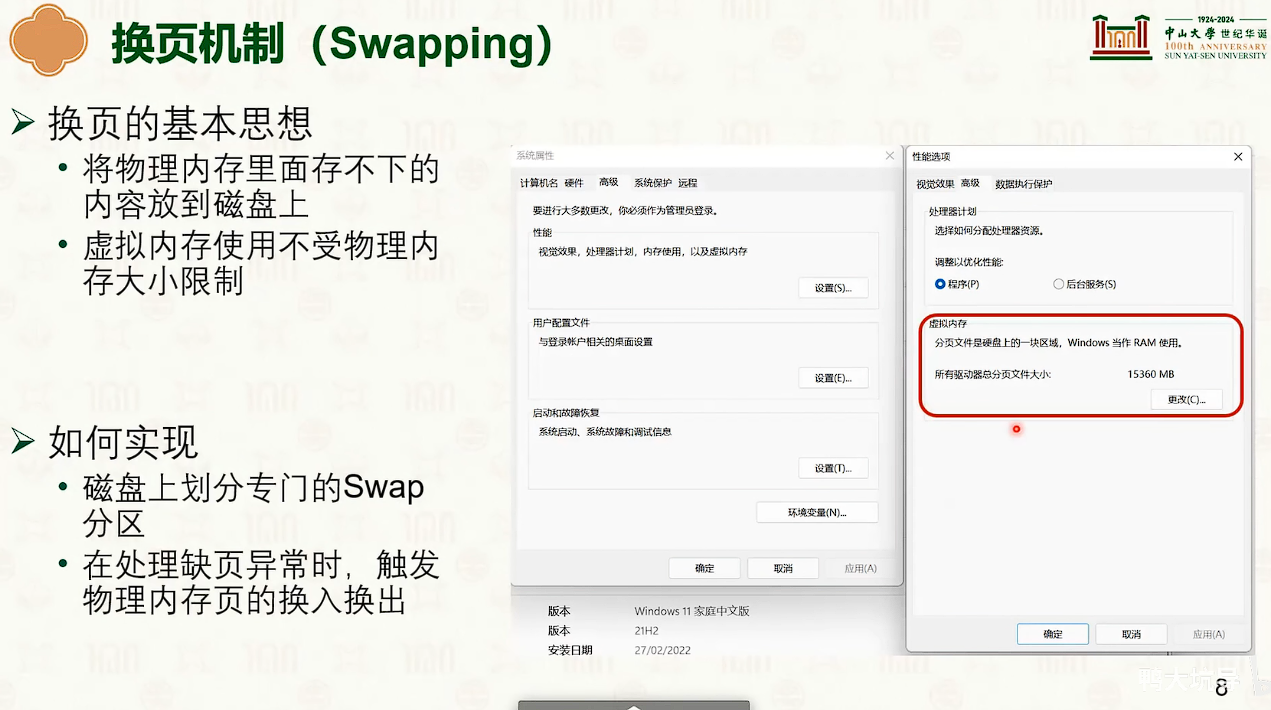
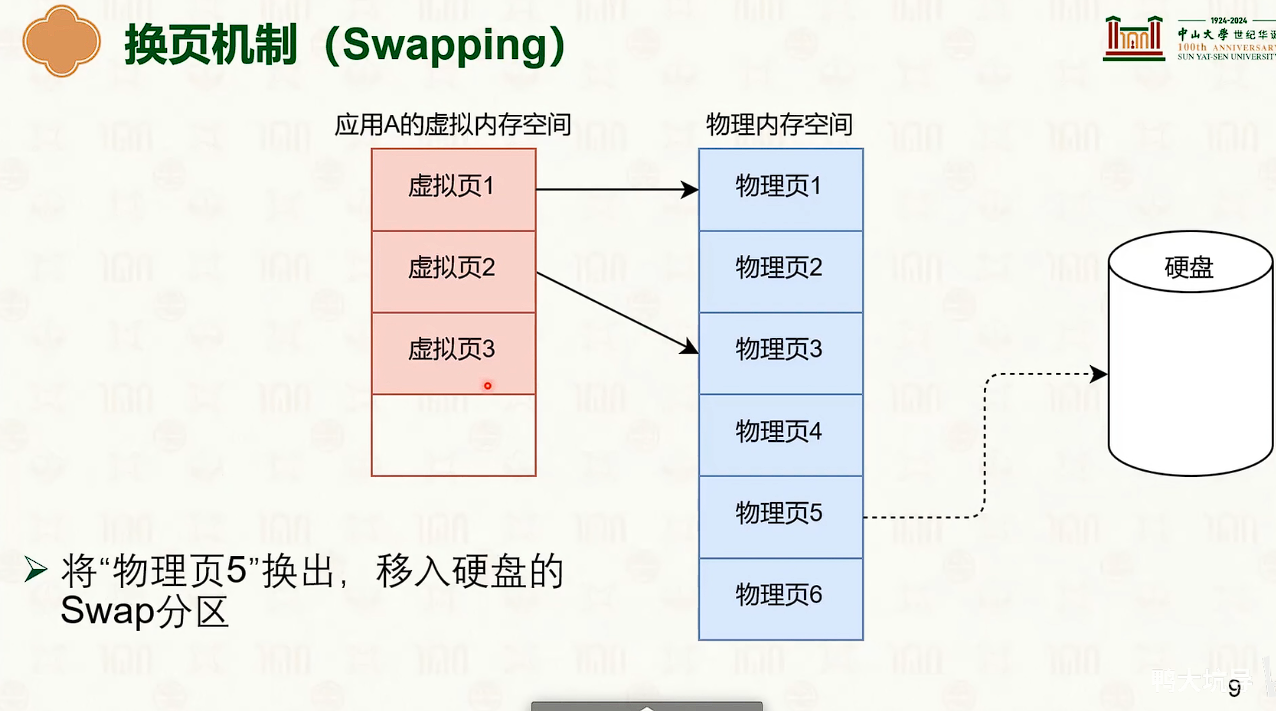
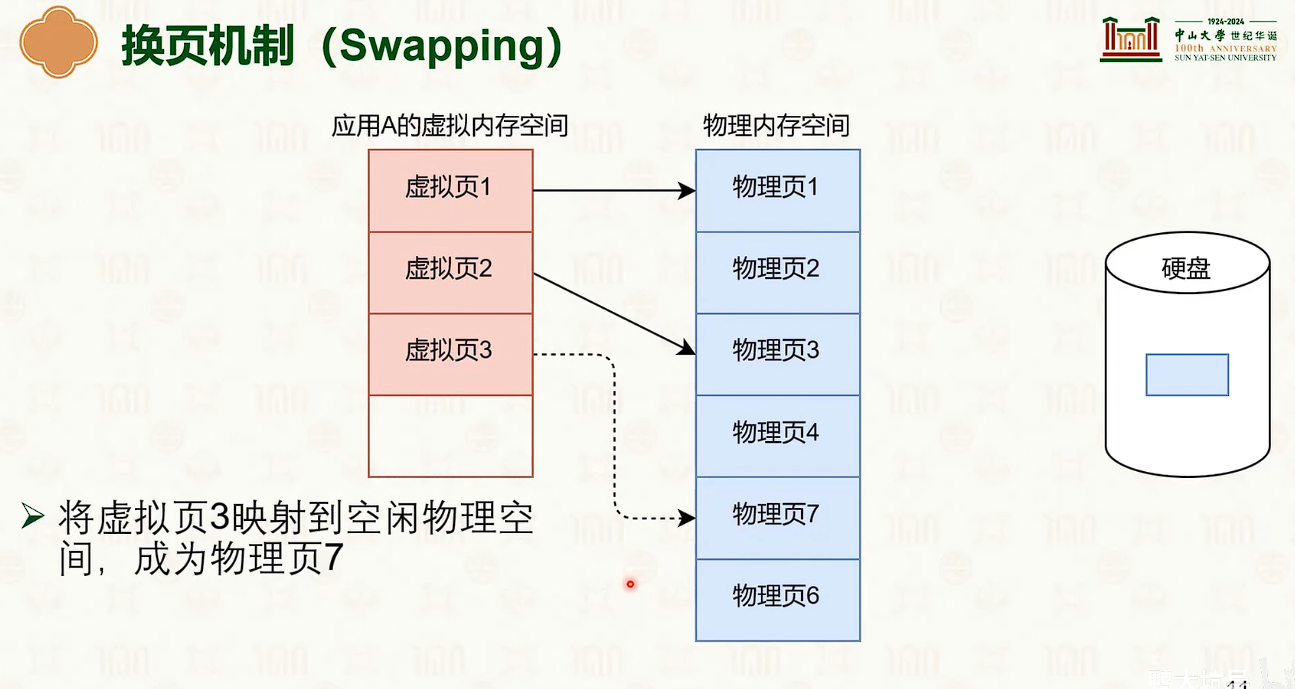
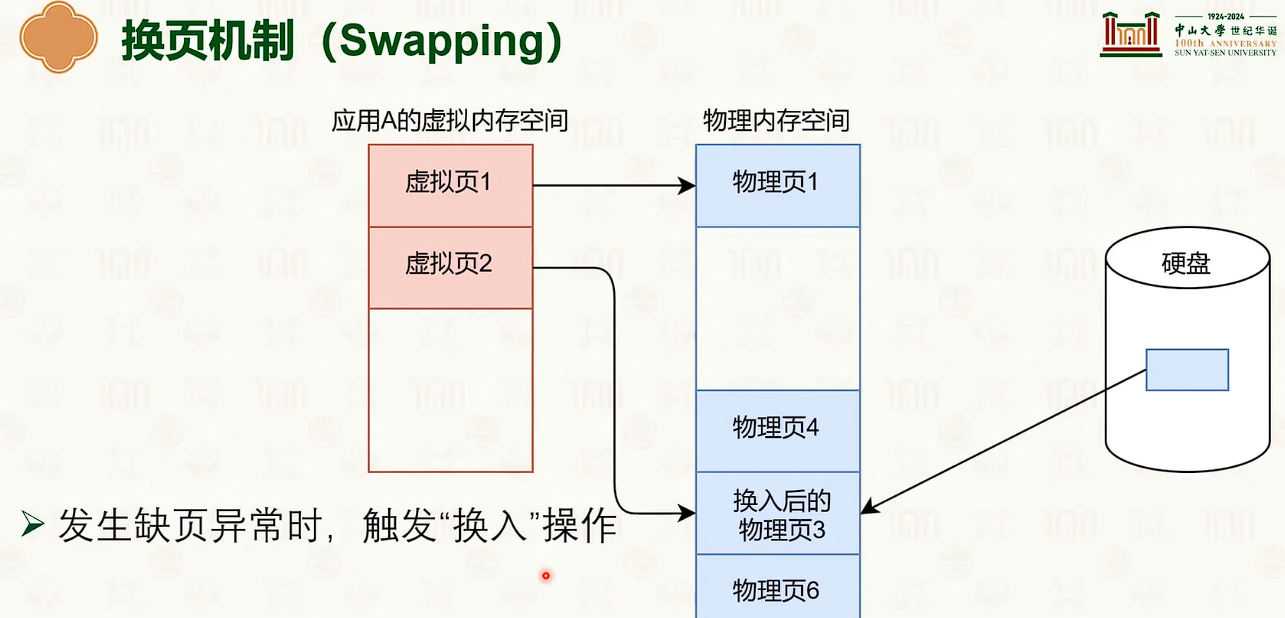
- 内存成为磁盘的缓存。
页替换策略

- MIN策略:选择长时间内不会被访问的页进行踢出。
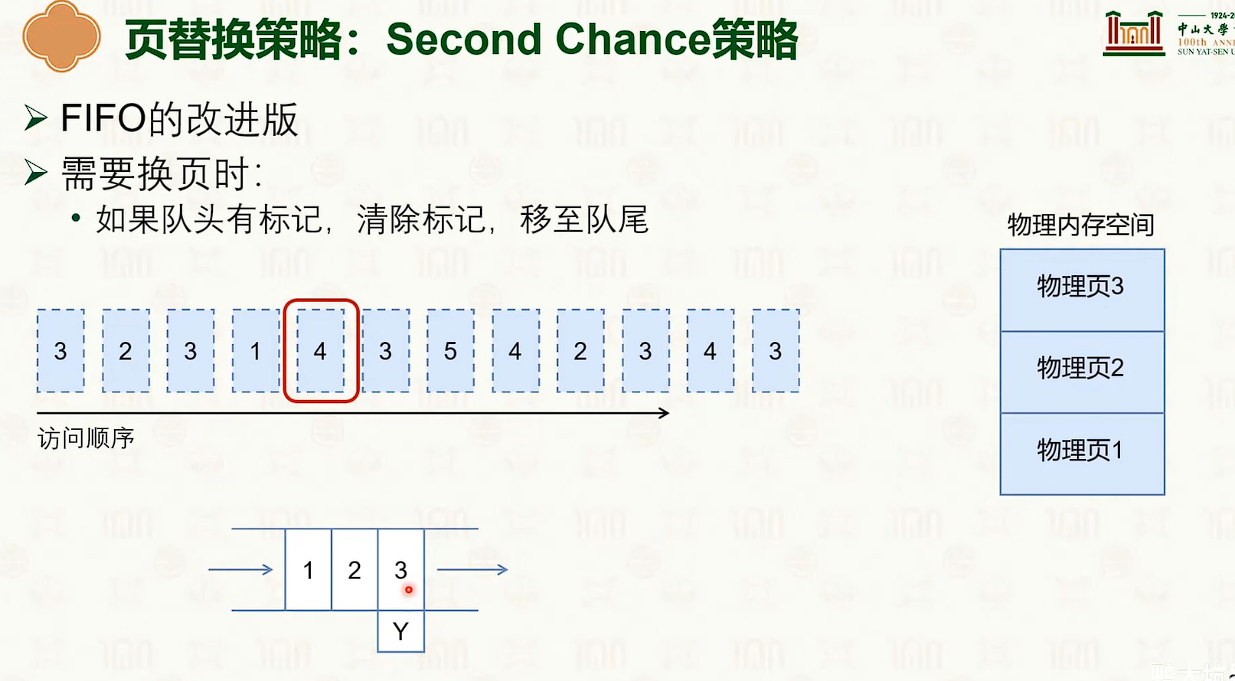
- 给 3 一次机会,如果之前已经再队列但是被访问过,那么队头加上一个标记。

- 经典LRU策略。

- 与LRU完全相反的对立,MRU策略。


工作集模型(working set method)
在工作过程中,就对程序进行规范化,在前期进行一个管理,可能会有更优得效果。
working set method.


- 和替换页策略不同。是另一种思路。
进程、线程与协程

进程的诞生和概念

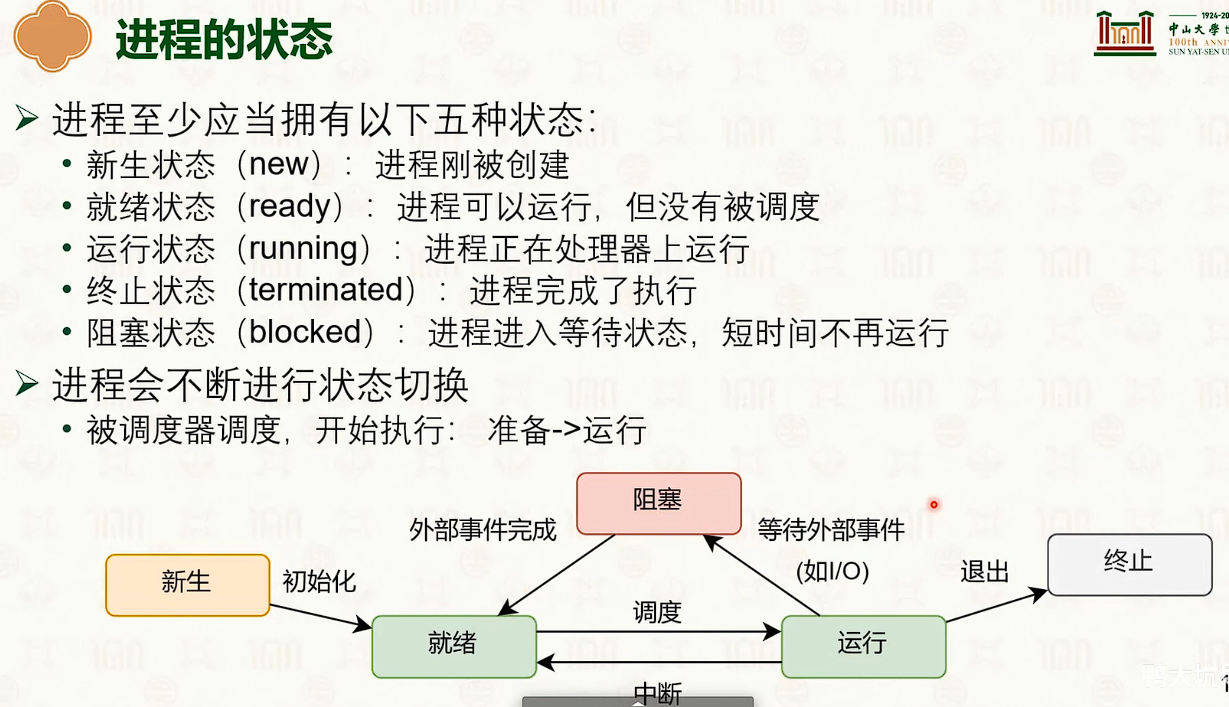
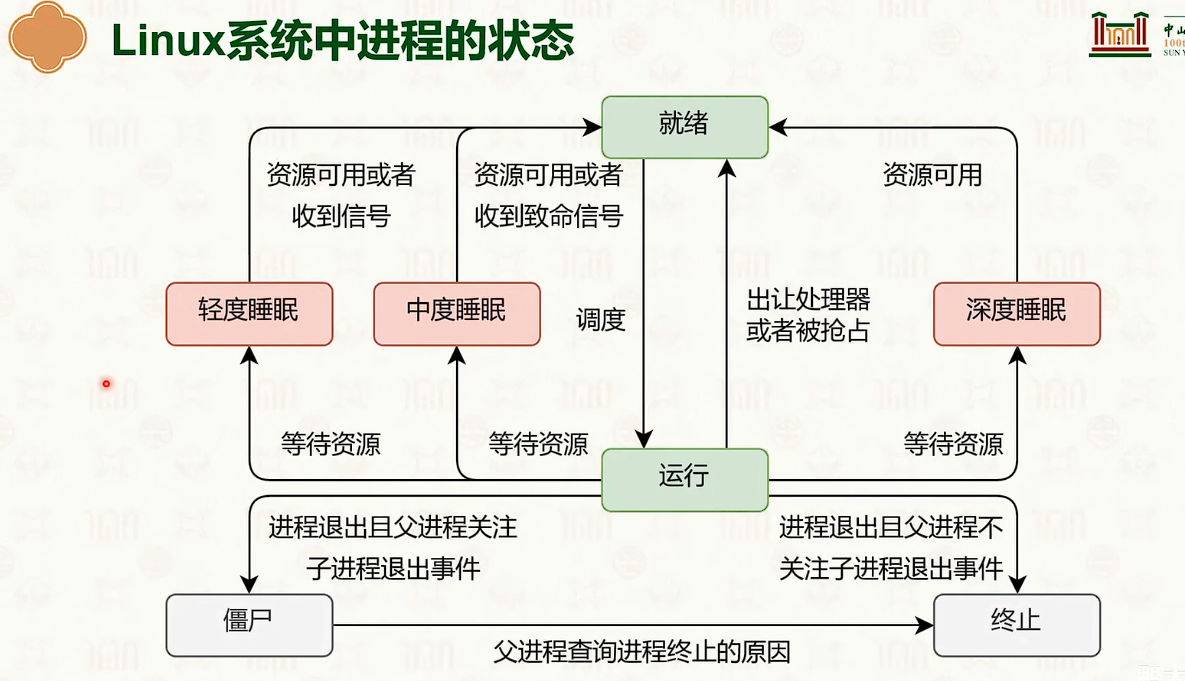
进程的状态
数据结构
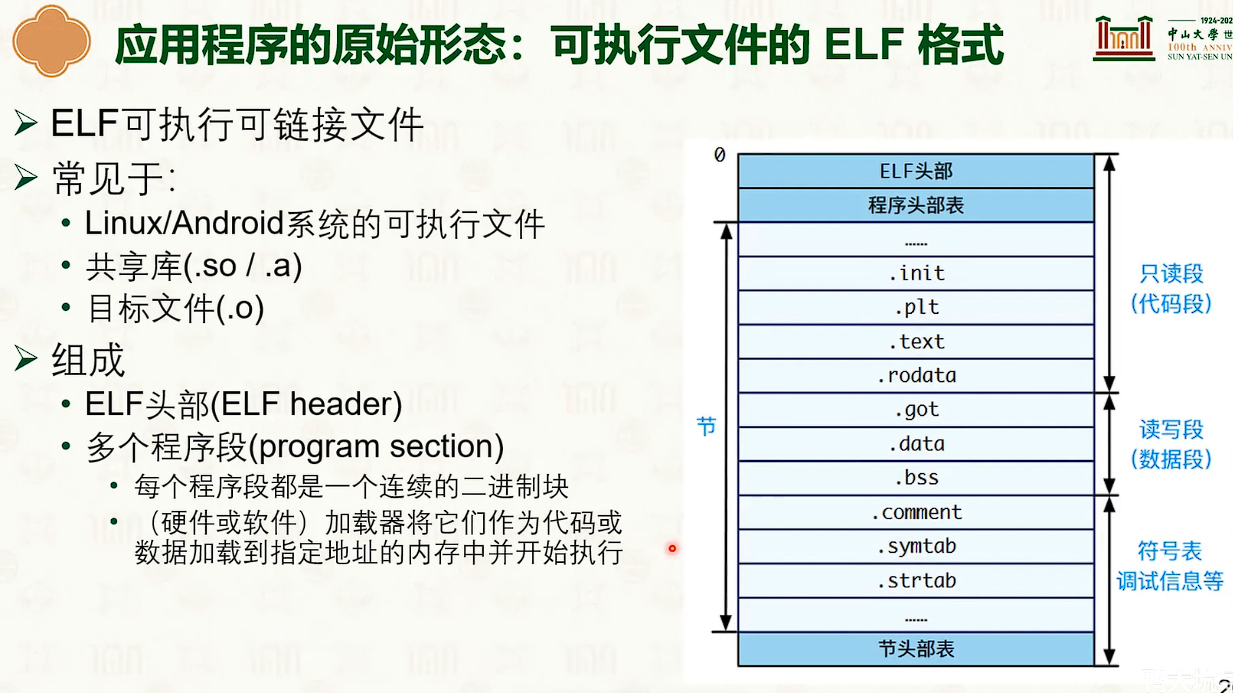
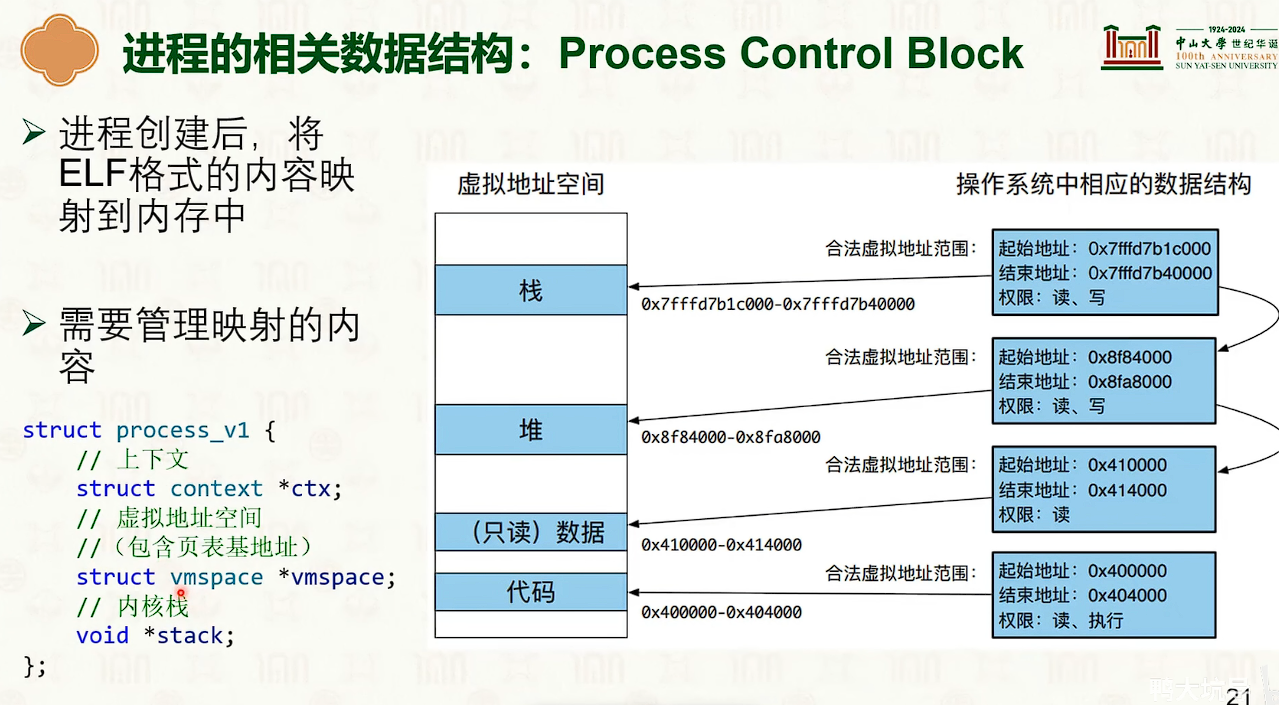
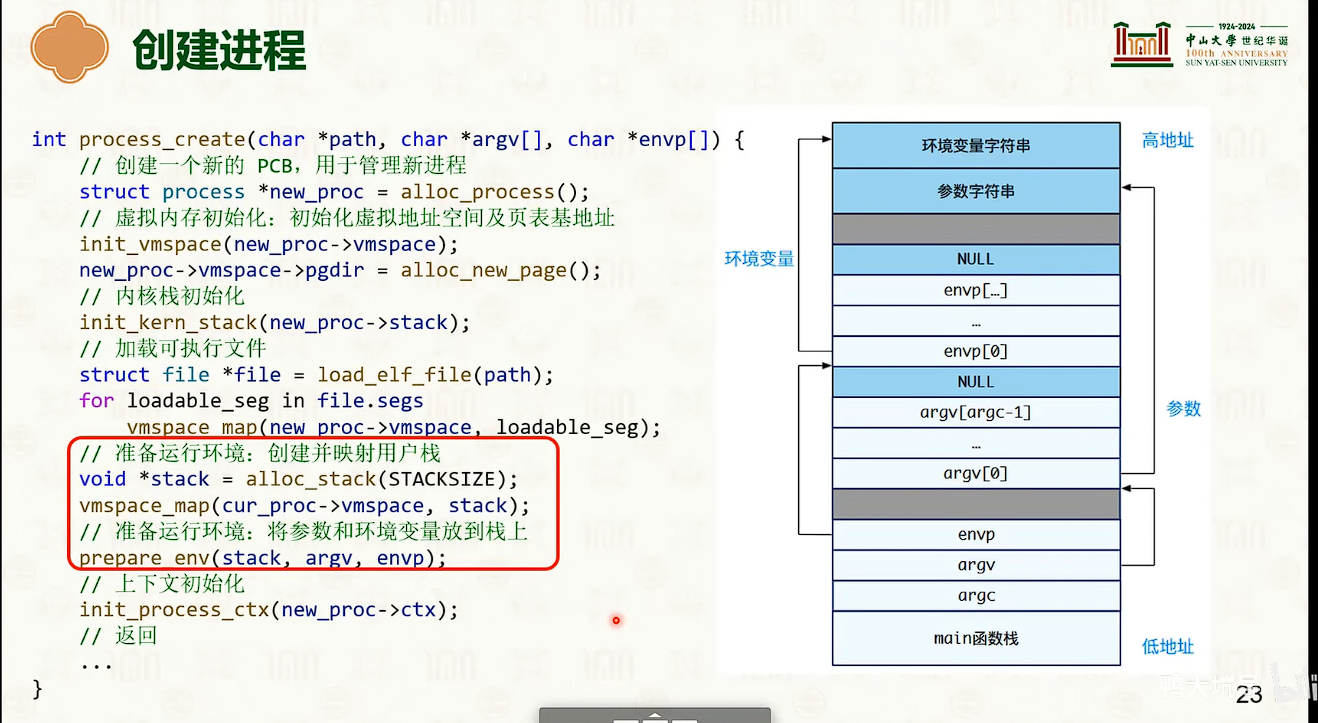

进程基本操作接口

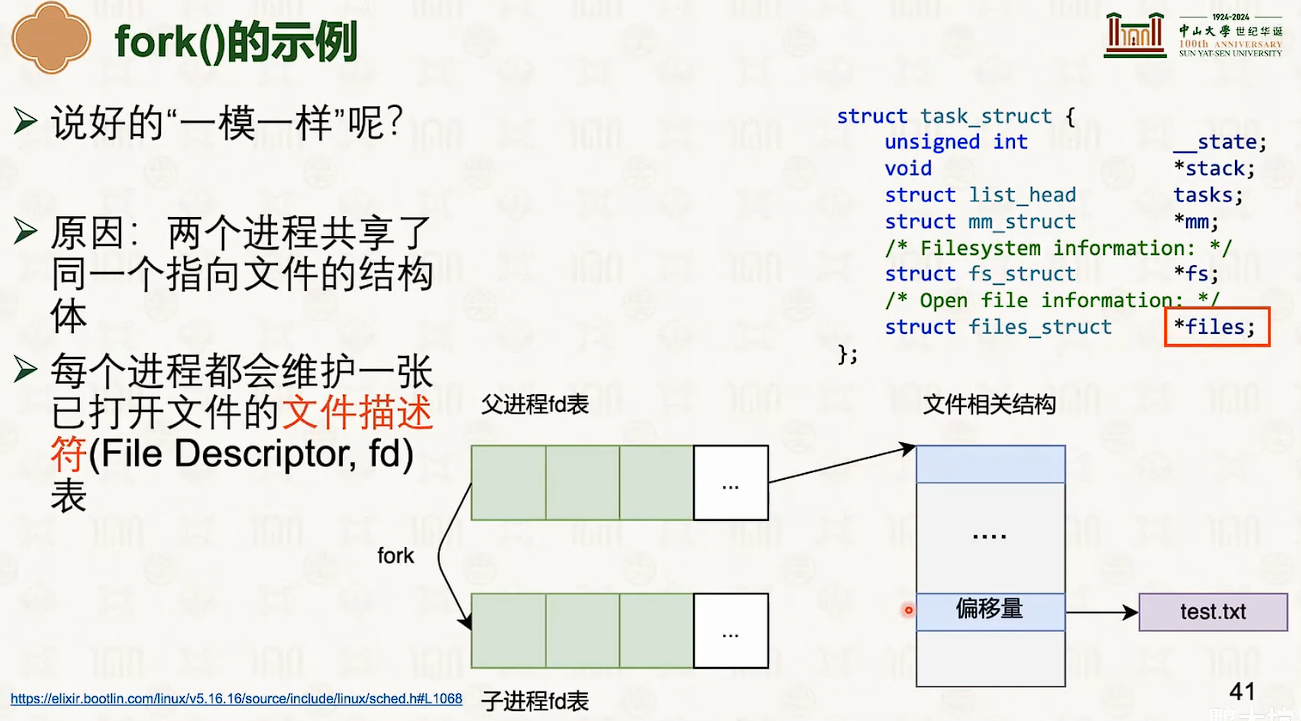

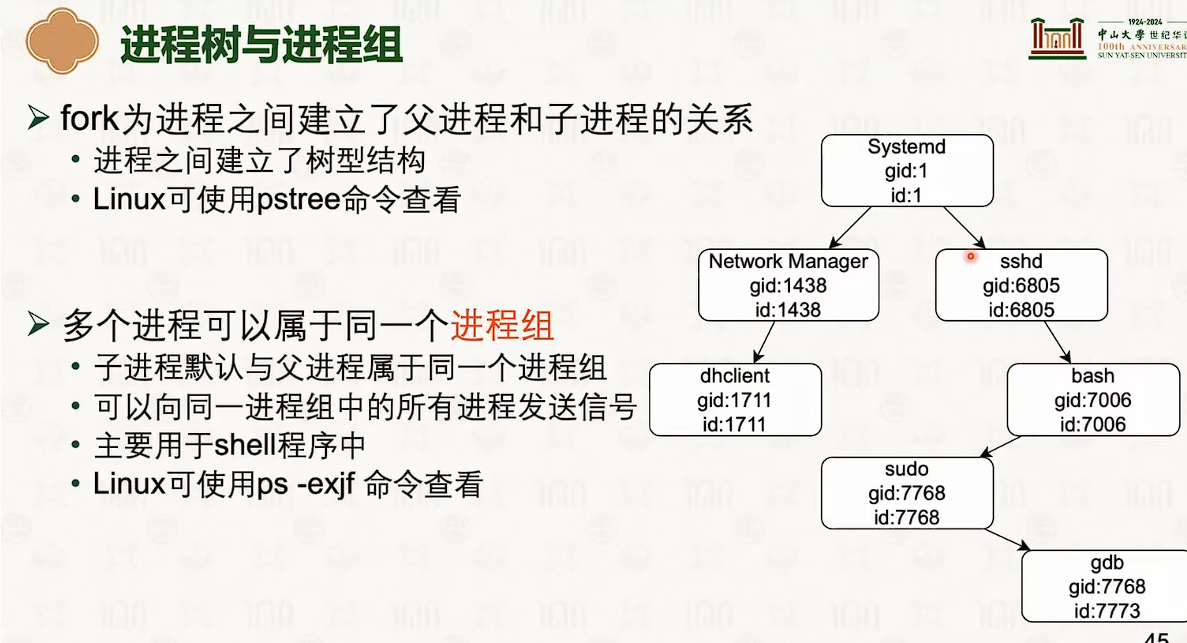

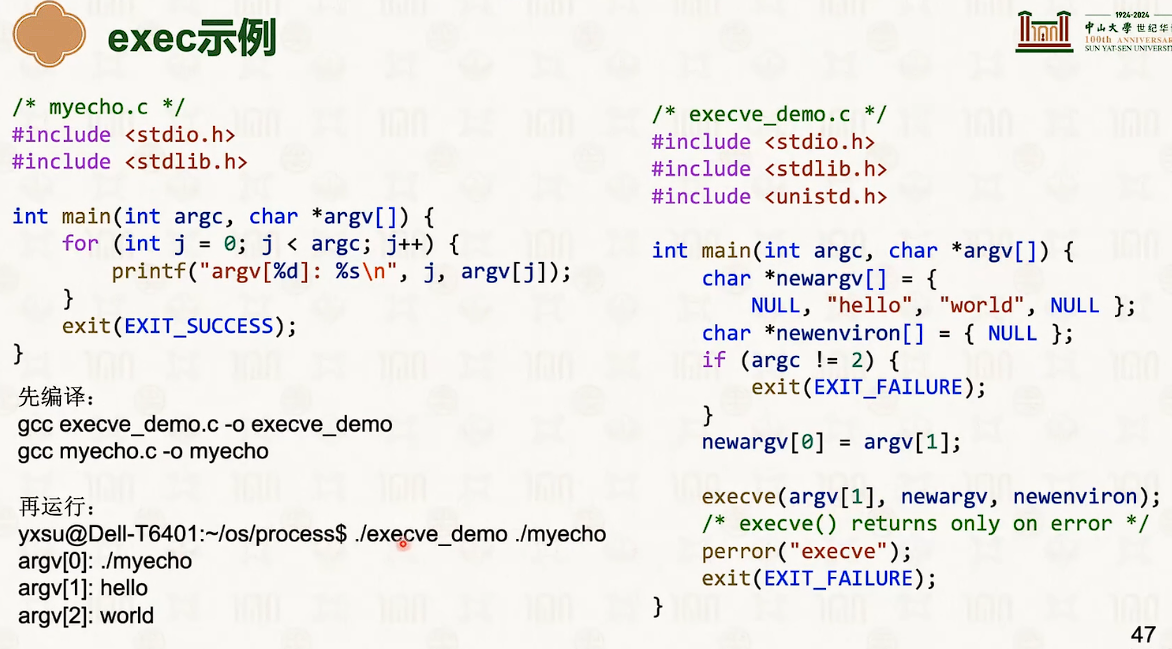


- 这个vfork有点像线程的创建,但是可能有点问题。
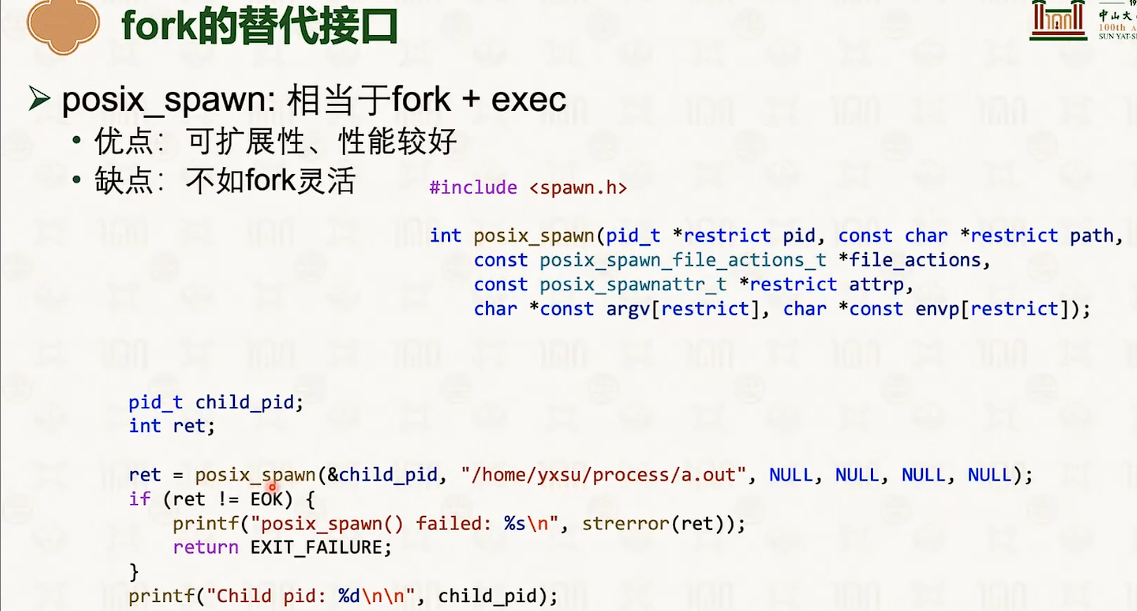

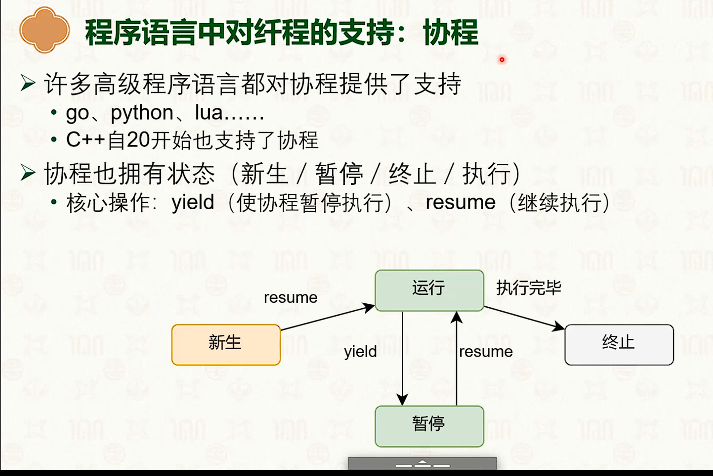
线程与协程
线程



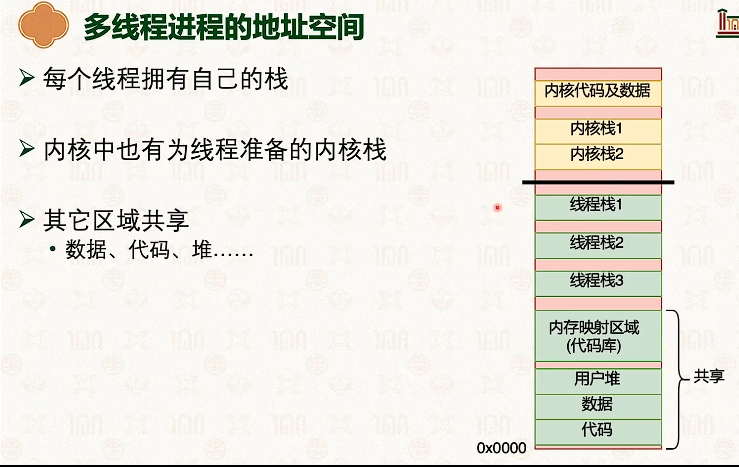
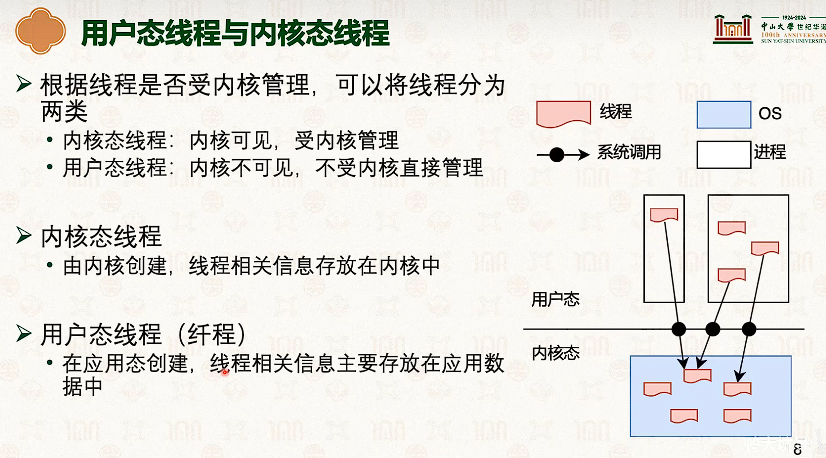
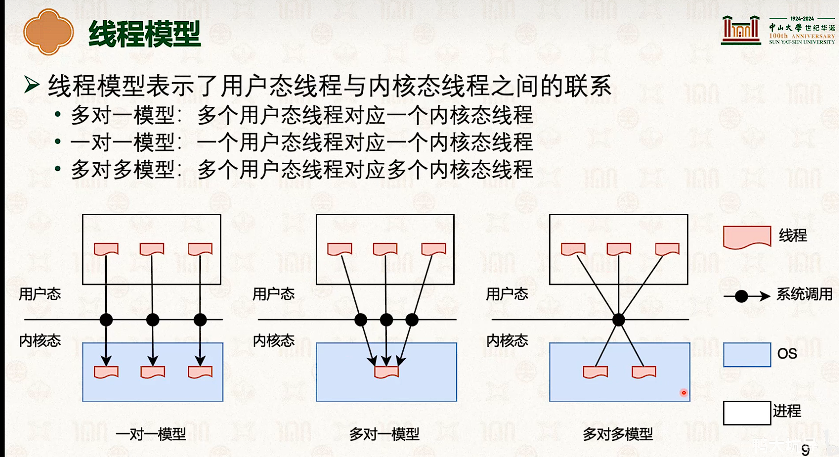
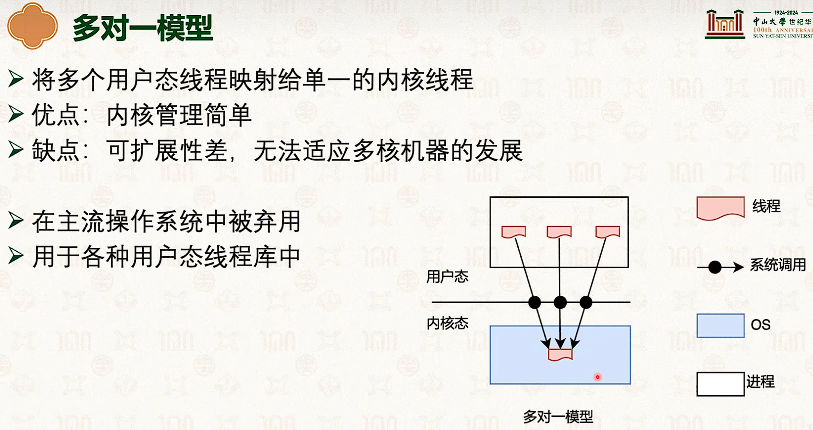
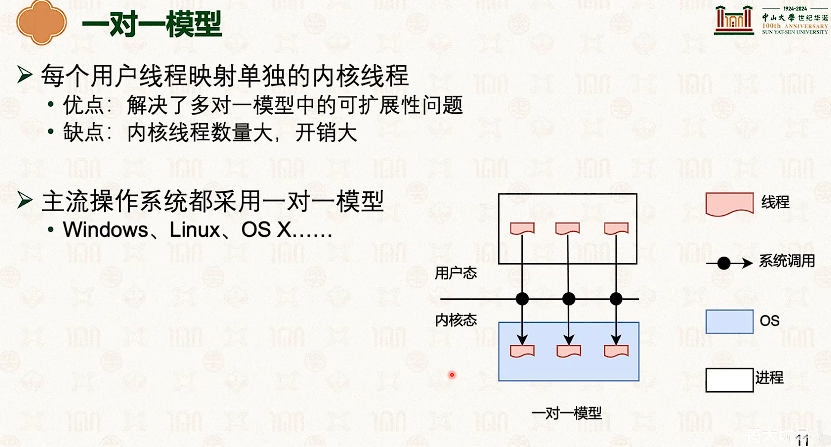
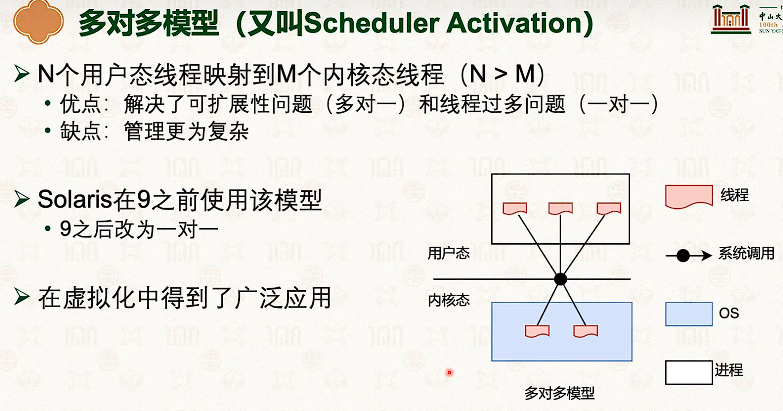



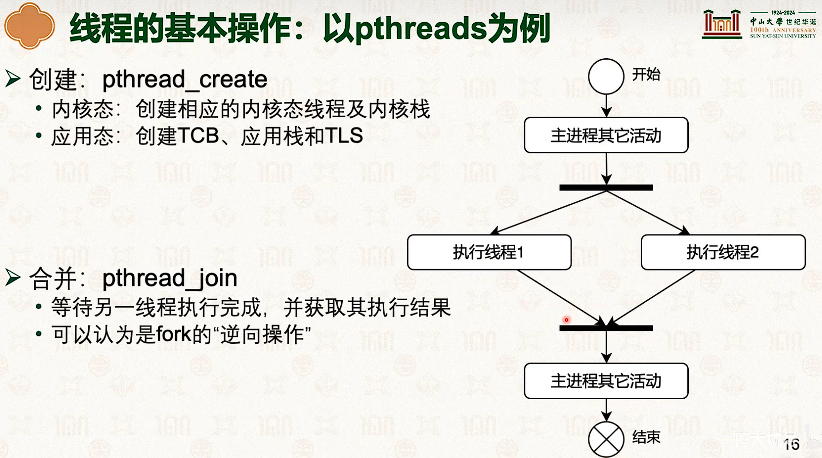




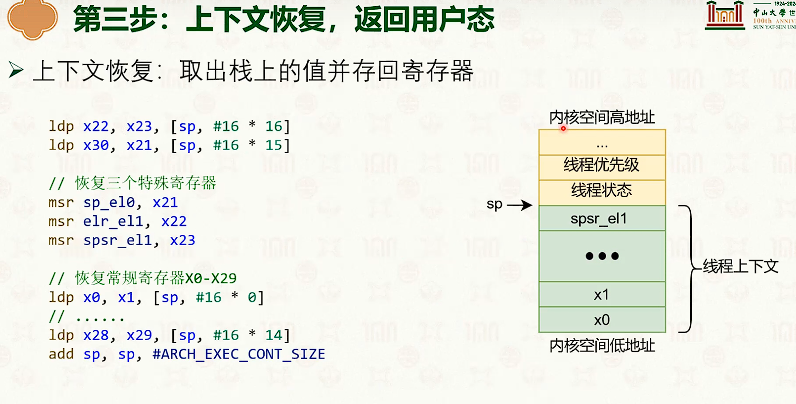

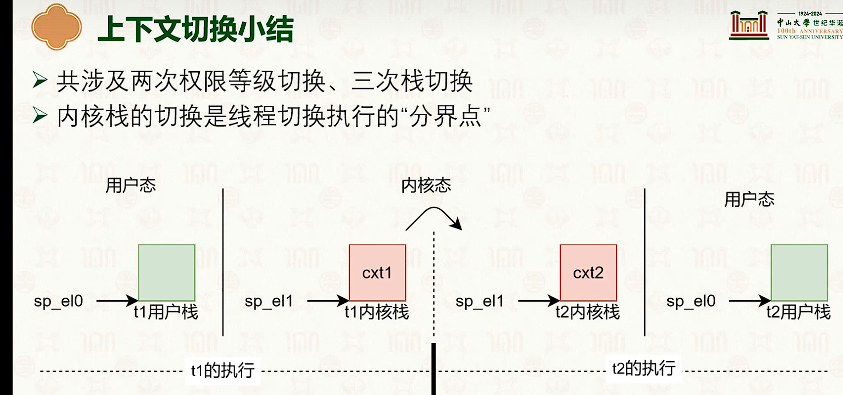
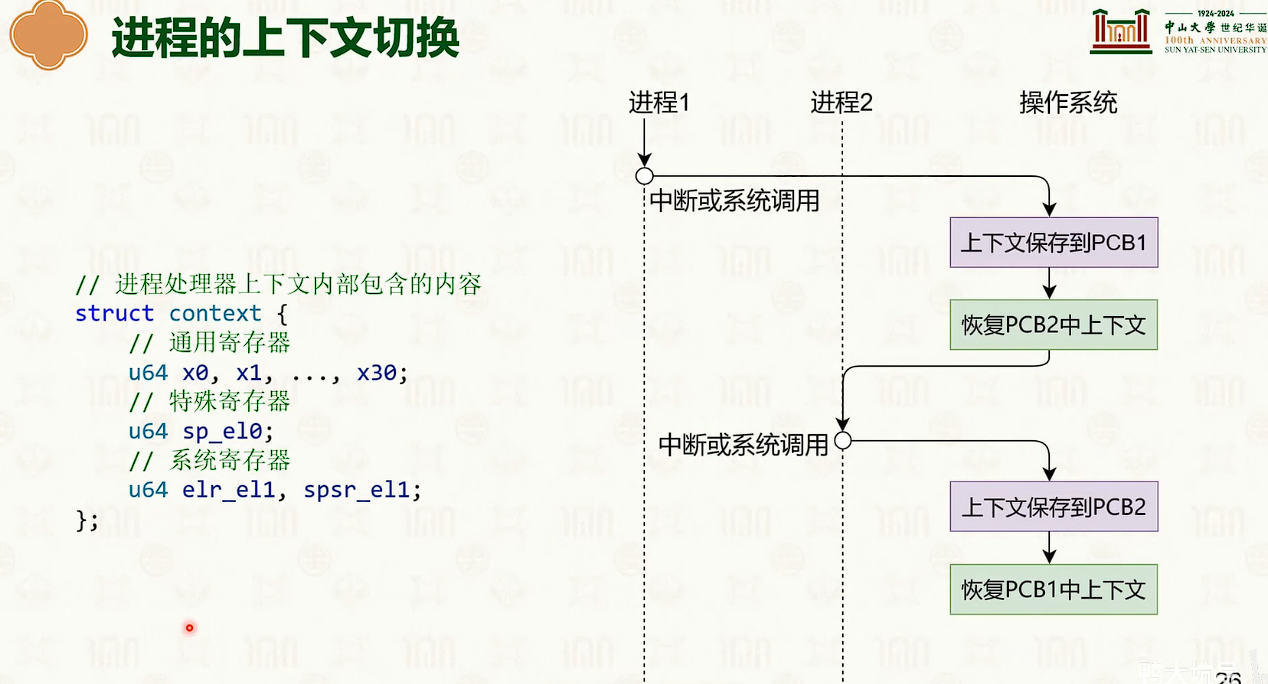
- 因为内核和线程也是一对一的,所以线程从t1切换到t2,需要内核栈也切换一次。
纤程(Fiber)、协程(Coroutine)




-
上面答案为C
-
纤程是用户的库函数,由POSIX实现,不是系统调用
-
setjmp 和 longjmp 也不是系统调用,是用户库函数。
-
区别:setjmp 和 longjmp 仅保存基本的执行上下文(程序计数器,栈指针),而纤程函数可以保存更完整的上下文(信号掩码,浮点数寄存器),支持更复杂的协程切换。

处理器调度:单核调度策略




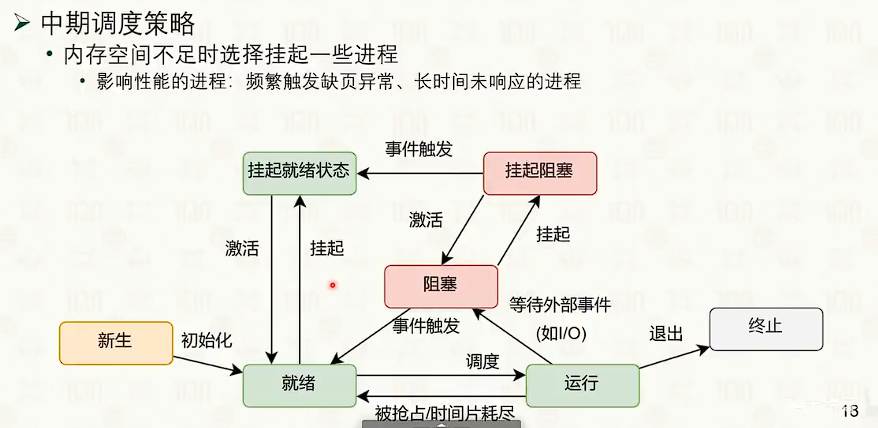
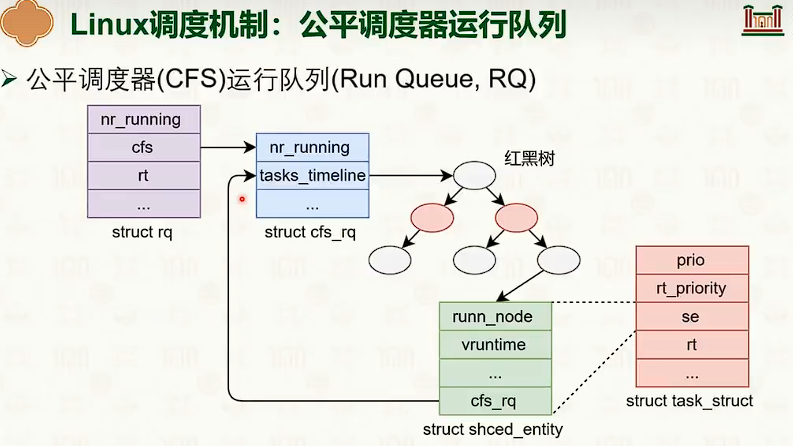
单核调度策略
经典调度策略
- 先到先得(First Come First Served)
- 优点:简单、直观
- 缺点:队头阻塞,IO密集型任务不友好(因为频繁IO导致被挂起)。
- 最短任务有限(Shortest Job First)
- 优点:单位时间内任务吞吐量大、平均周转时间短。
- 缺点:不公平、平均响应时间长、大任务饿死。
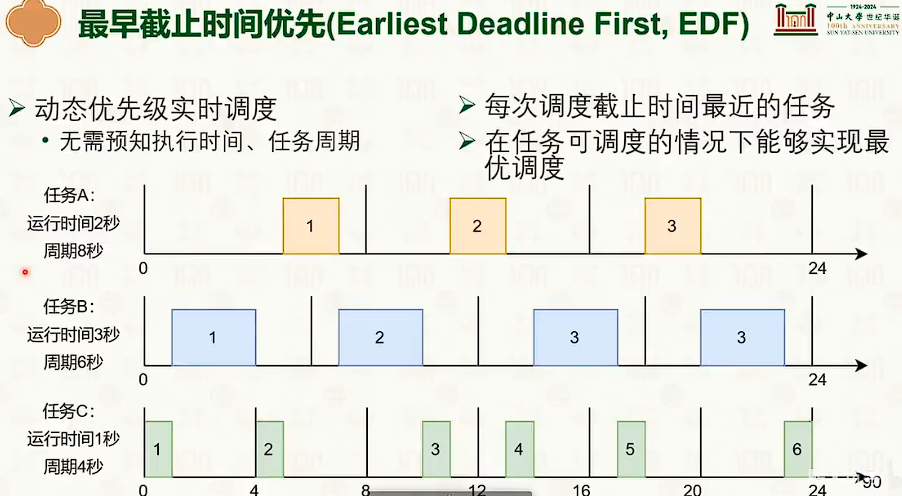
- 抢占式调度(Preemptive Scheduling)
- 非抢占式调度:前面一个任务完整之后再执行下一个。
- 抢占式调度:执行一段时间之后,切换到下一个任务。而非执行至中指,通过定时触发时钟中断实现。如:最短完成时间任务优先。
- 最短完成时间任务优先:
- 优点:平均周转时间短、
- 缺点:会打断正在运行的任务;可能不可得知完成时间。
- 时间片轮转(Round Robin)
- 优点:响应时间短、公平
- 缺点:牺牲周转时间、平均响应时间短
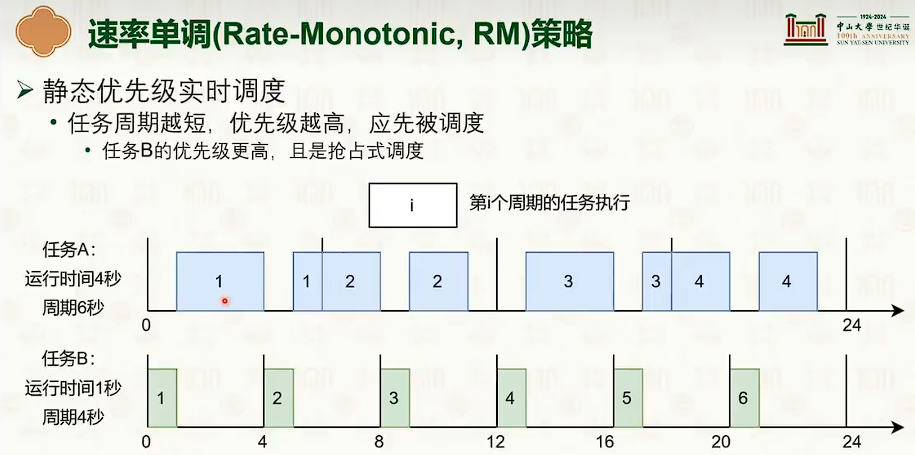
优先级调度
-
操作系统中任务分三六九等。
- 系统VS用户、前台VS后台
- 保证重要的任务被优先调度
-
不同的调度策略隐藏对应的优先级确定方式

-
优先级是会变化的。可以是动态的。
-
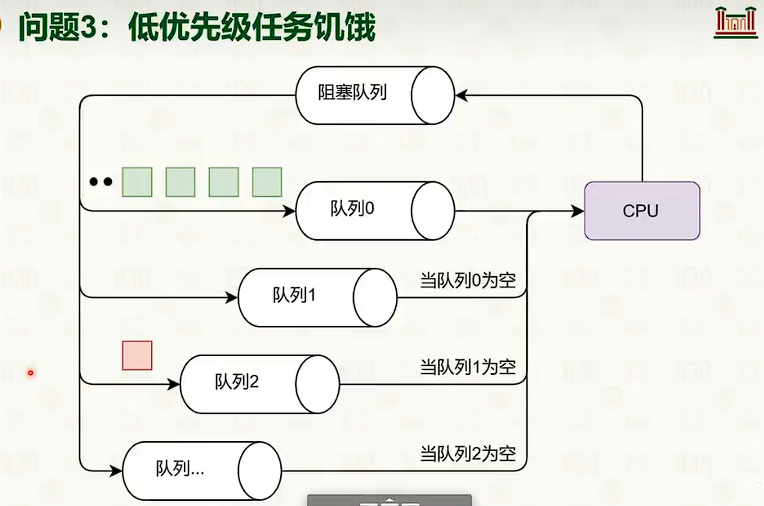
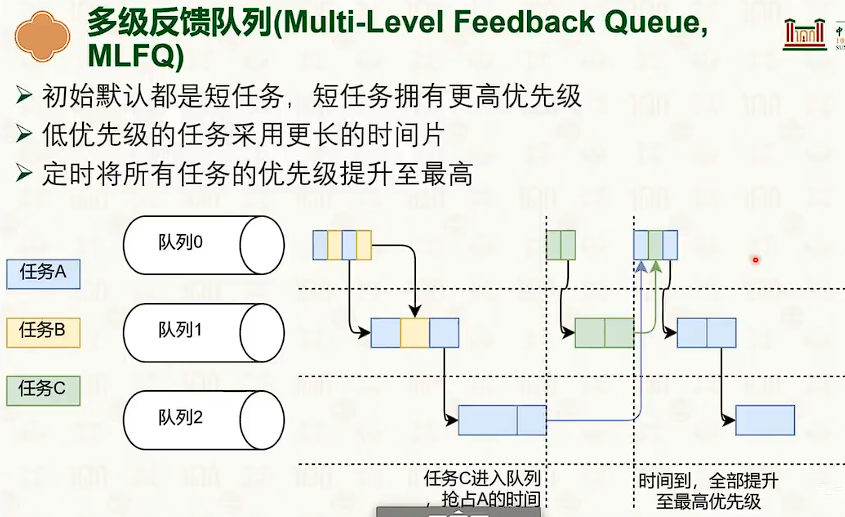
维护多个优先级队列,高优先级的任务优先执行。同等优先级使用时间片轮转。
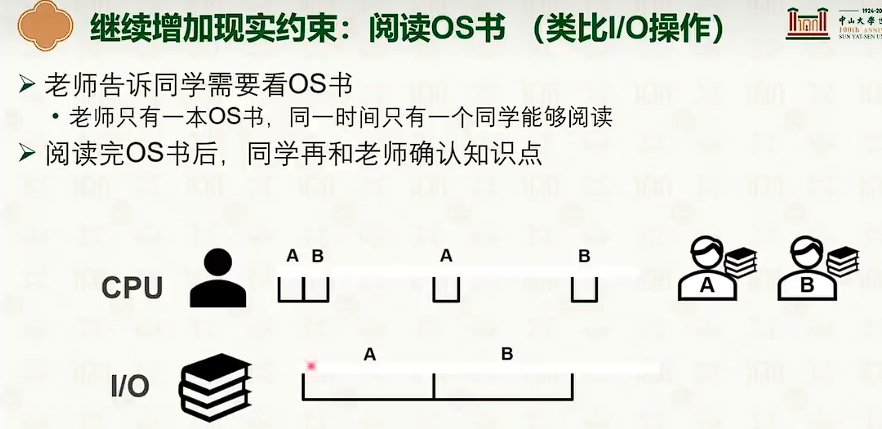


- 保证优先级?保证高资源利用率?
公平共享调度
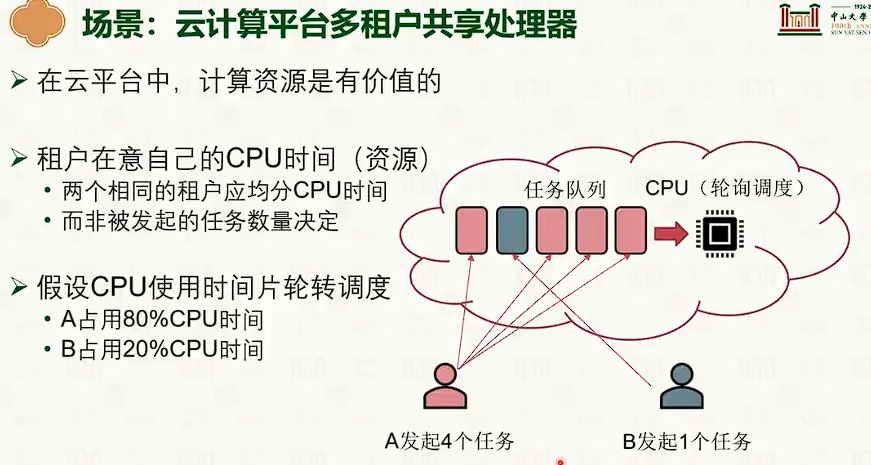

- 但是场景是多用户的,每个用户有若干任务。
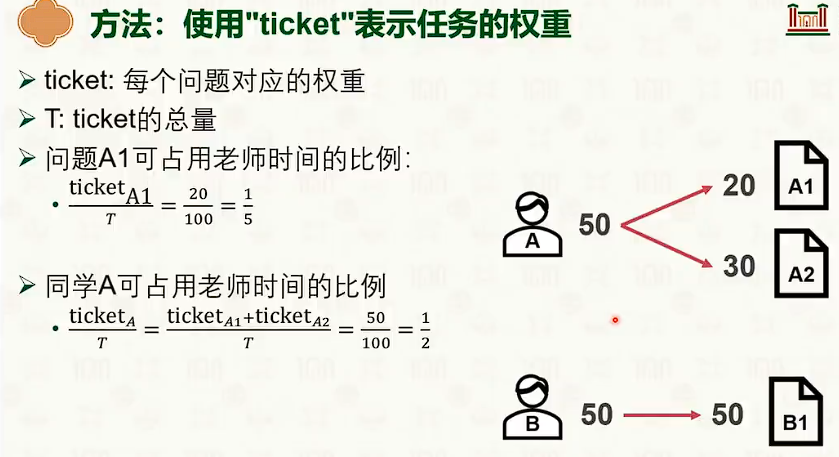

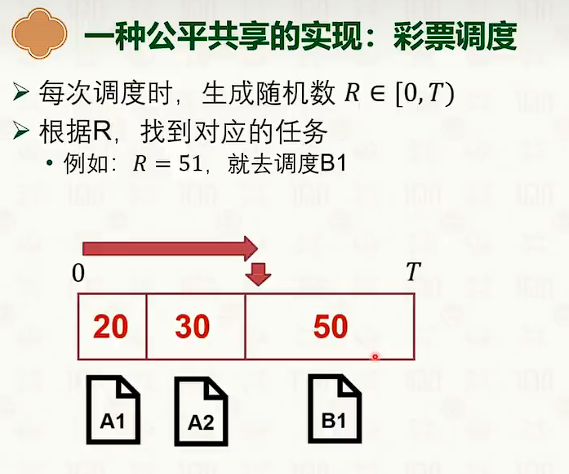



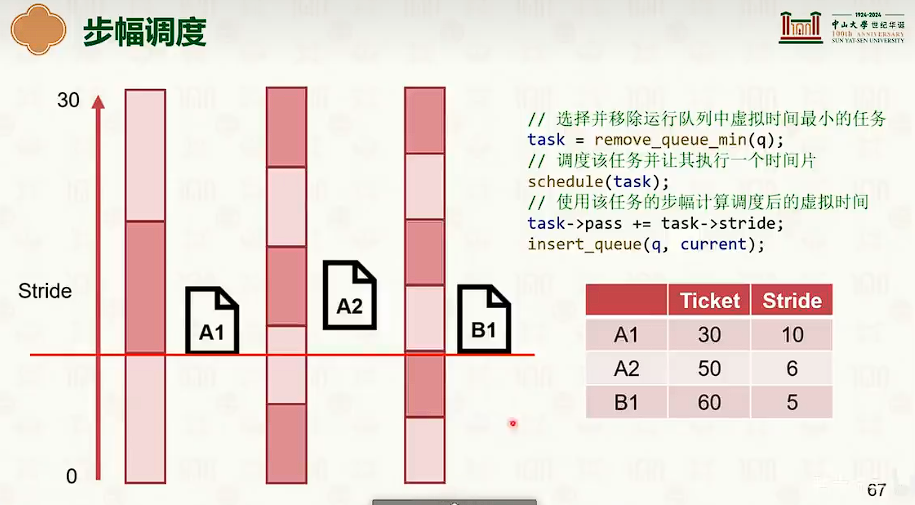

- 步幅调度的优点比起随机更加实际,更加接近比例。
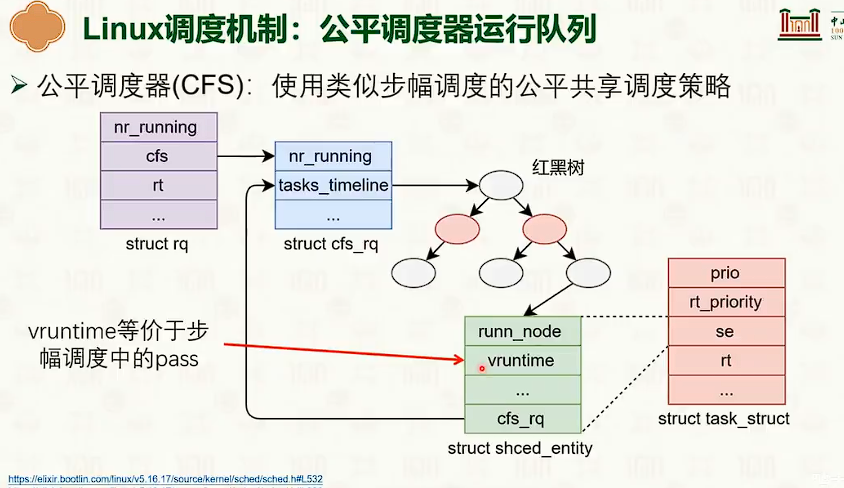
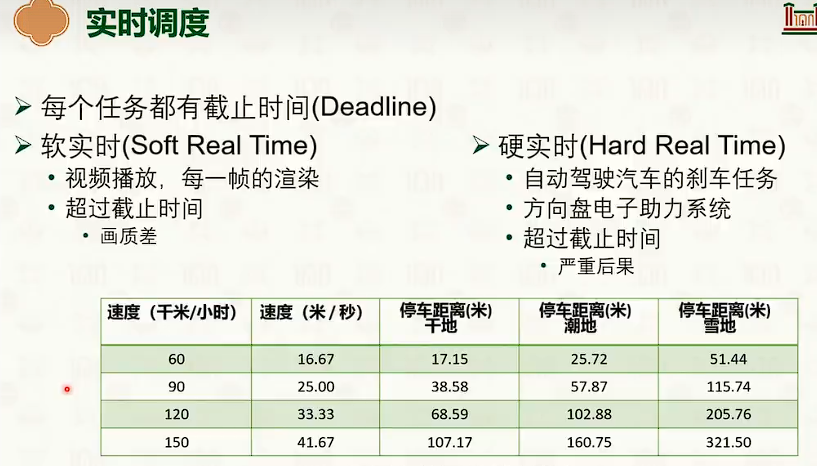
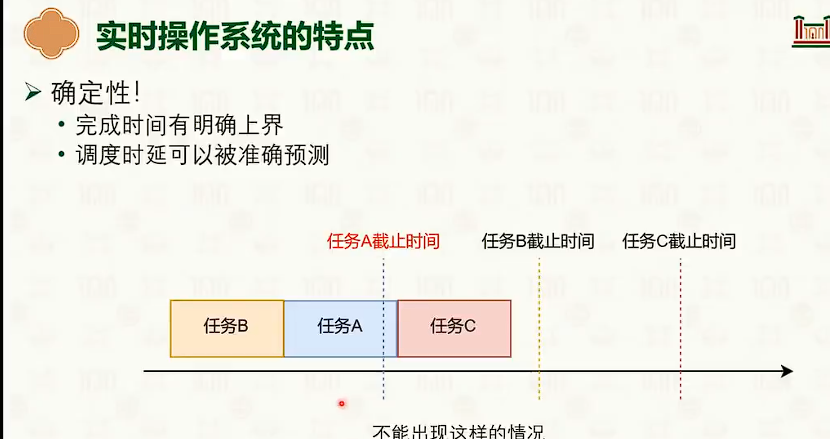
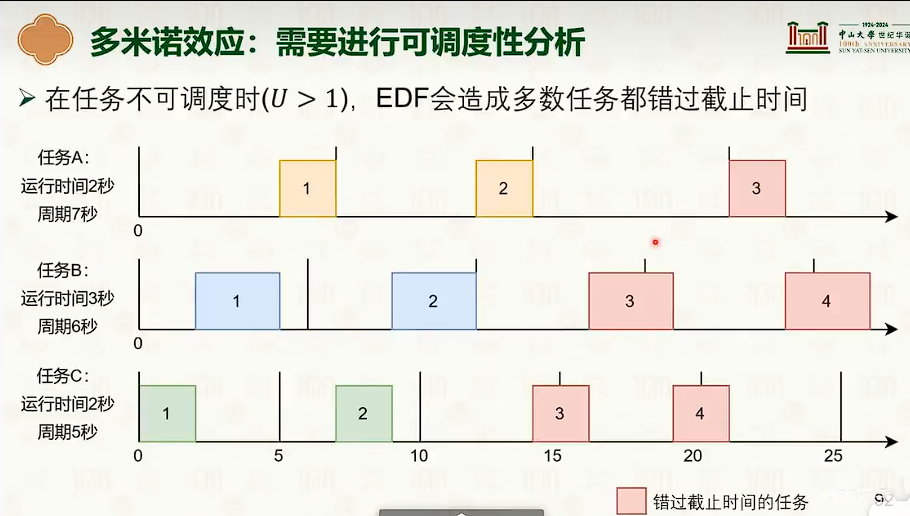
处理器调度:多核调度策略
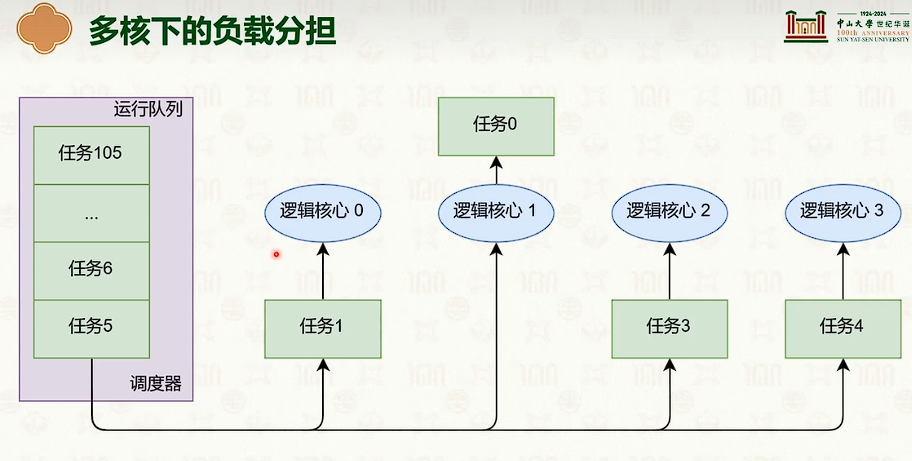

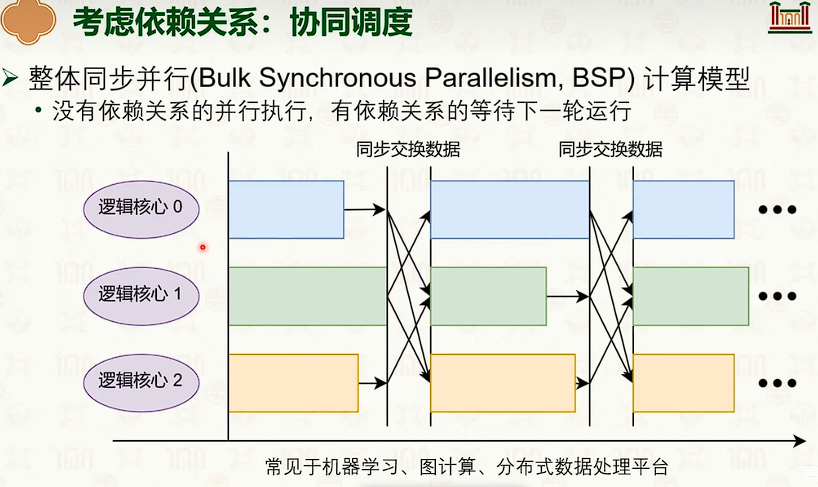

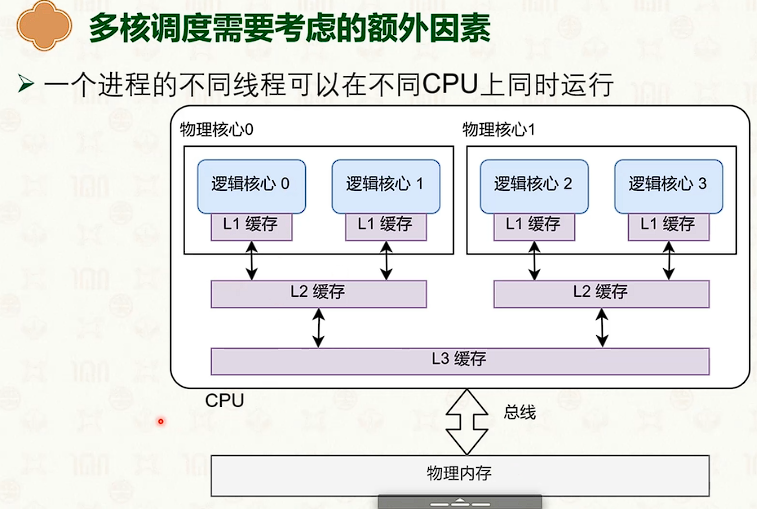
- 如果在不同CPU上,会出现缓冲失效。
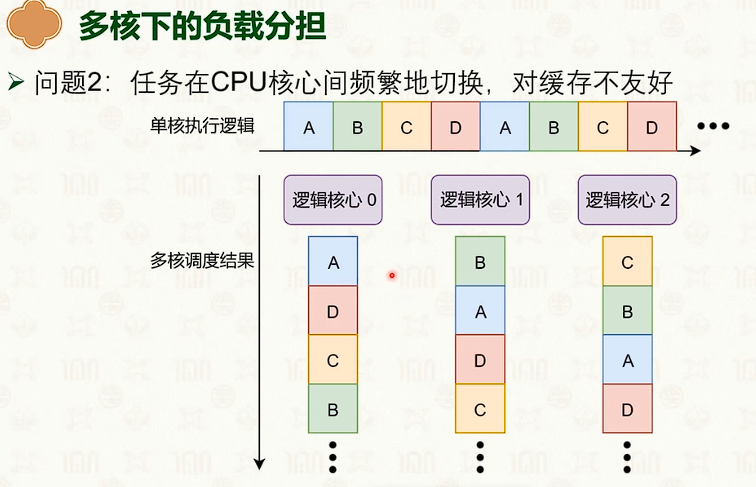
- 问题:任务之间有关联,频繁切换对缓存不友好
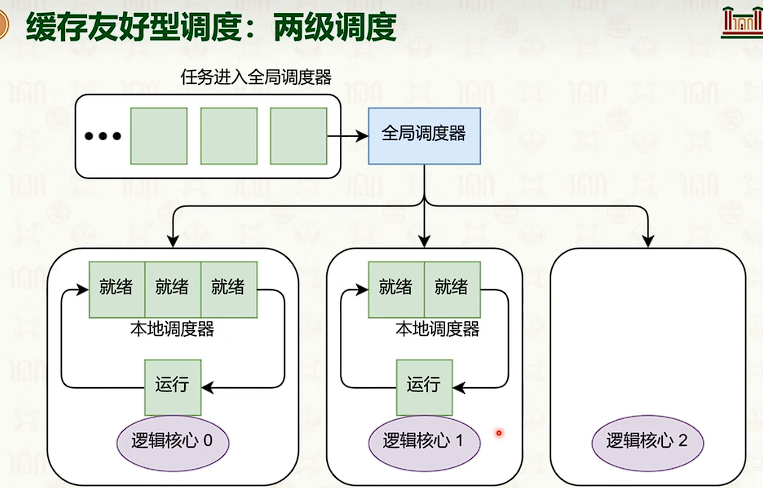
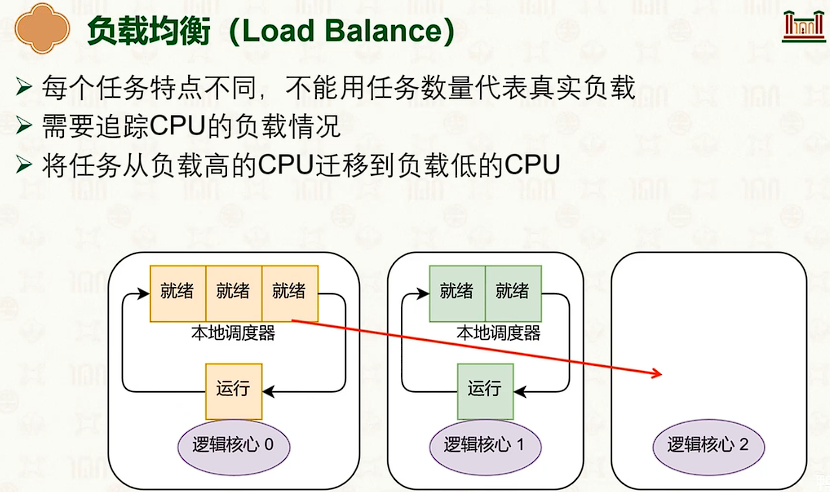
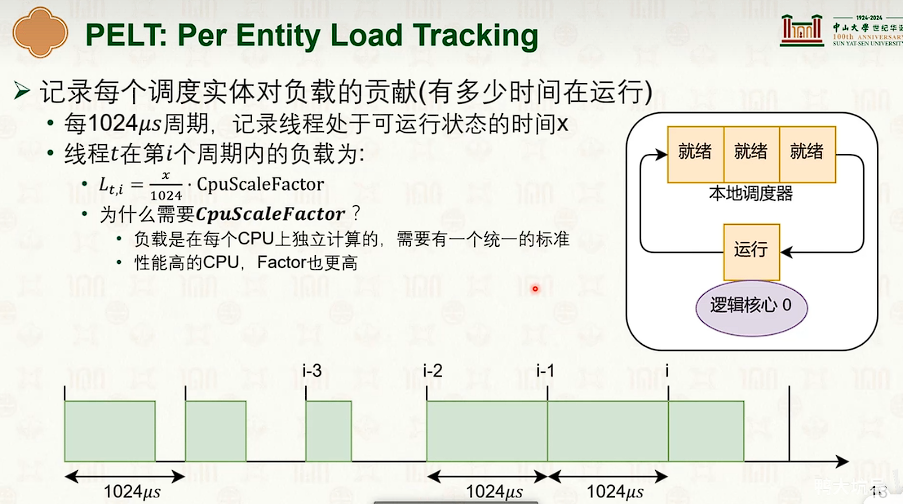
- 但两级调度问题是容易负载不均衡。


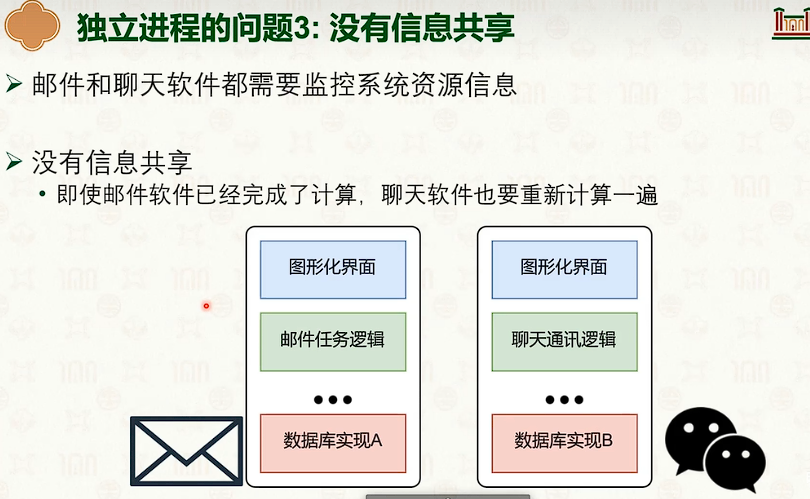
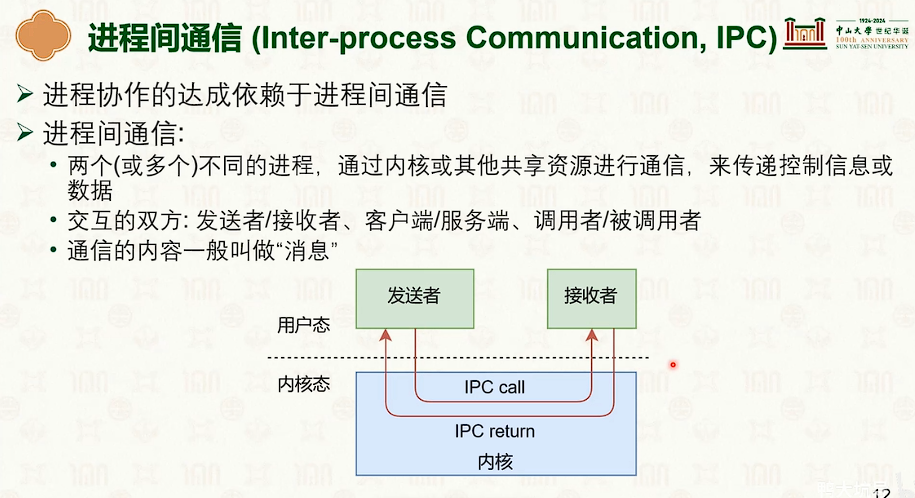
进程间通信(IPC)

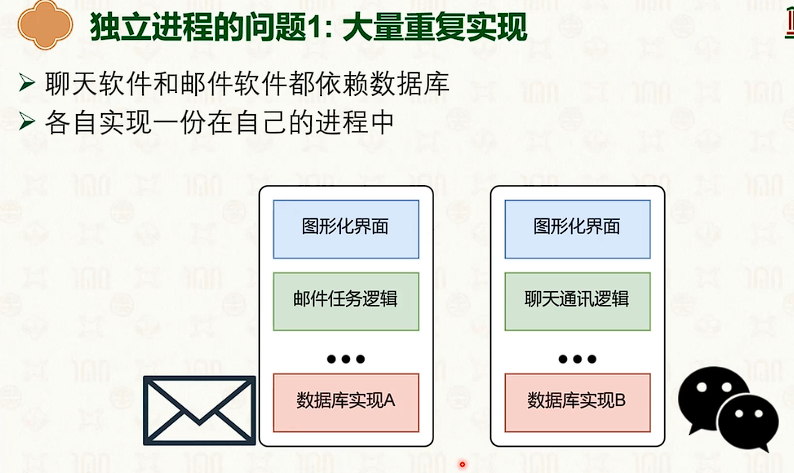

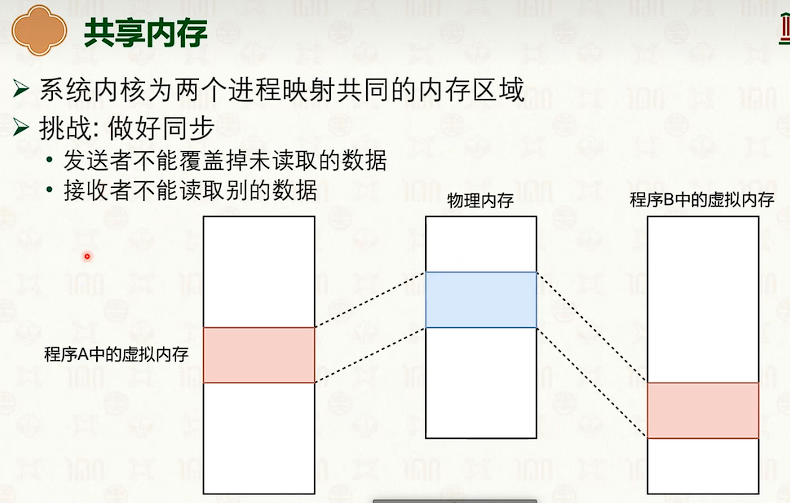
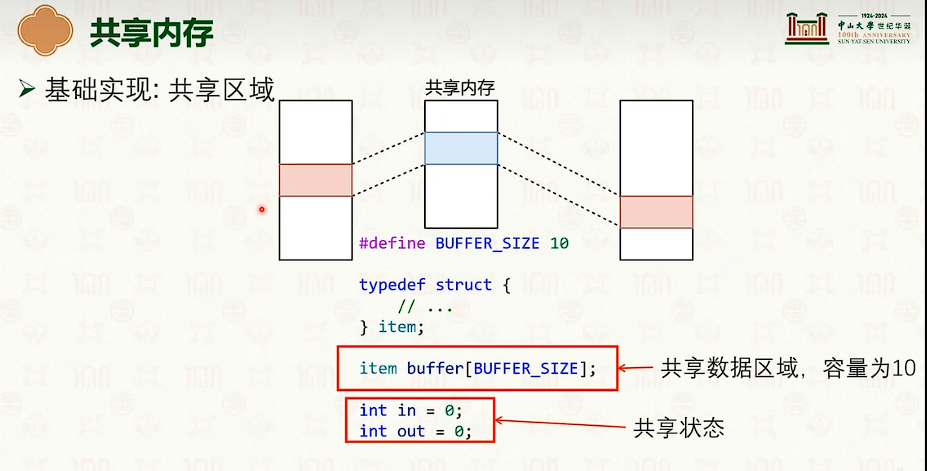
共享内存通信
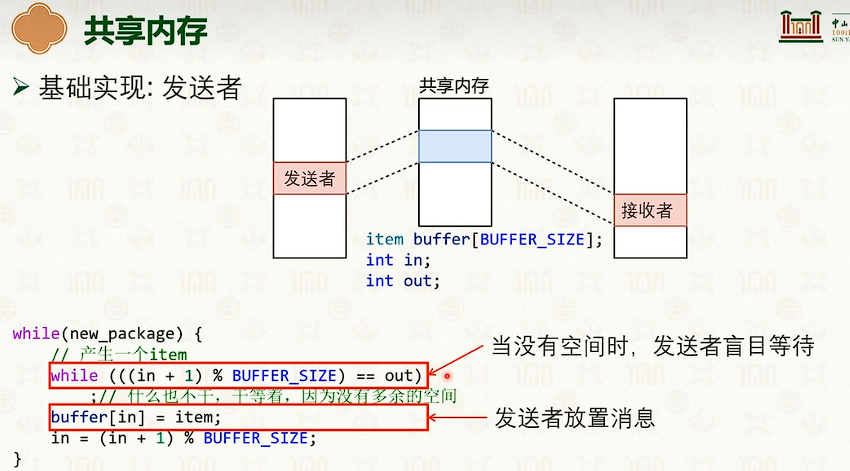
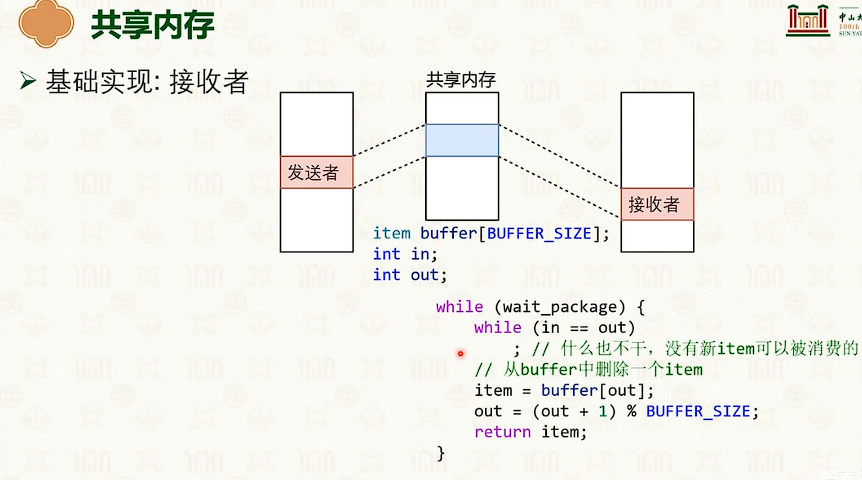
消息传递




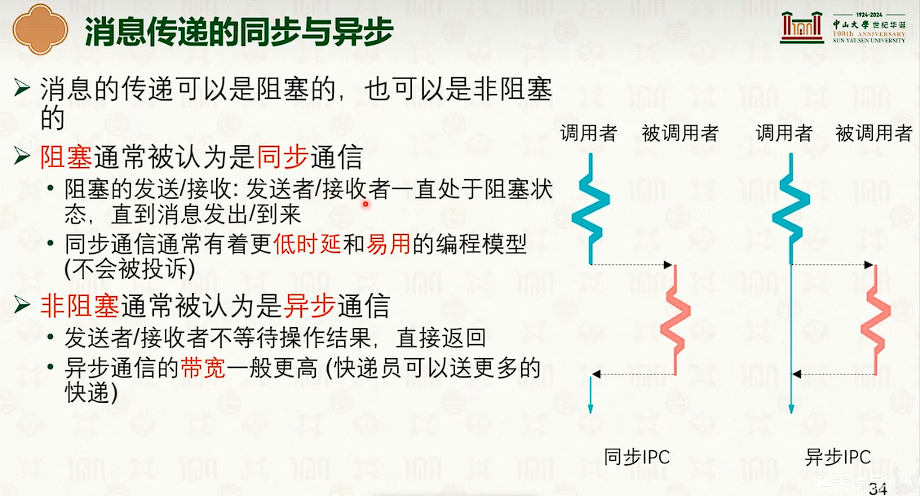
- 同步异步的折中:超时机制,如果超时了,那么就走。
- 先同步后异步。

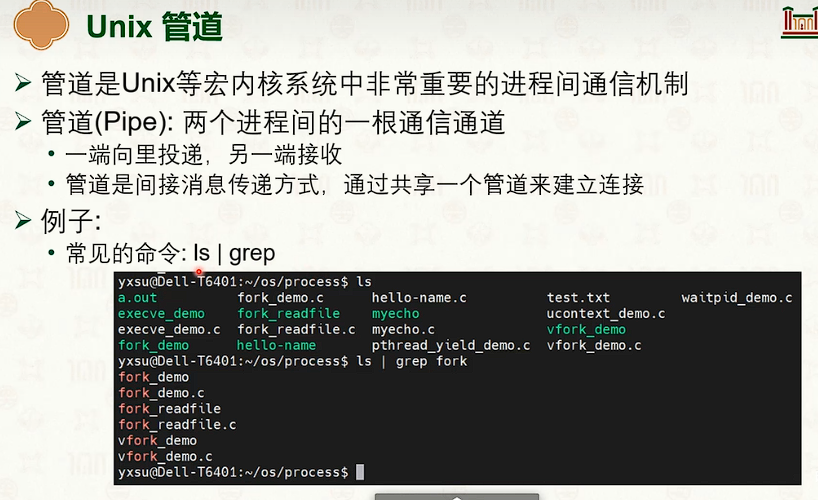
管道
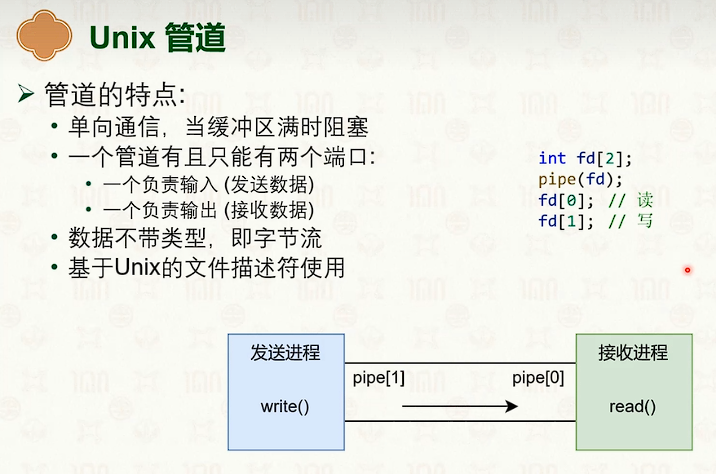

消息队列
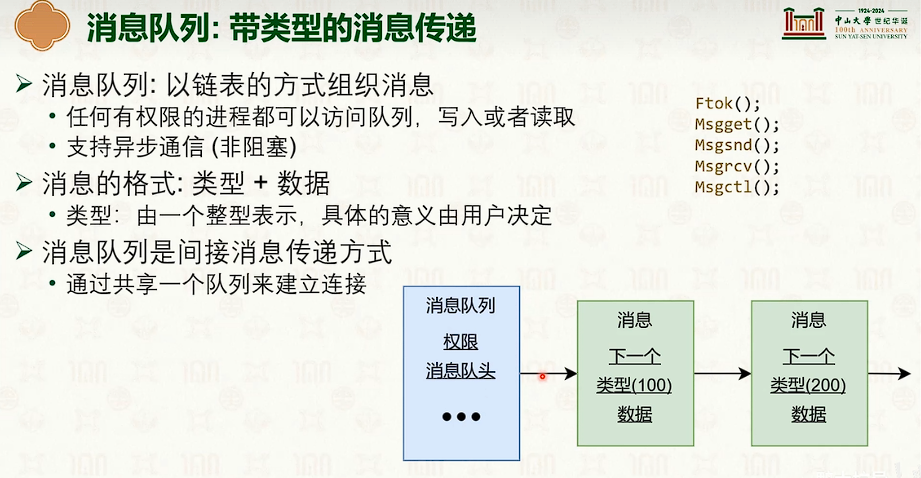



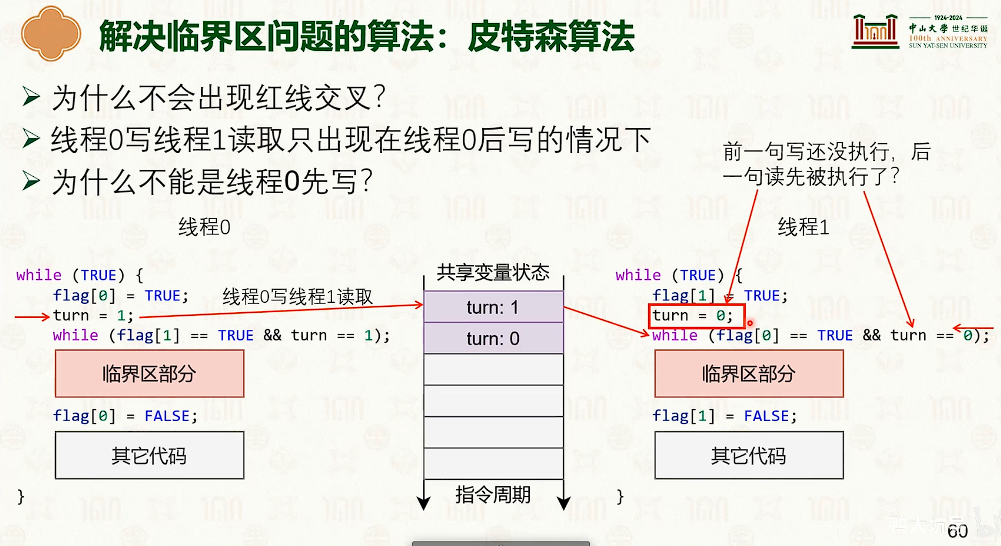
同步原语:互斥锁


- 硬件无法处理。
解决数据竞争:
- 申请标记
- 有限处理
- 标记消除
互斥锁

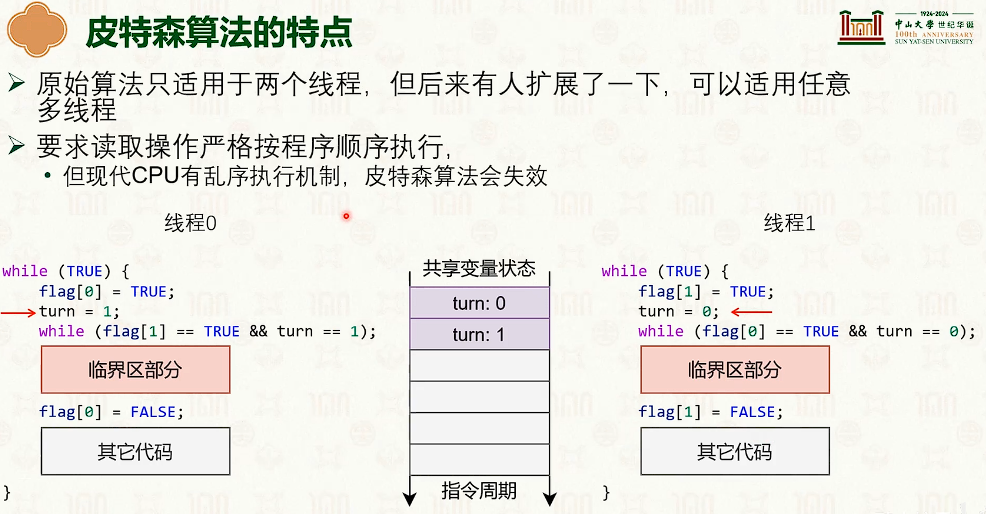
原子操作
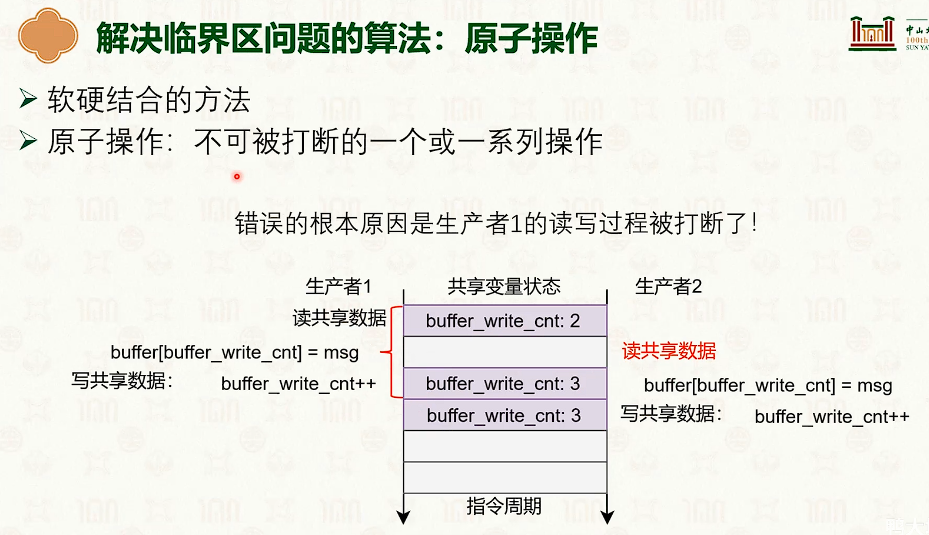
- 这需要硬件支持

- 能软件就软件,软件解决不了就硬件解决


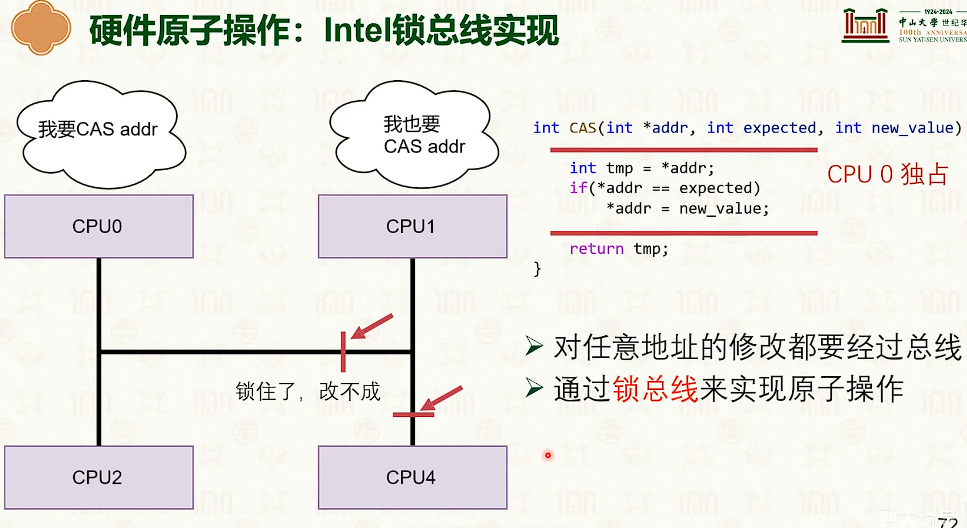
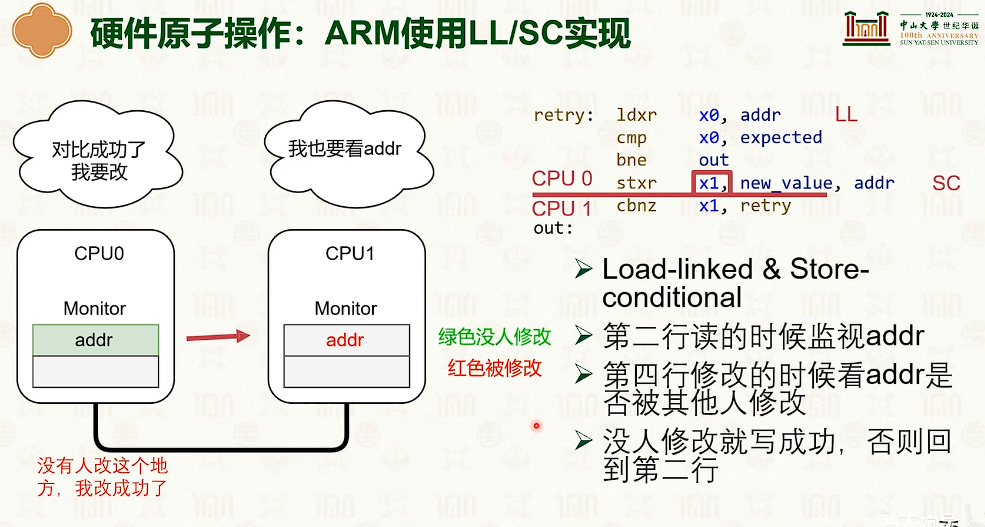
互斥锁抽象


简单优化:排号自旋。
同步原语:条件变量与读写锁

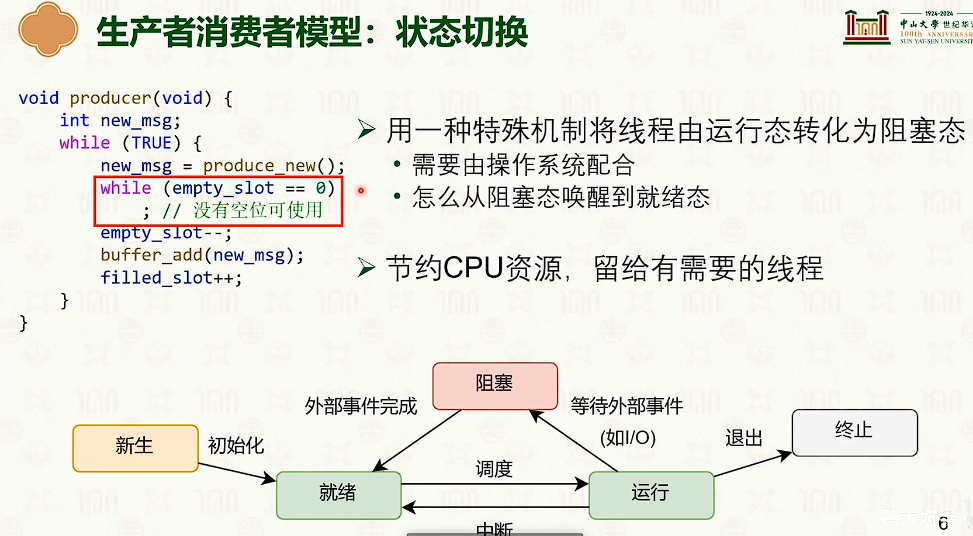
- C++ STL 中没有自旋锁,std::mutex 和 std::shared_mutex 都是睡眠唤醒模型的互斥锁。
- 但是C++ STL提供了 std::atomic 可以提供 test_and_set() clear() 还有 load(), store() 来自己实现自旋锁。
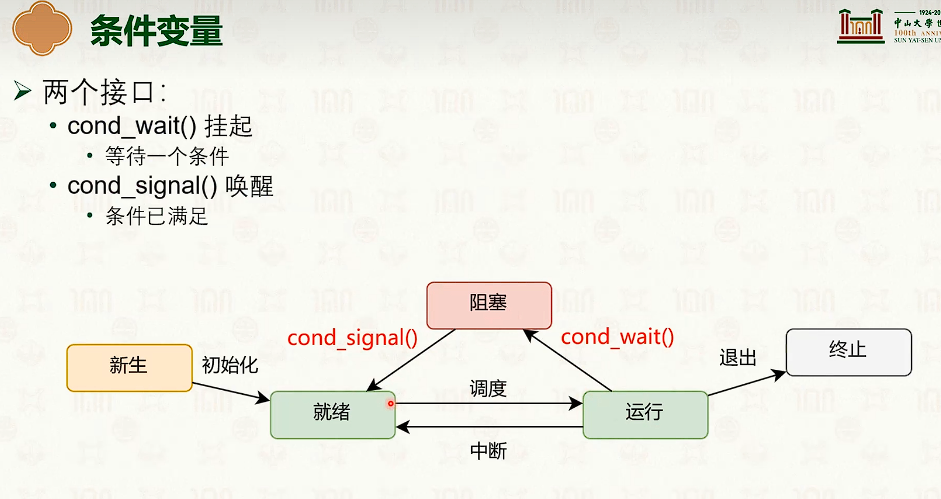
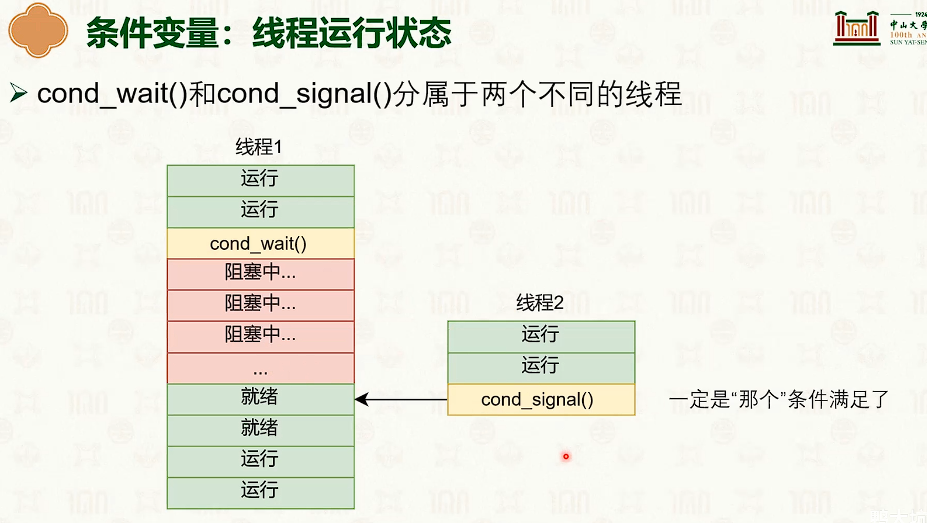

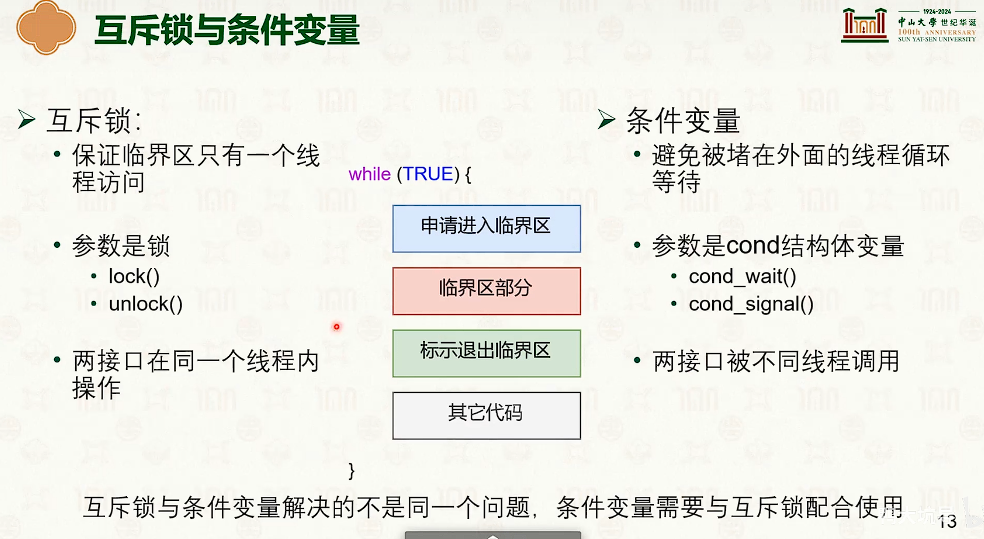



读写锁
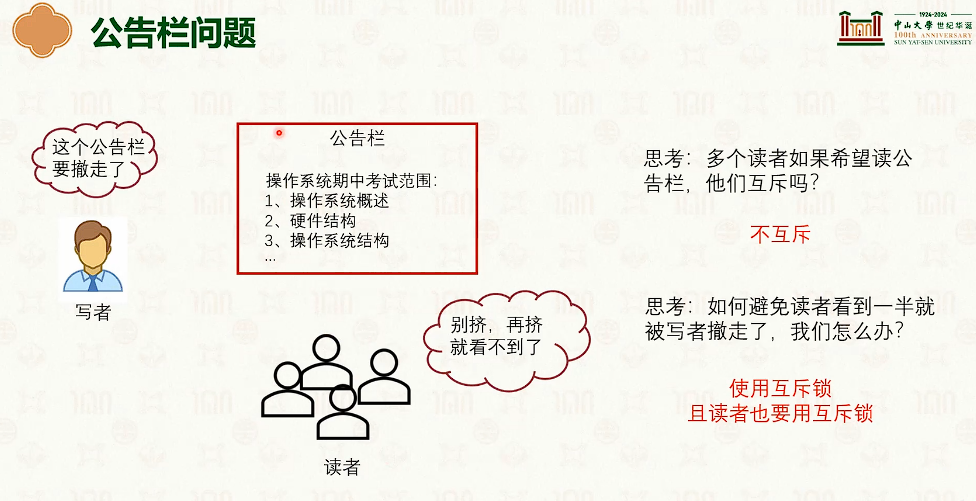
- 偏向读者:只要能读就让读者读,并发高,但是写者可能饿死。
C++中的std::shared_mutex的实现是基于一个 std::mutex 和 两个条件变量,条件变量用于写者等待和读者等待。
同步原语:死锁问题

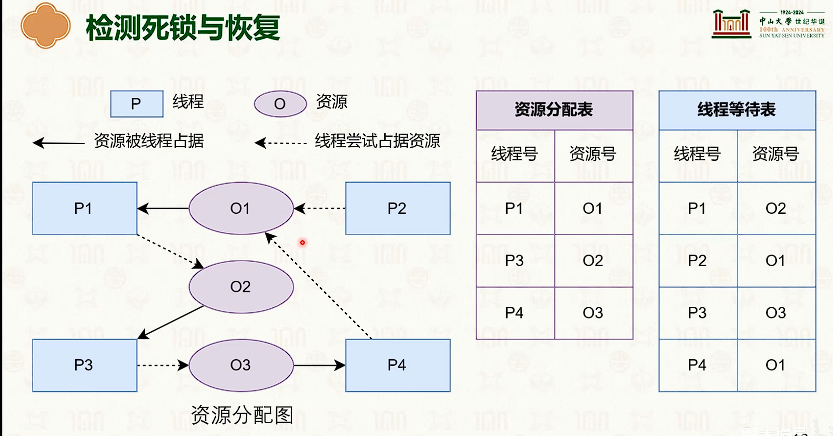

- 但是对于一个程序,不存在程序内的死锁,只存在因外部输入而导致的死锁应该是必须的吧。
- 数据库怎么可能也怎么可以存在因自身代码导致死锁。


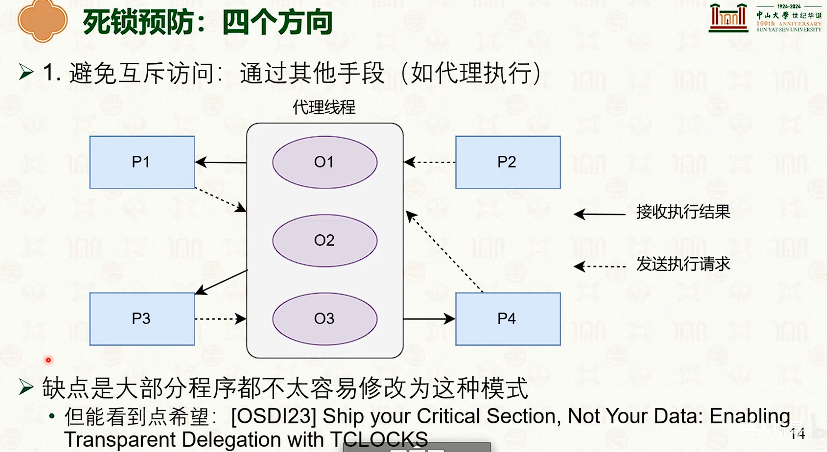
运行时死锁:死锁避免
银行家算法:
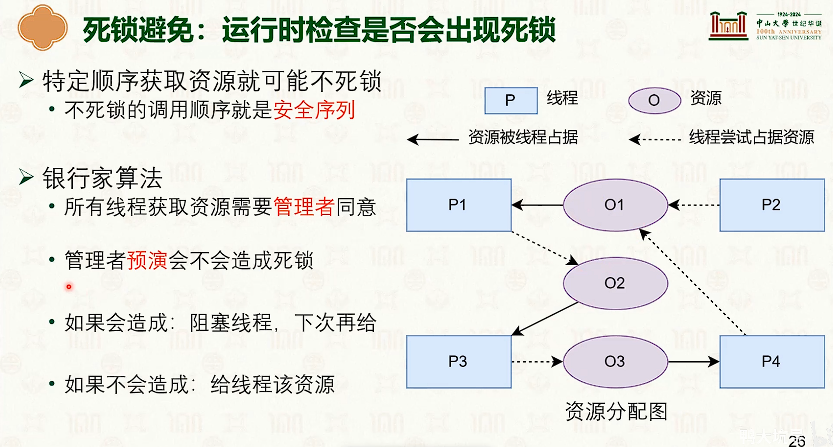
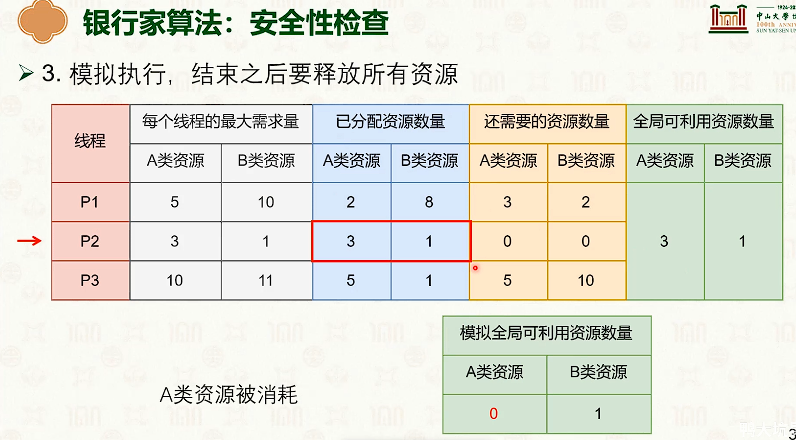
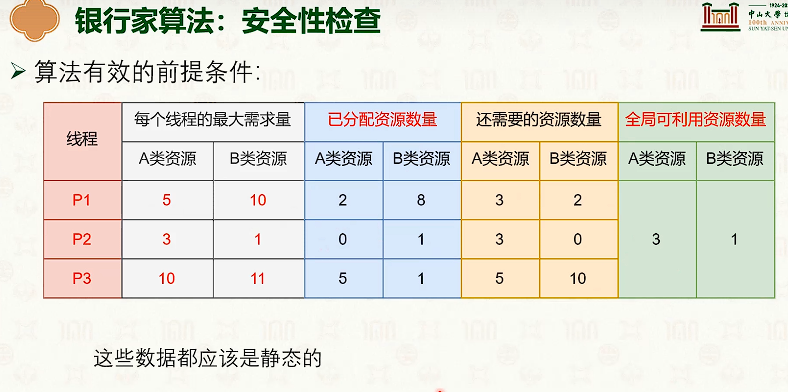
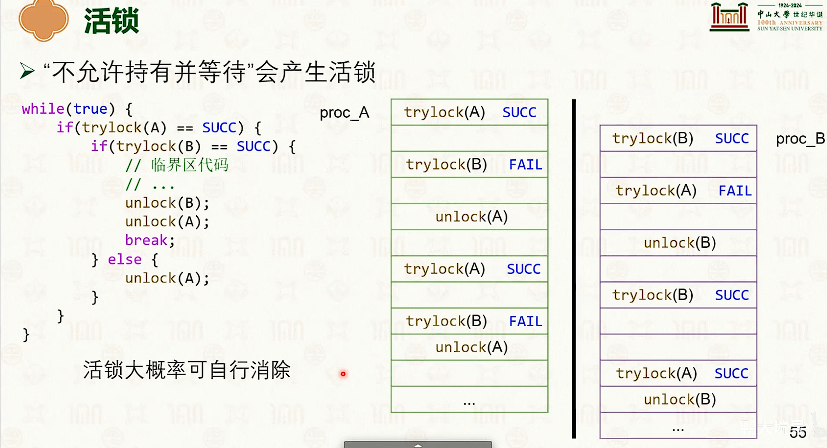
活锁
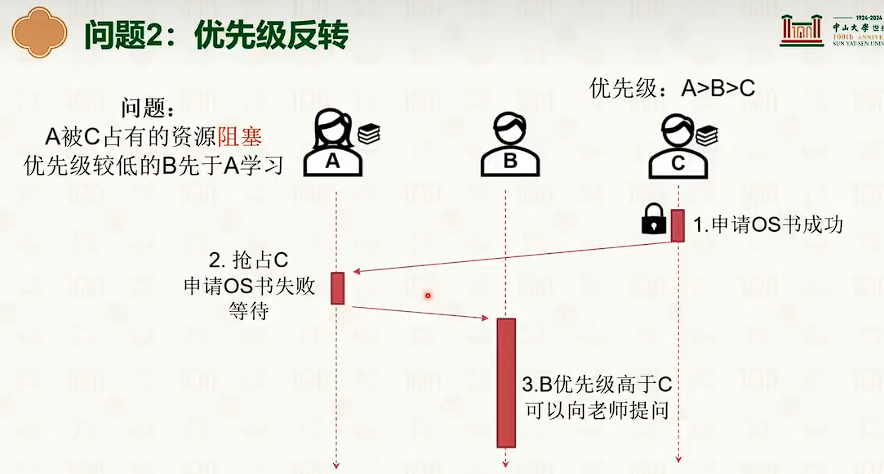
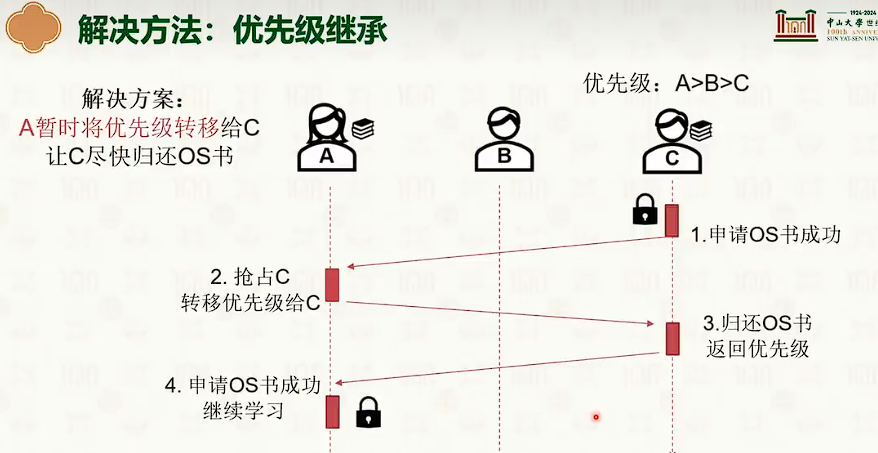
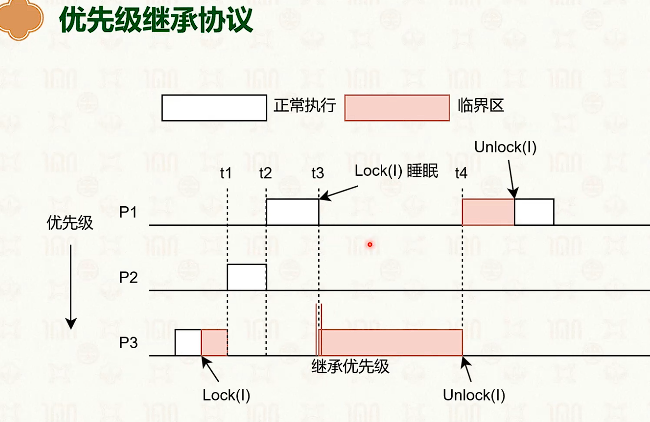
优先级反转
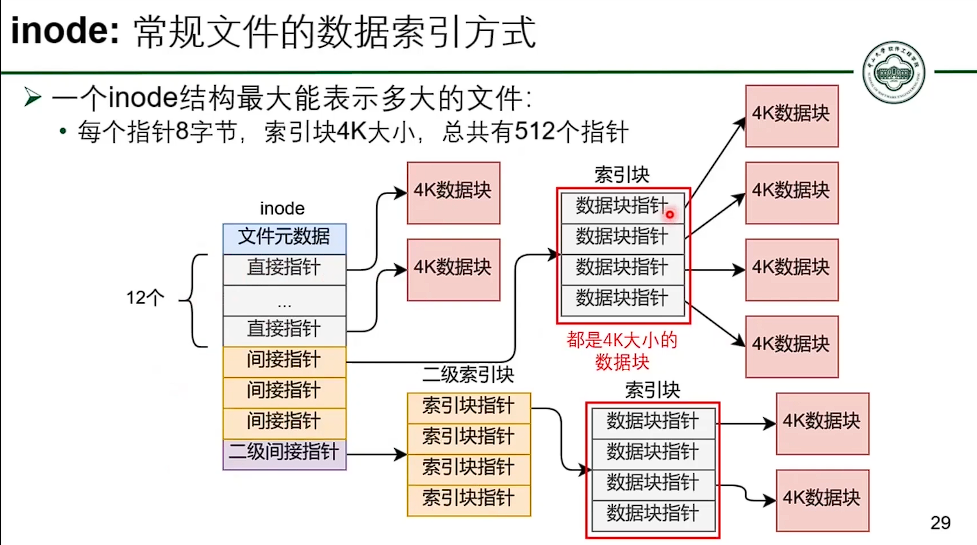
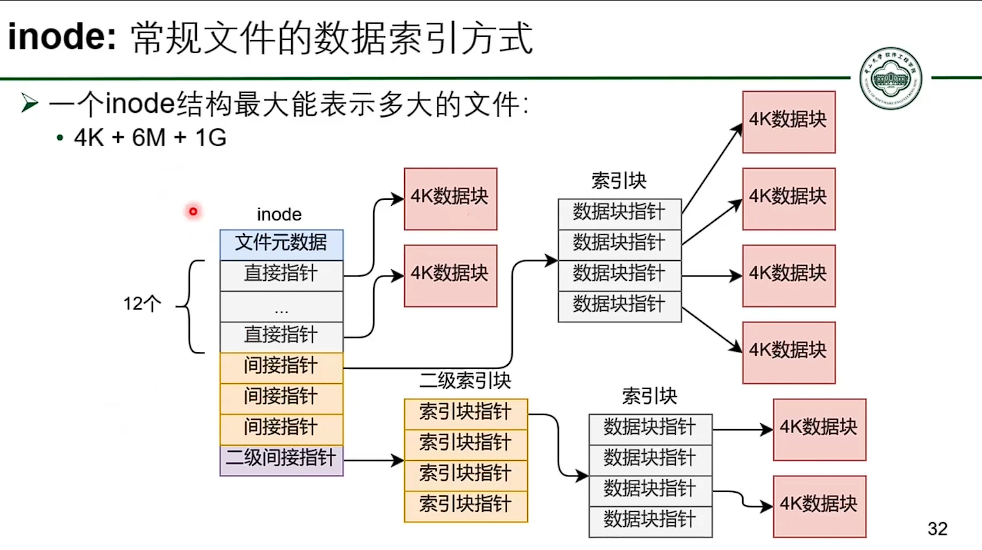
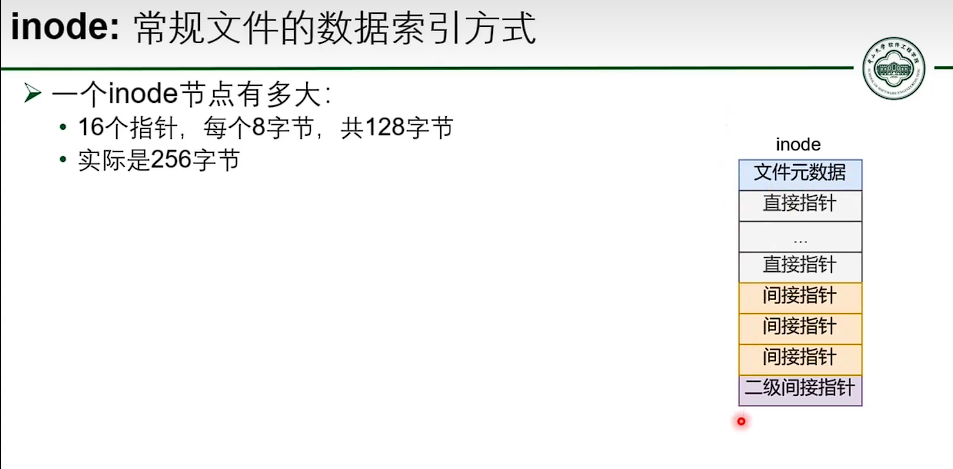
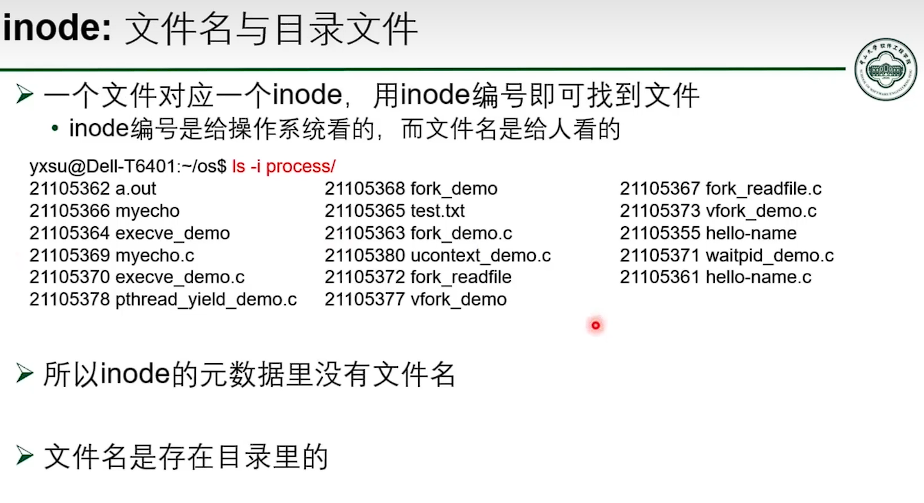
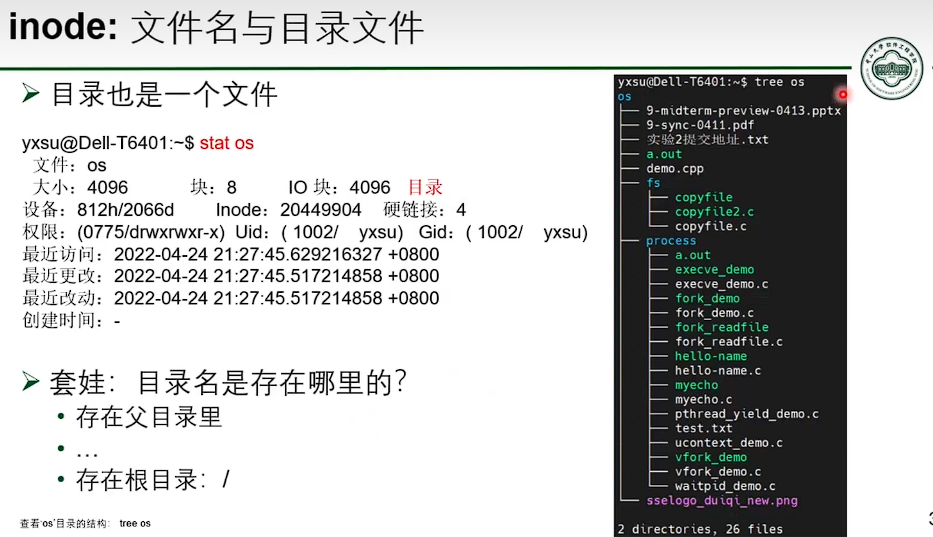
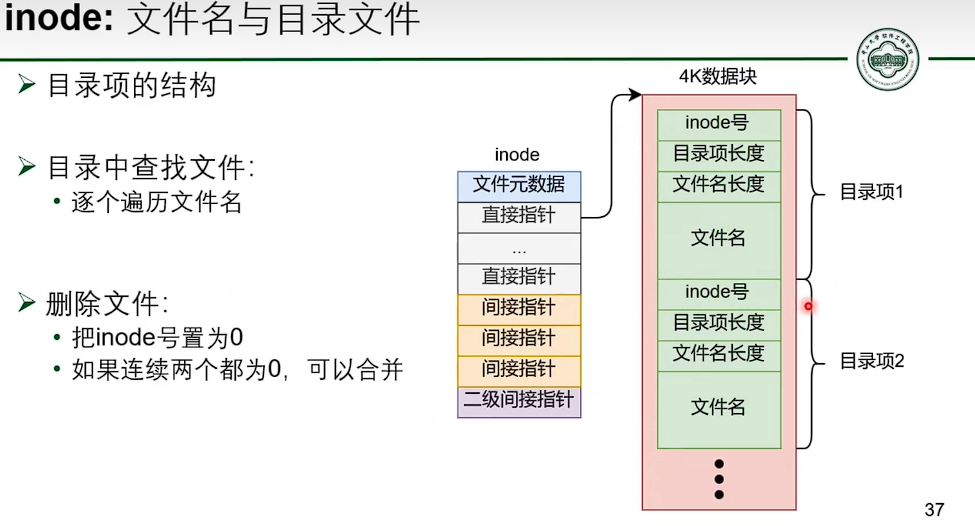
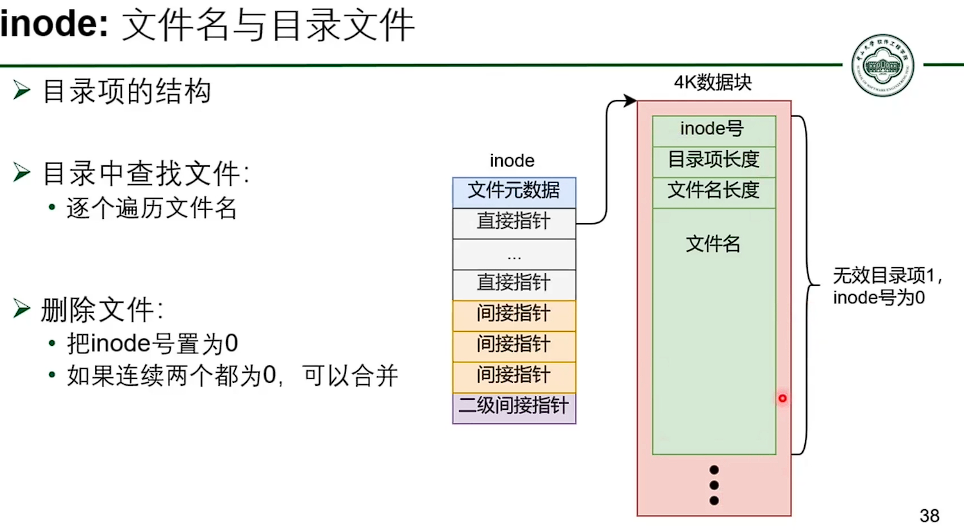
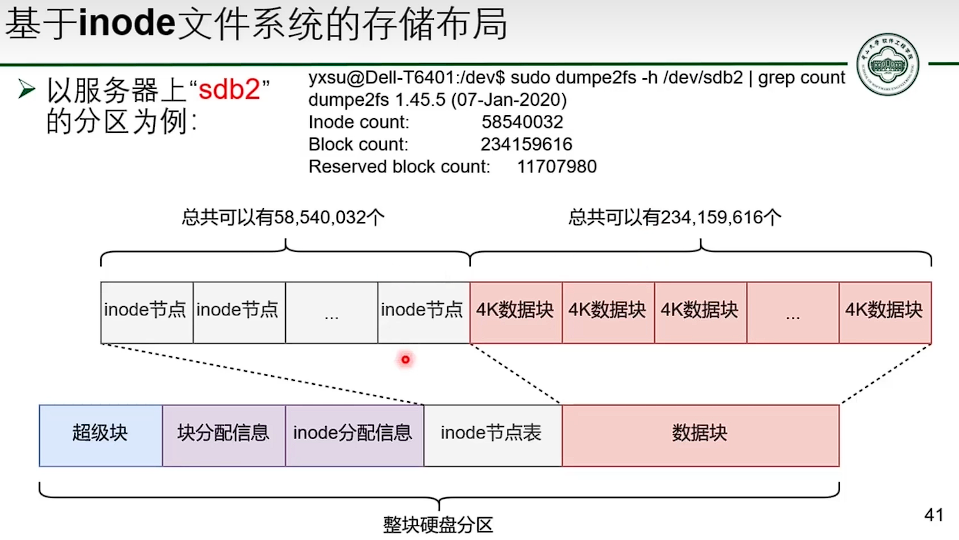
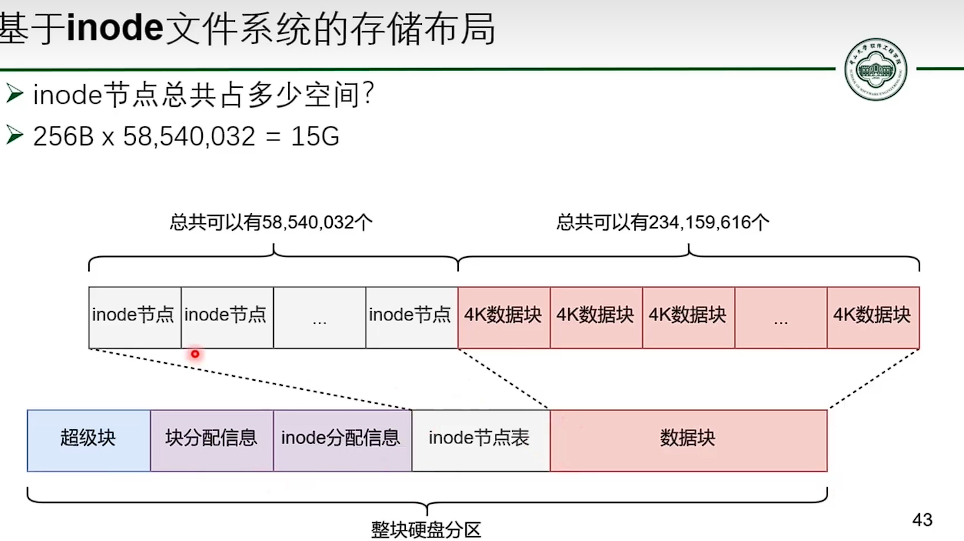
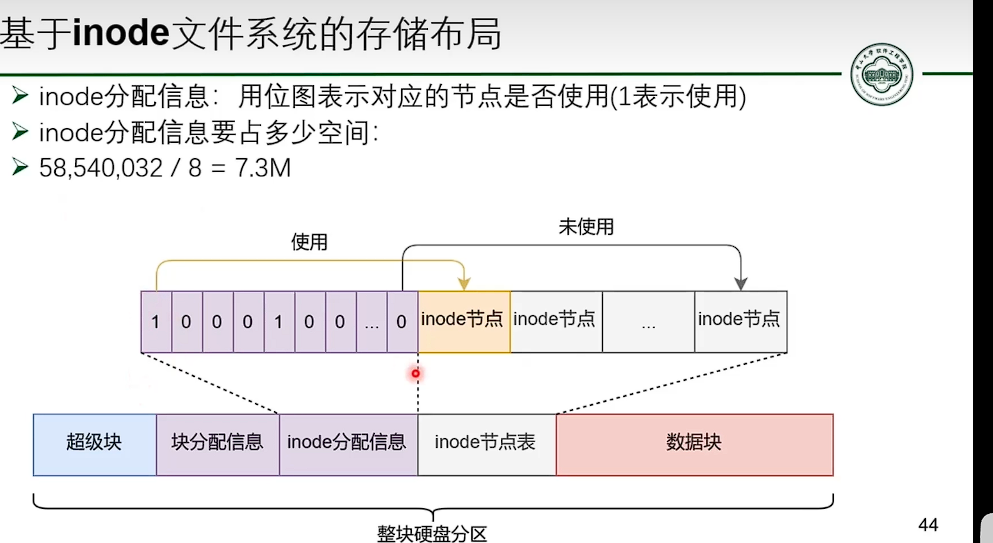
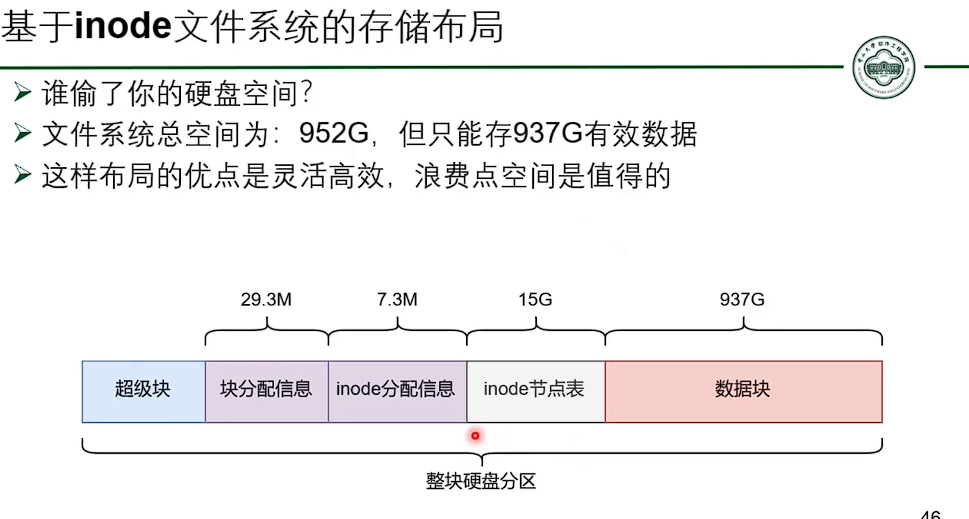
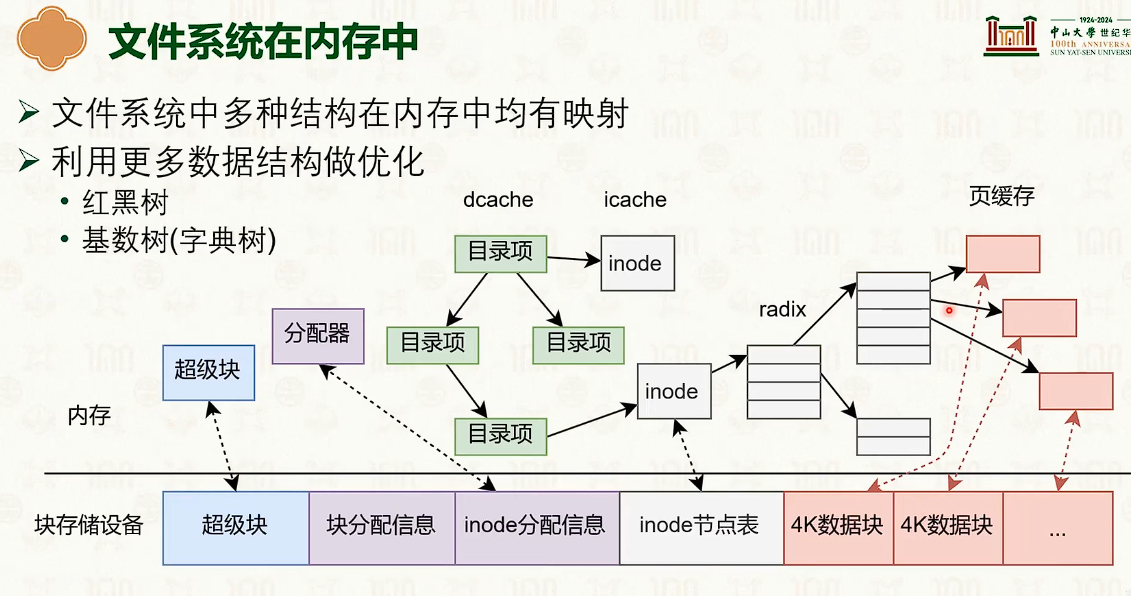
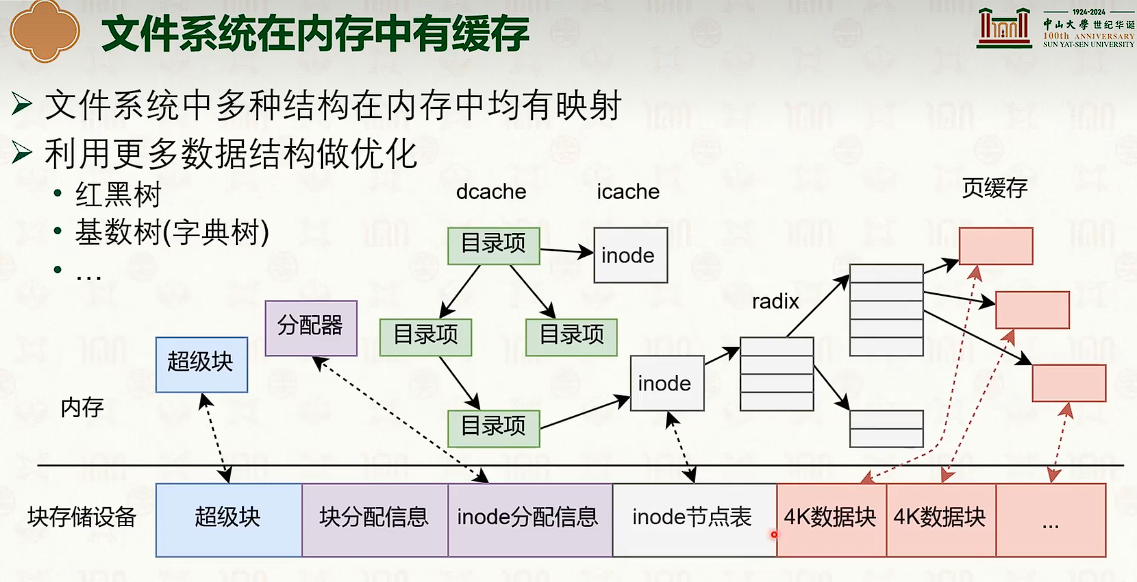
基于 inode 的文件系统

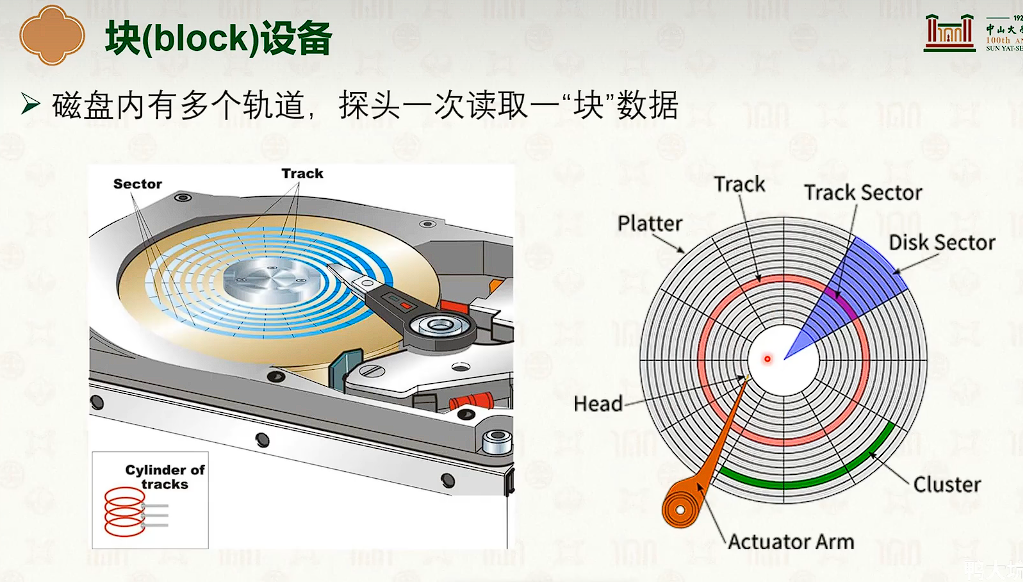
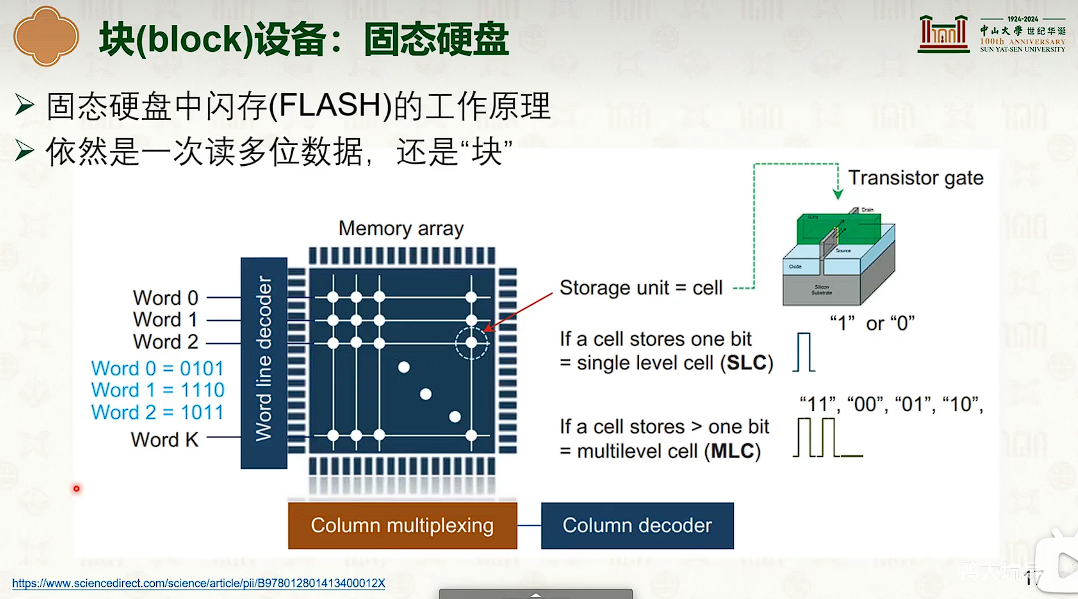
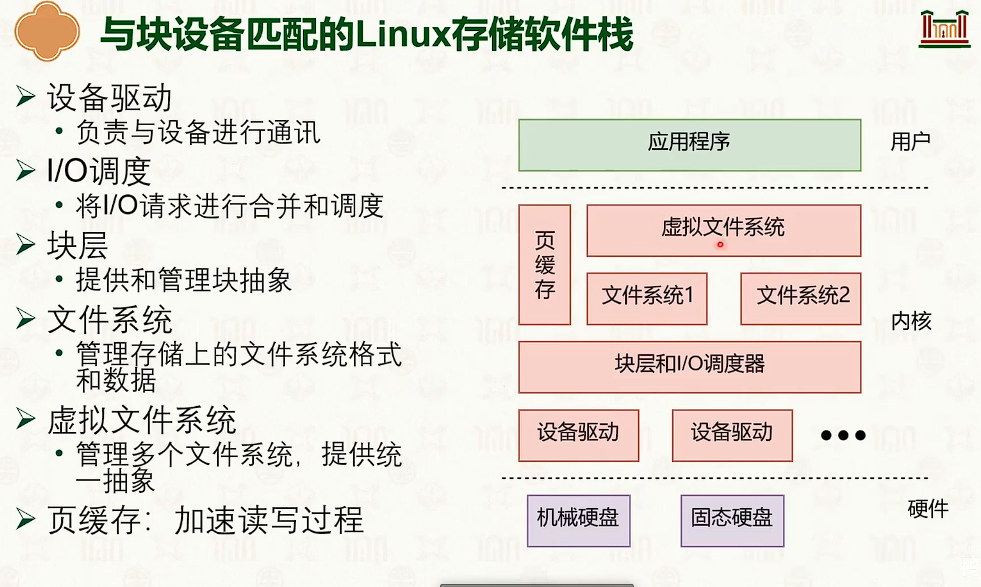

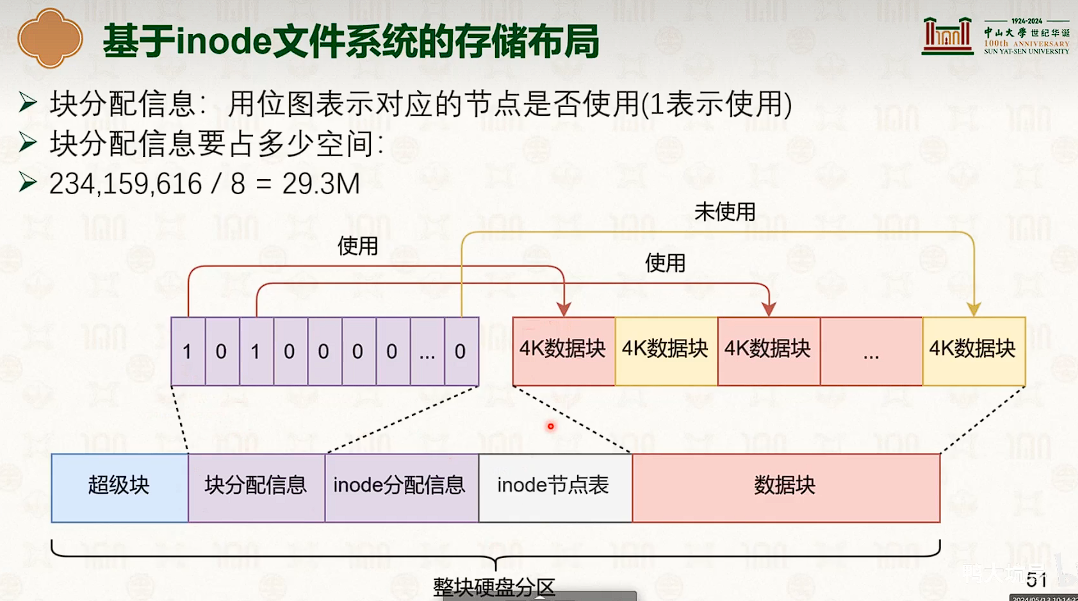
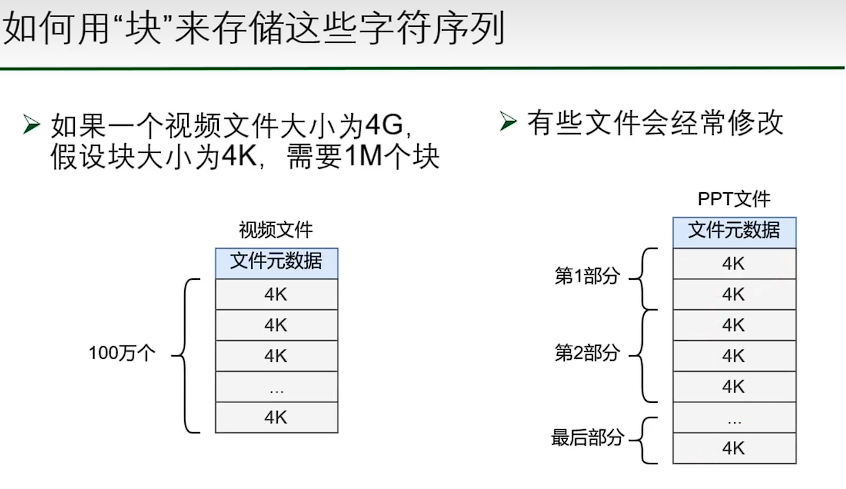
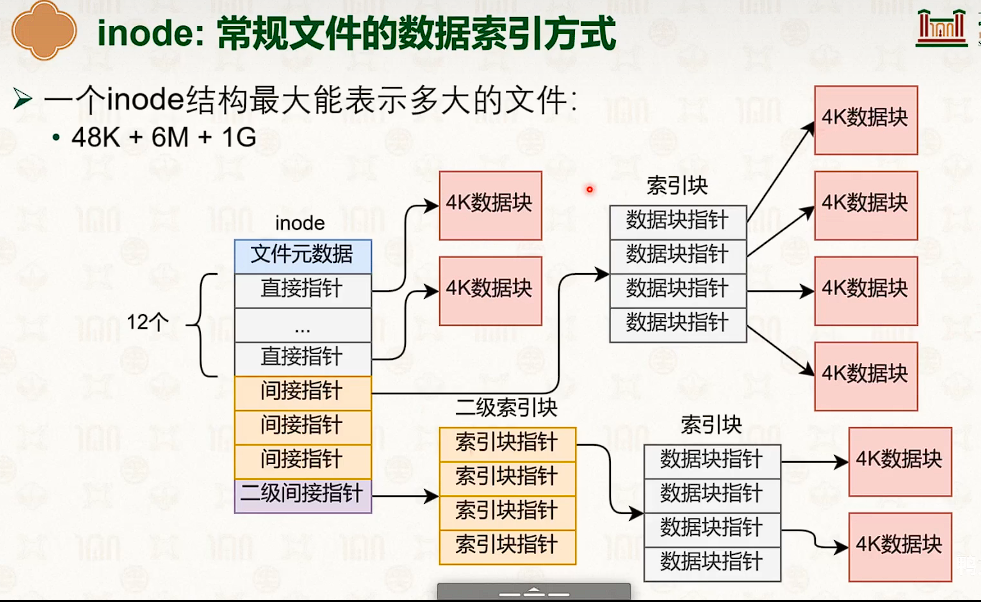
- 并没有减少指针数量。


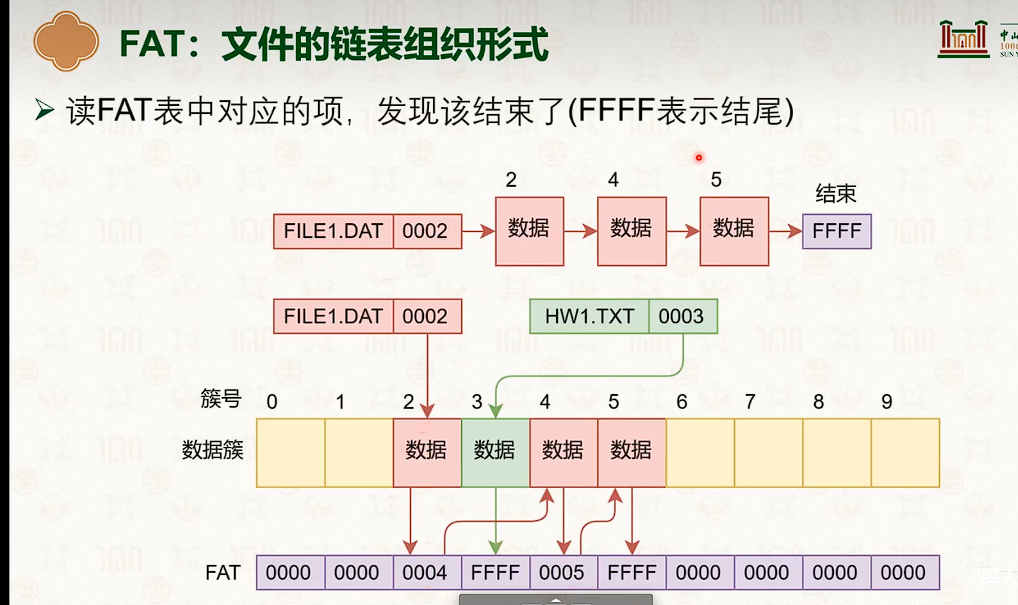
基于表的文件系统:FAT、NTFS



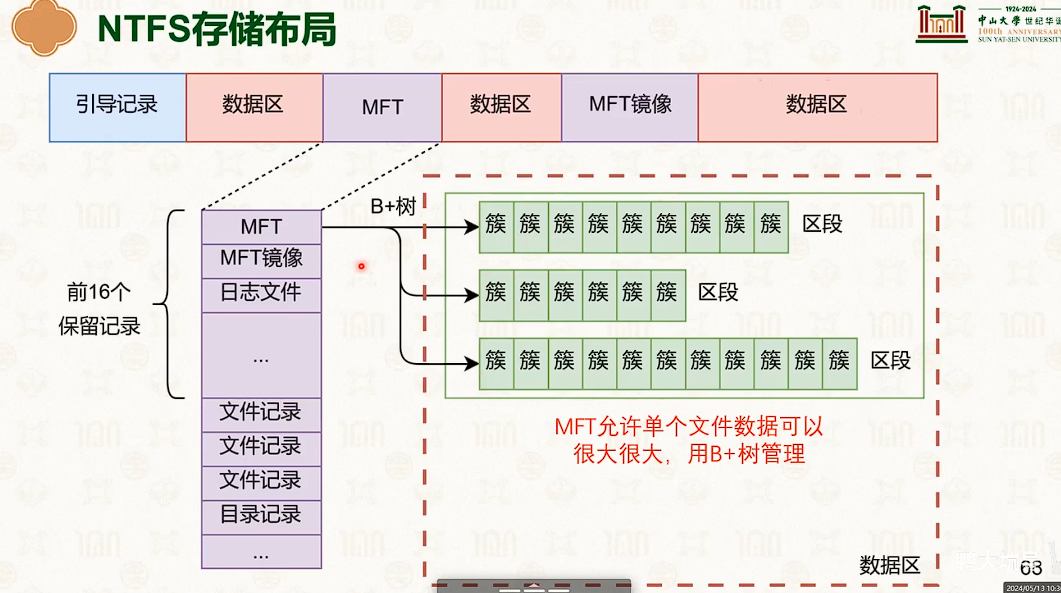
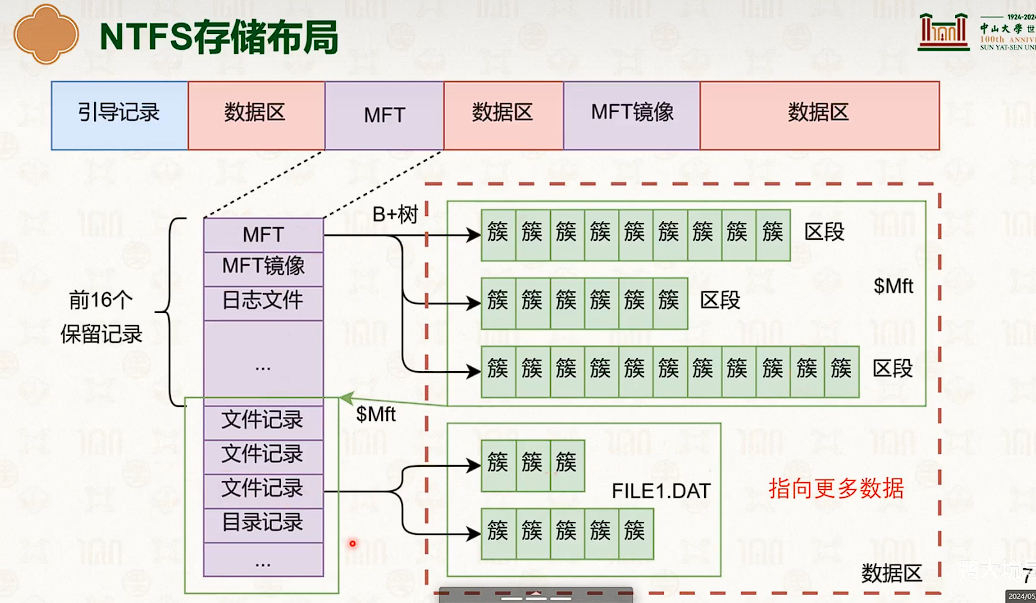
使用文件系统

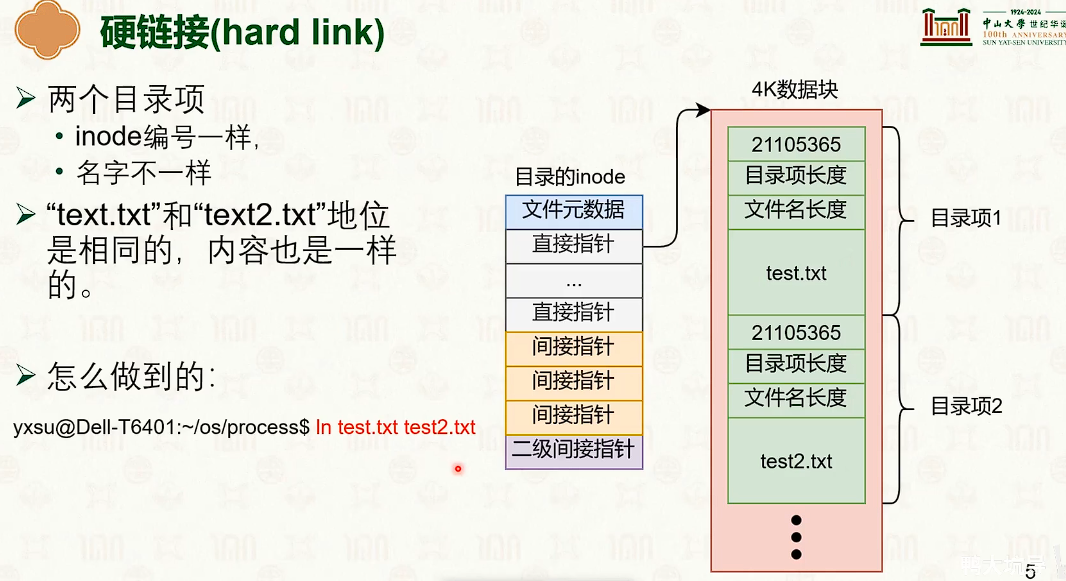
-
硬链接在目录的 inode 文件中存储的 inode 编号一样,只有文件名不同,操控文件的时候,会操控同样的 inode 也就是完全一样的文件。
-
硬链接和原文件的地位一样,存在一个引用计数。删除一个硬链接或者源文件会是引用计数减一,直到为0才会删除。
-
windows中没有硬链接。

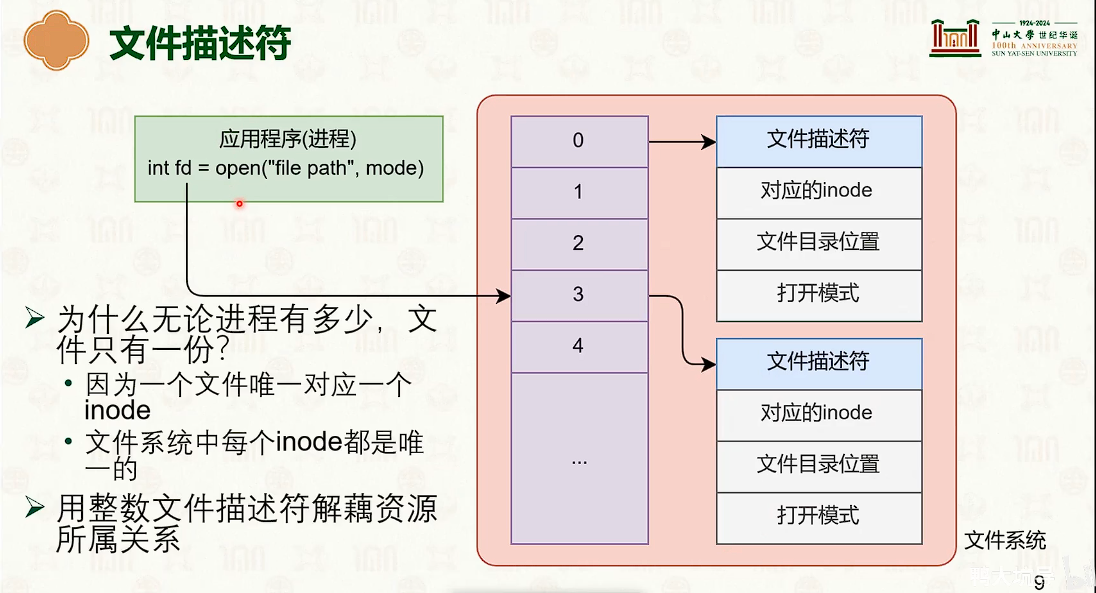

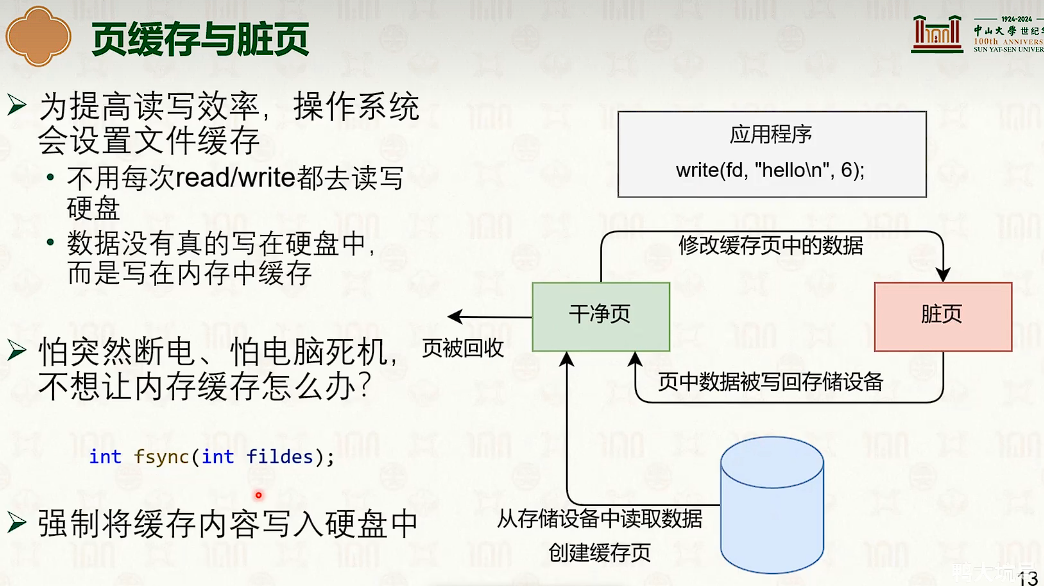
写回+写分配。
内存映射

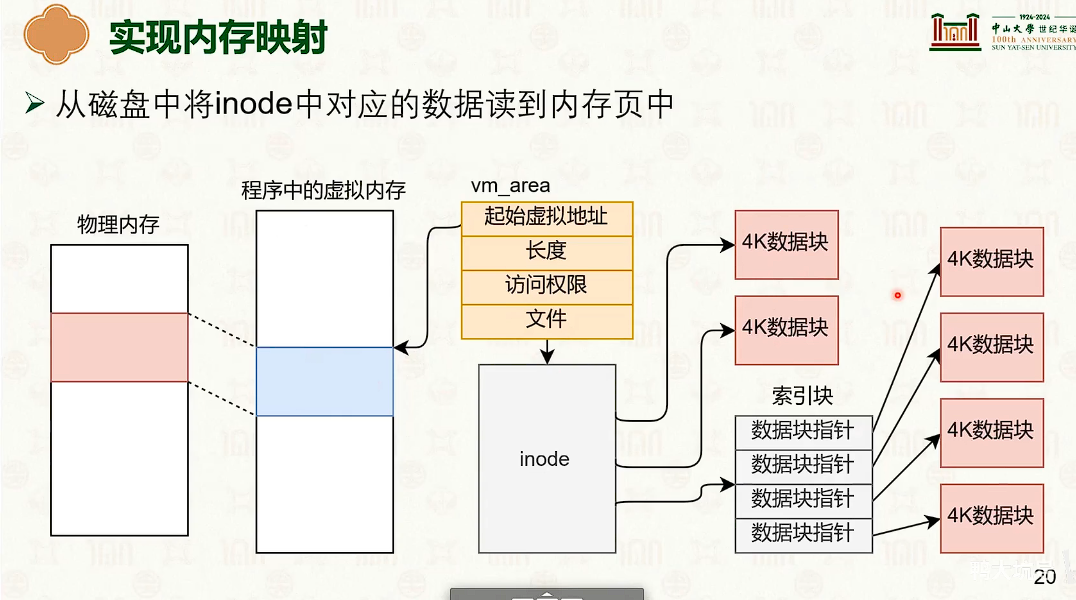

文件系统的高级功能

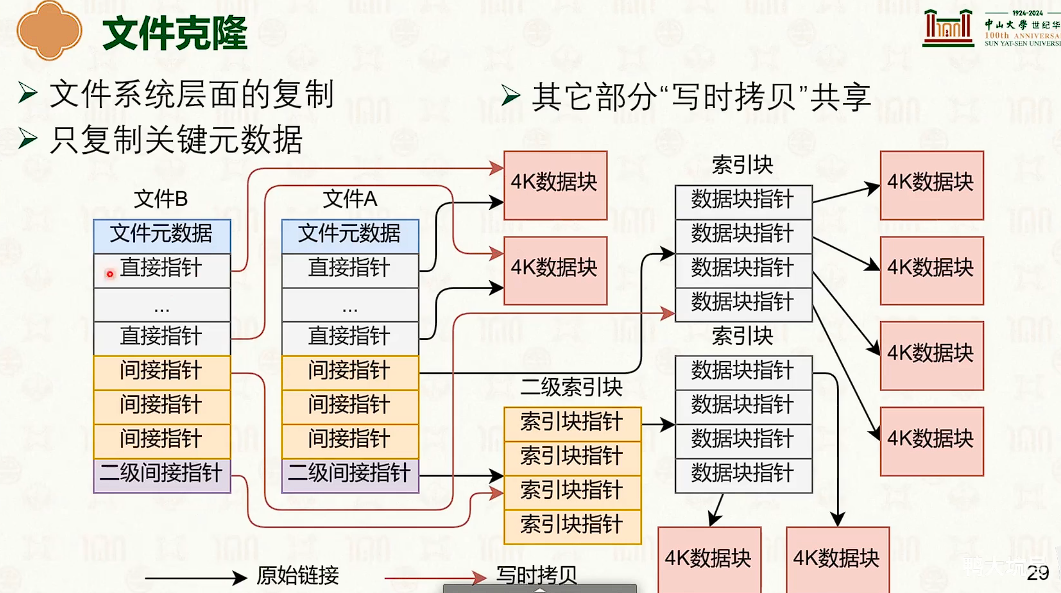
写时拷贝的作用:
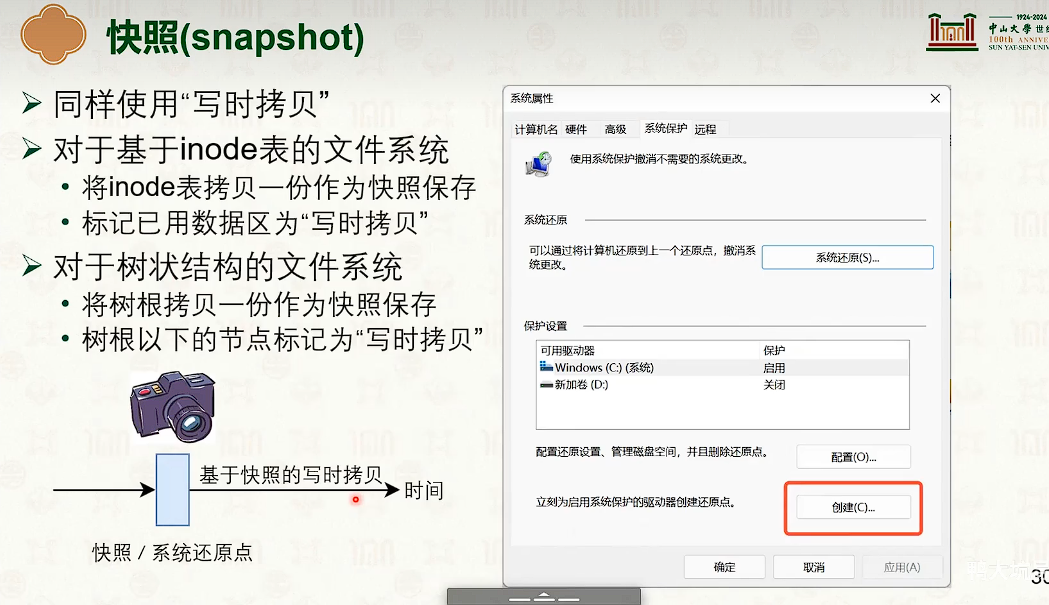
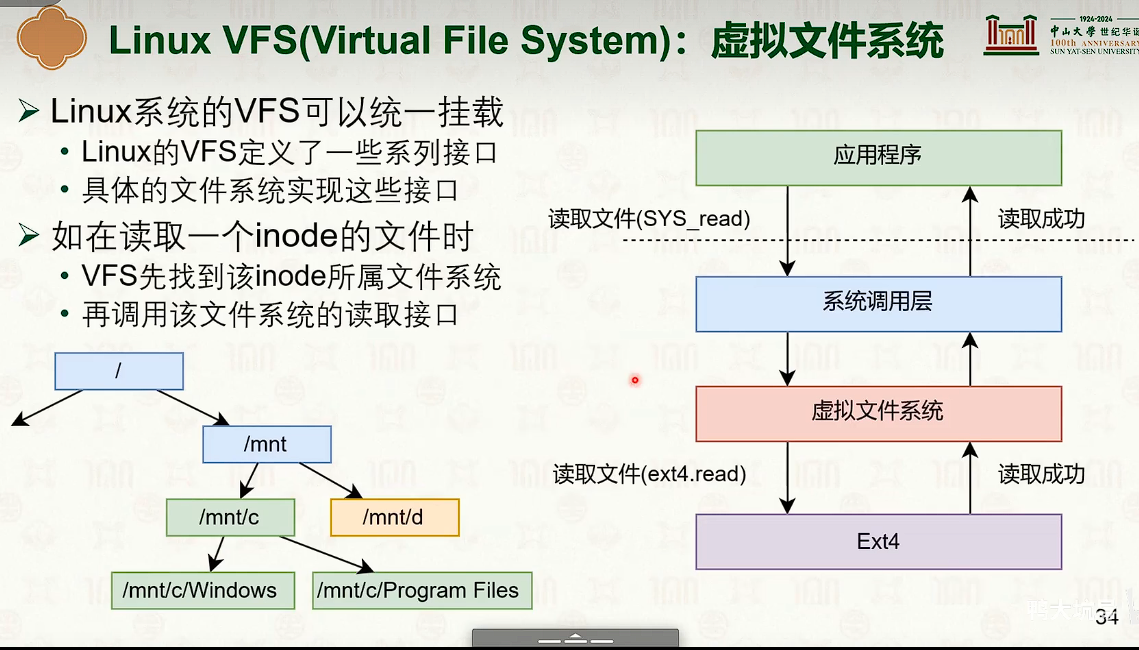
虚拟文件系统
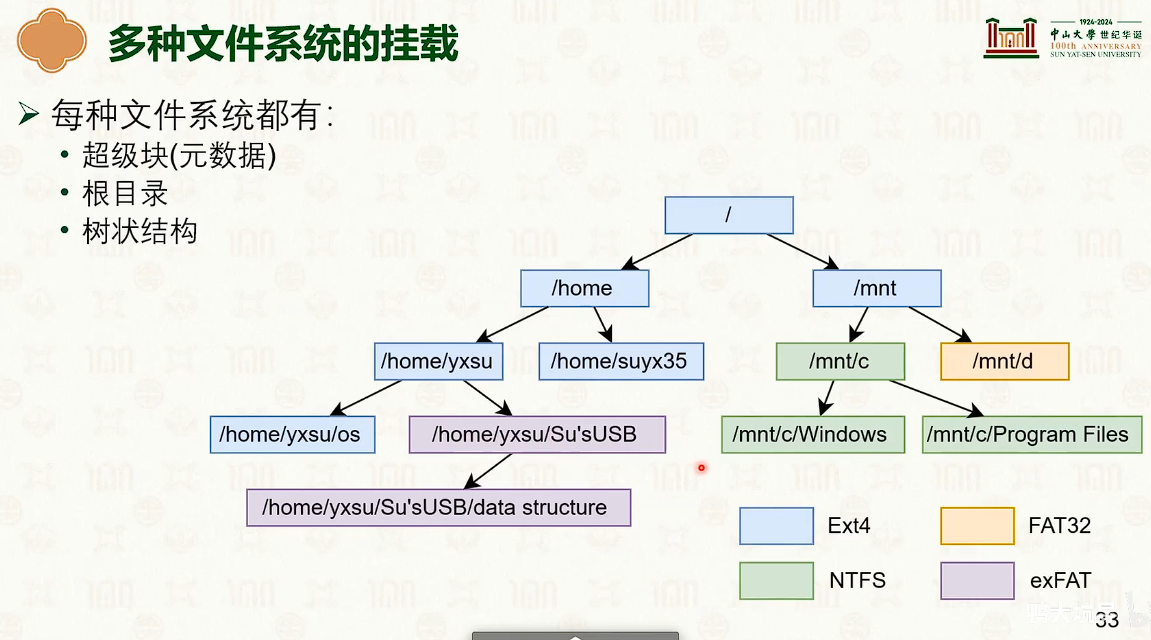
- 可以共存多套文件系统


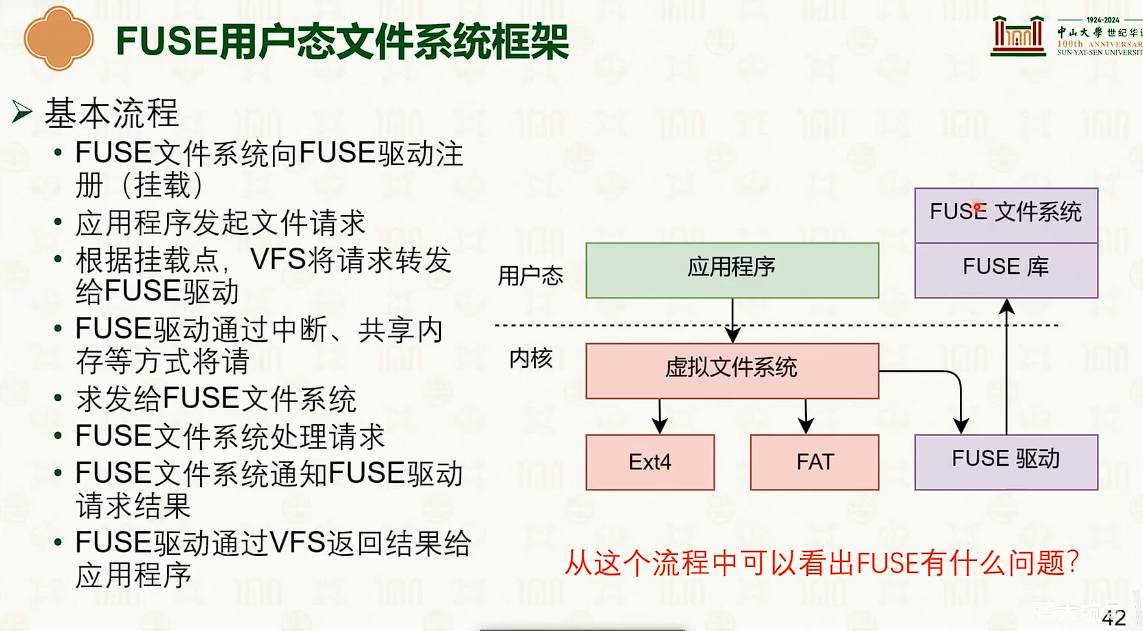
用户态文件系统

文件系统崩溃一致性:原子更新技术

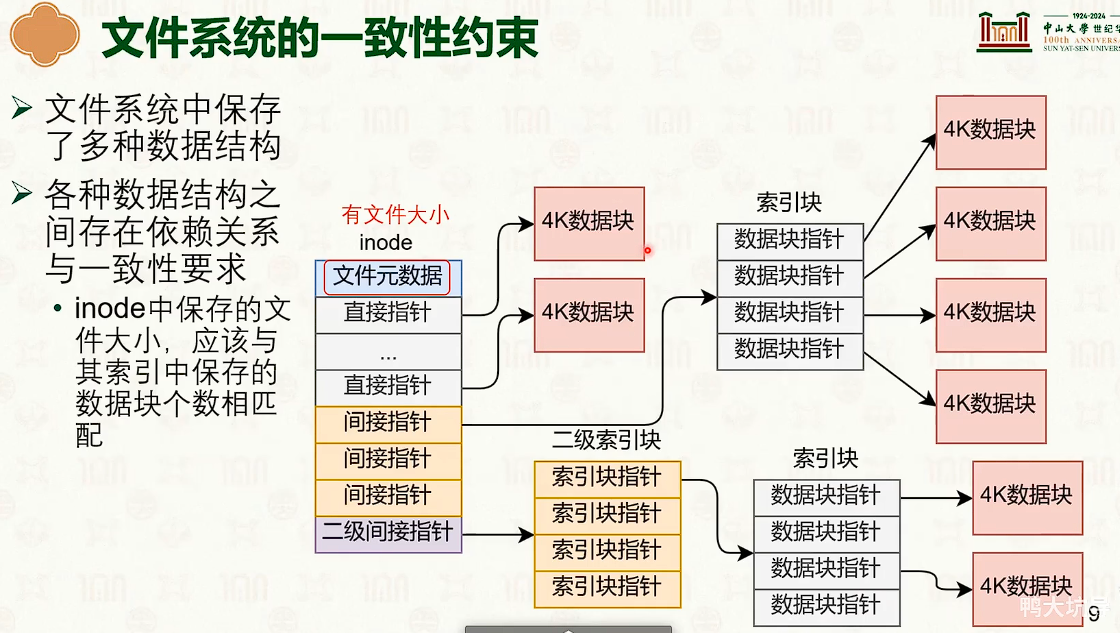
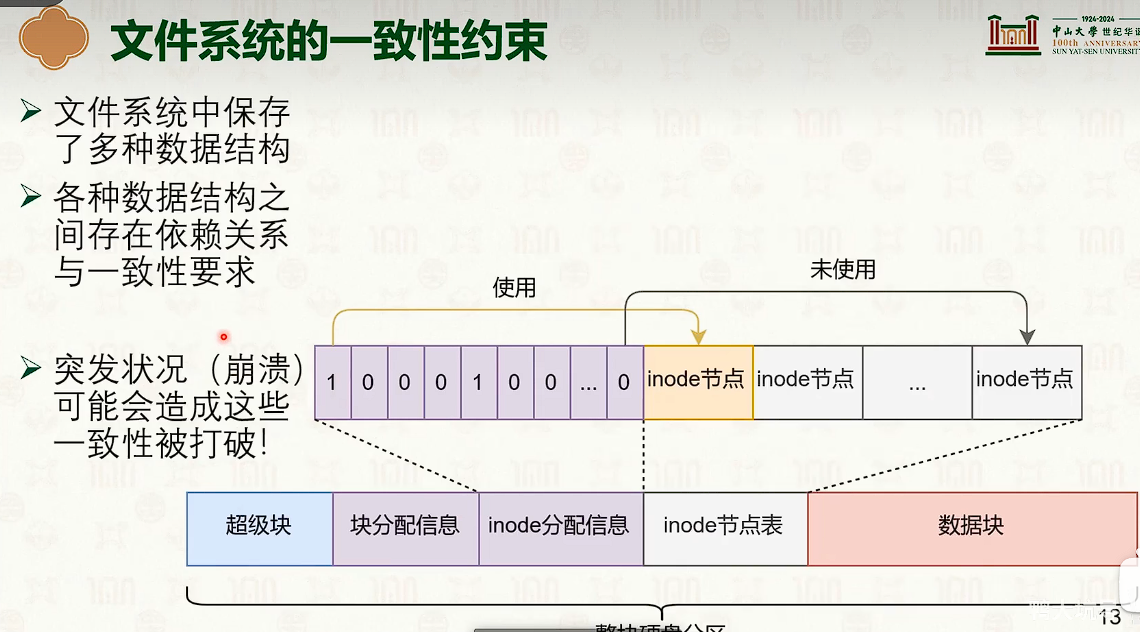





- 另一方面来说,操作系统不能像数据库一样,随意使用WAL。



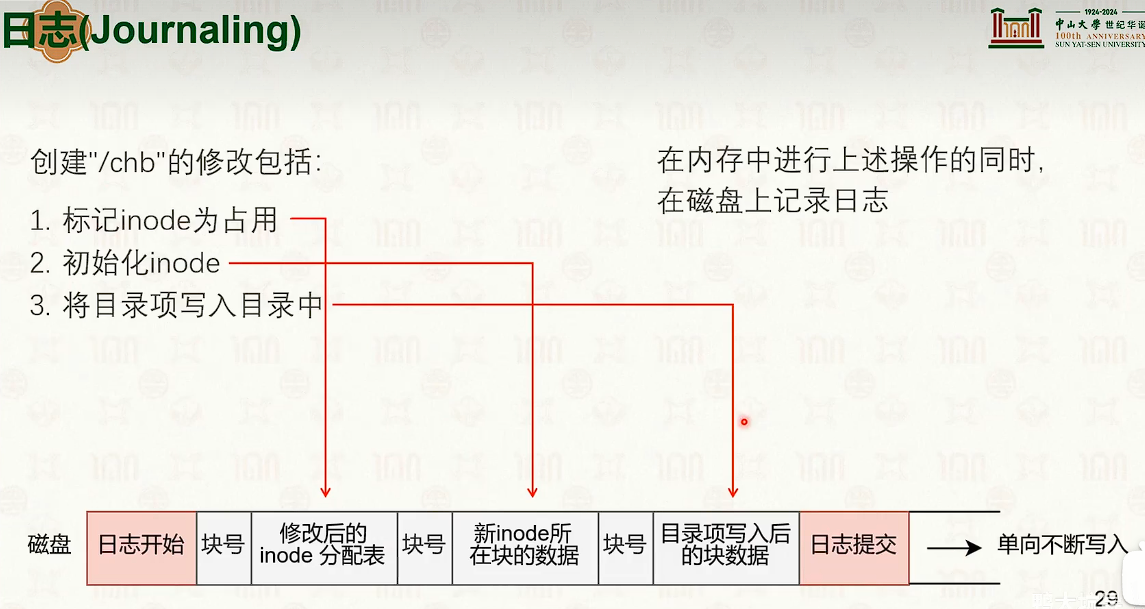

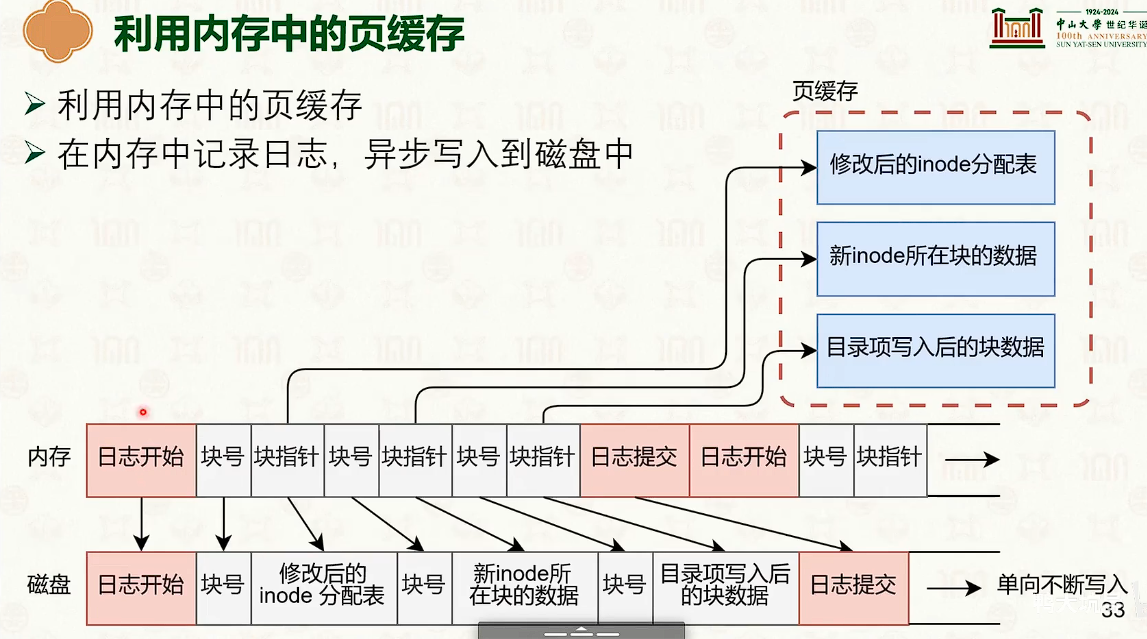




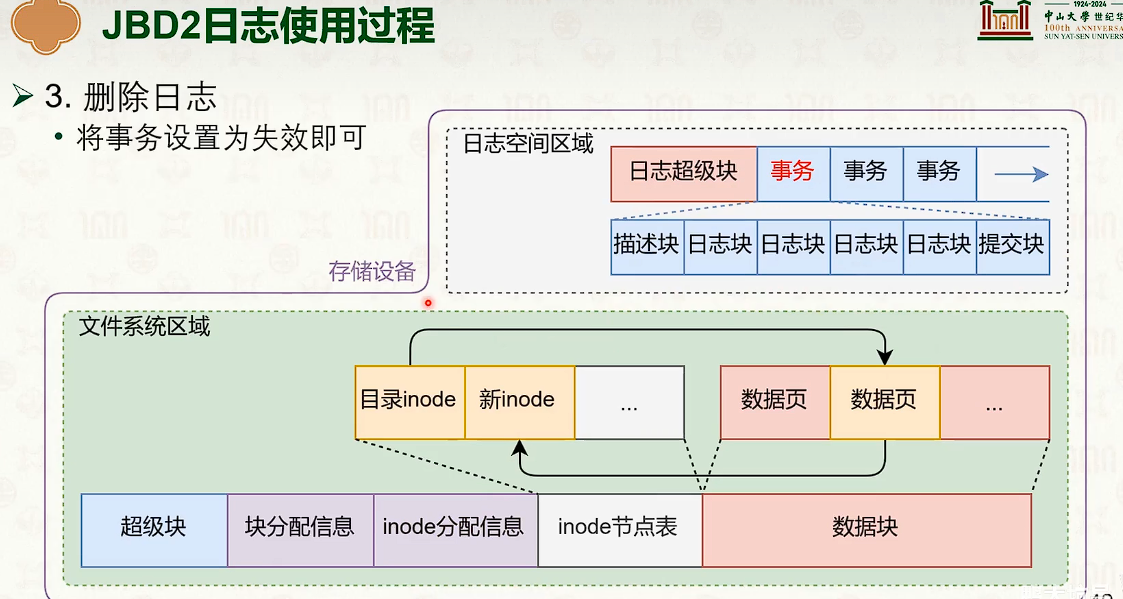
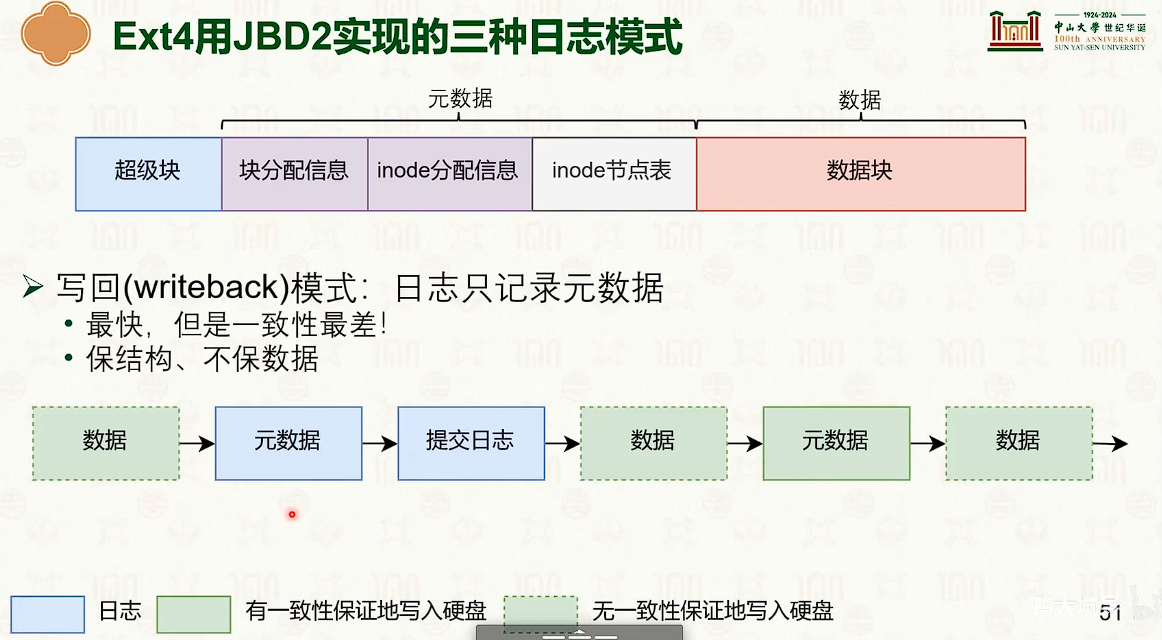
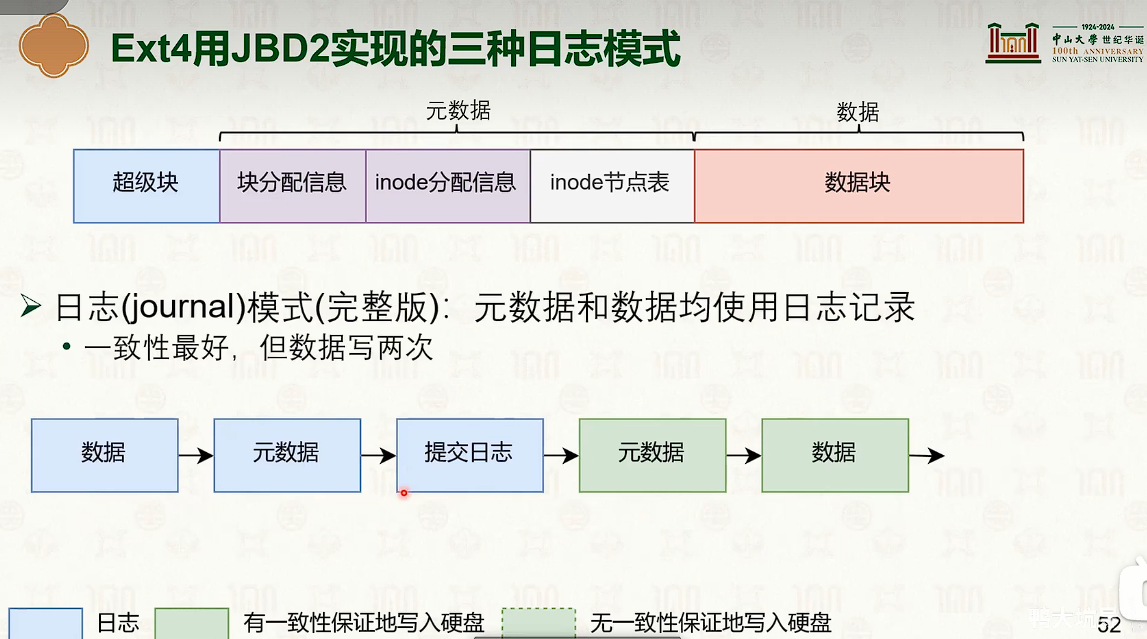
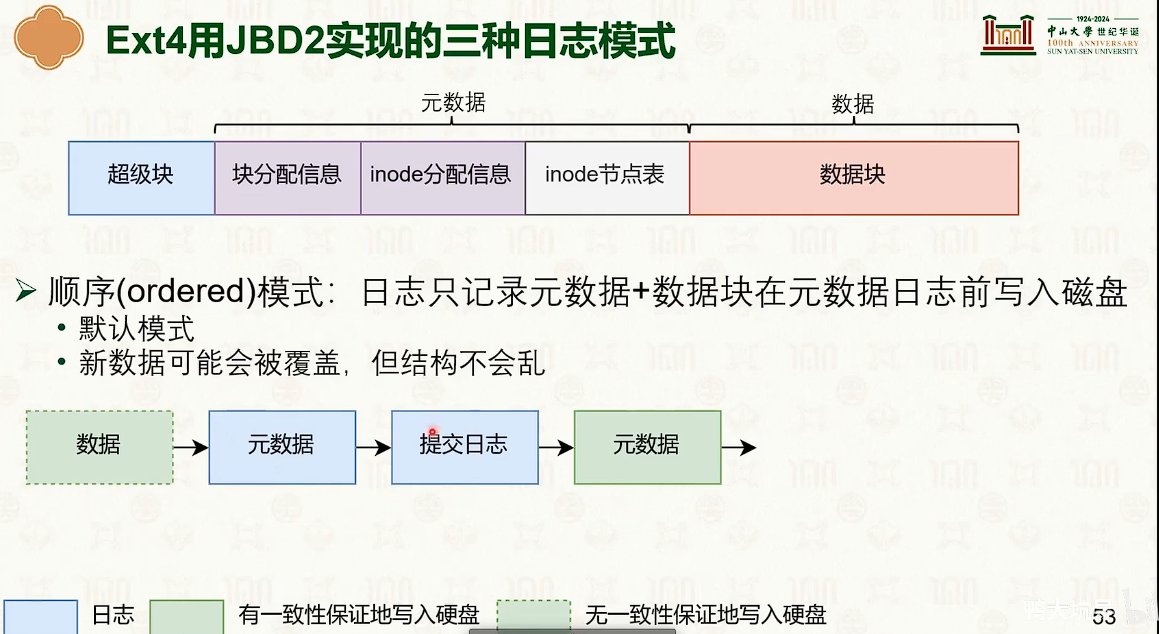
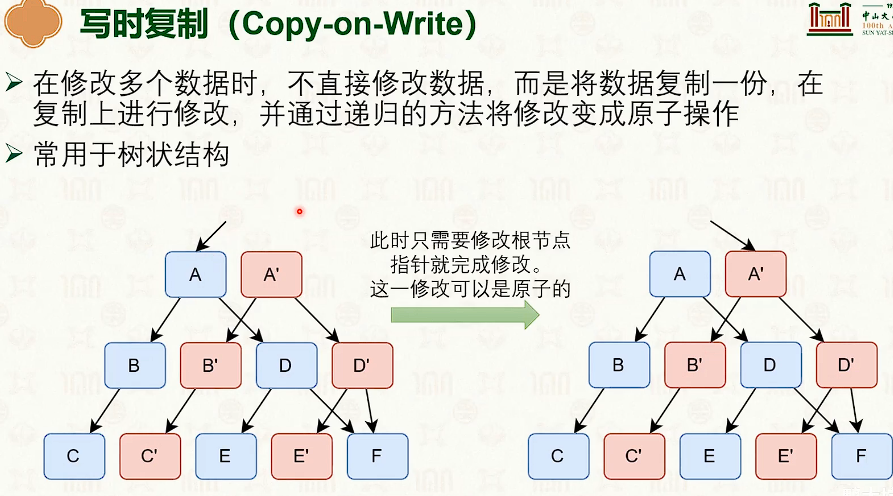
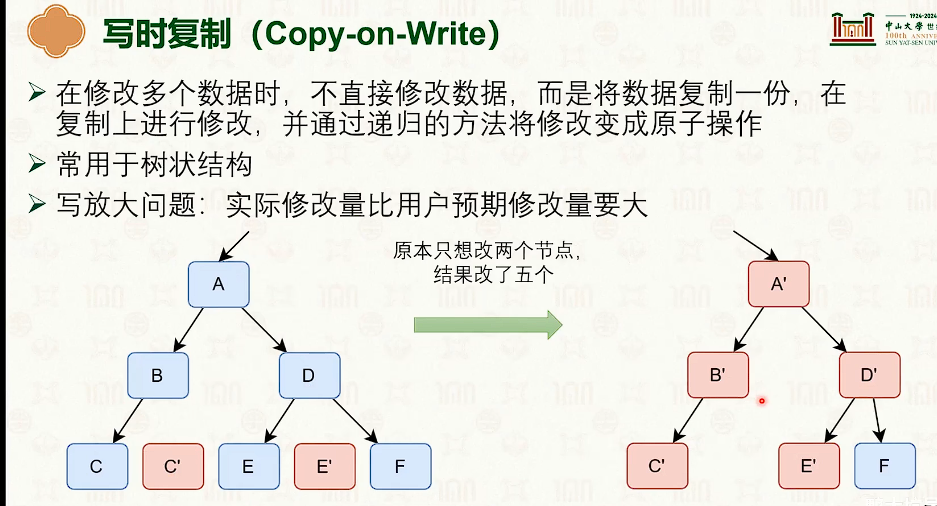
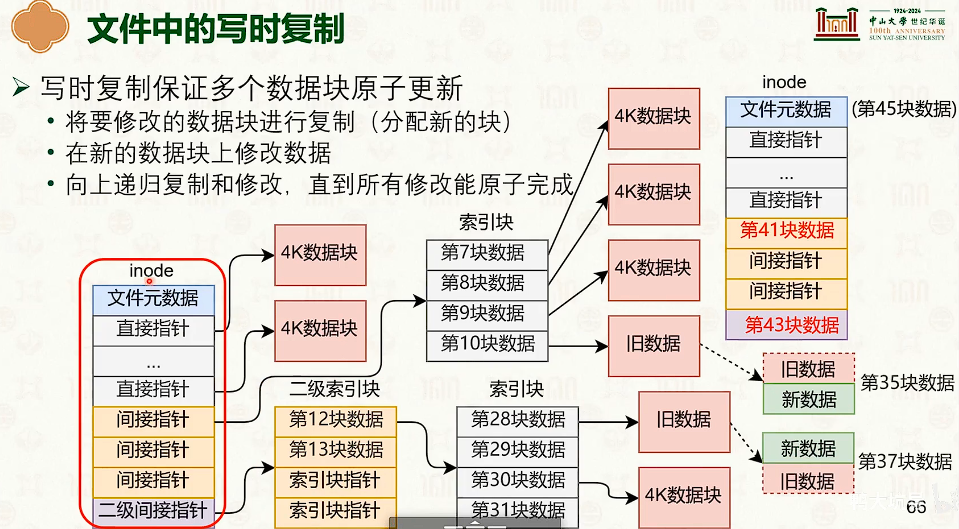
- 写时复制是时间优先,日志是空间优先。

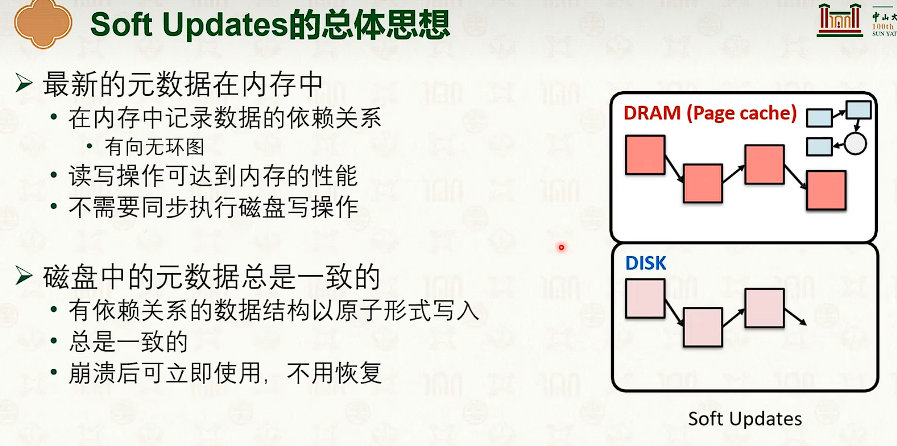

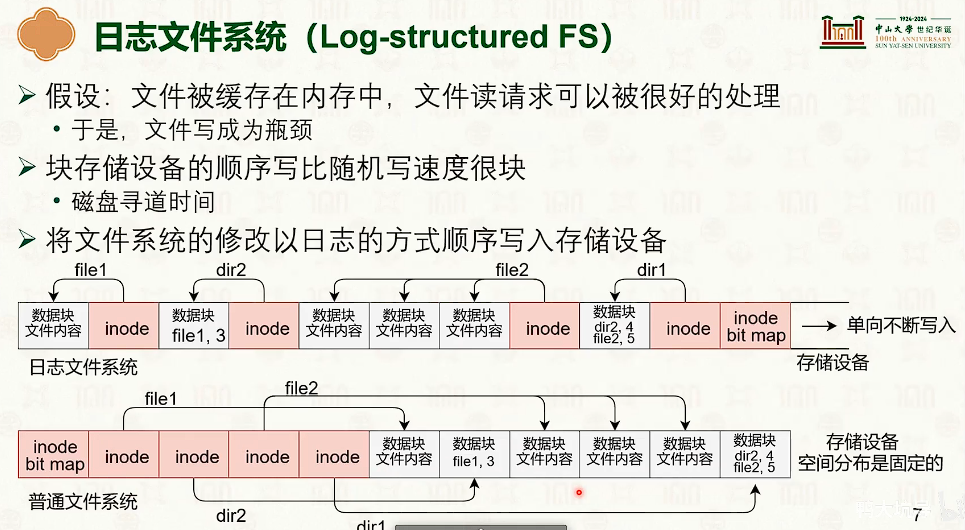
日志文件系统

这不是 LSM 与 B+ 长久不衰之争嘛
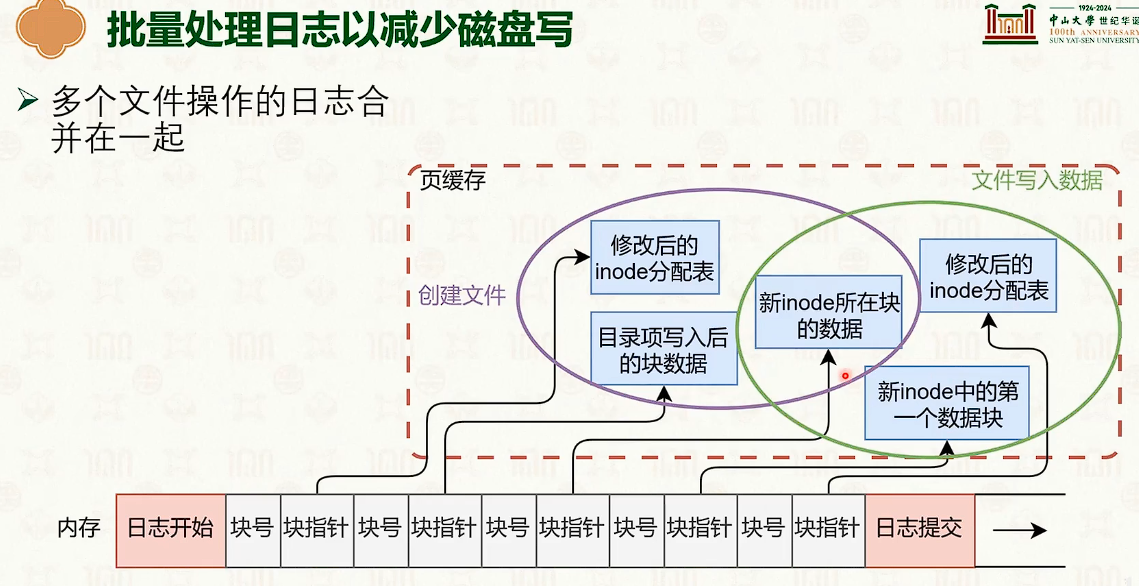
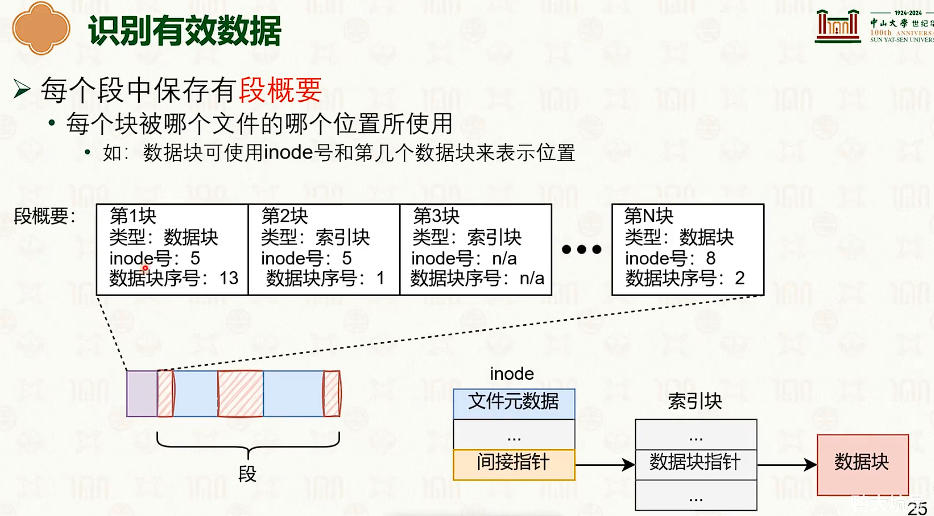
日志系统:合并,查找,写入缓存。


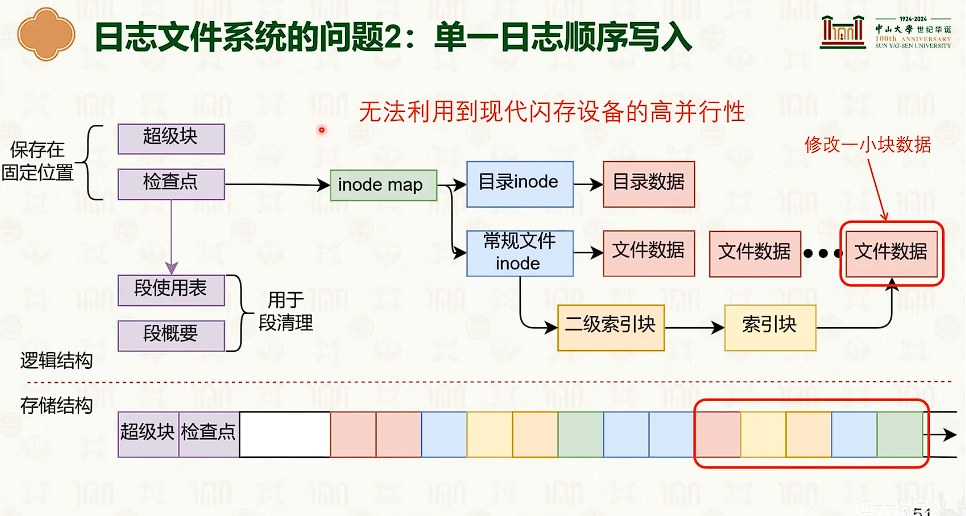
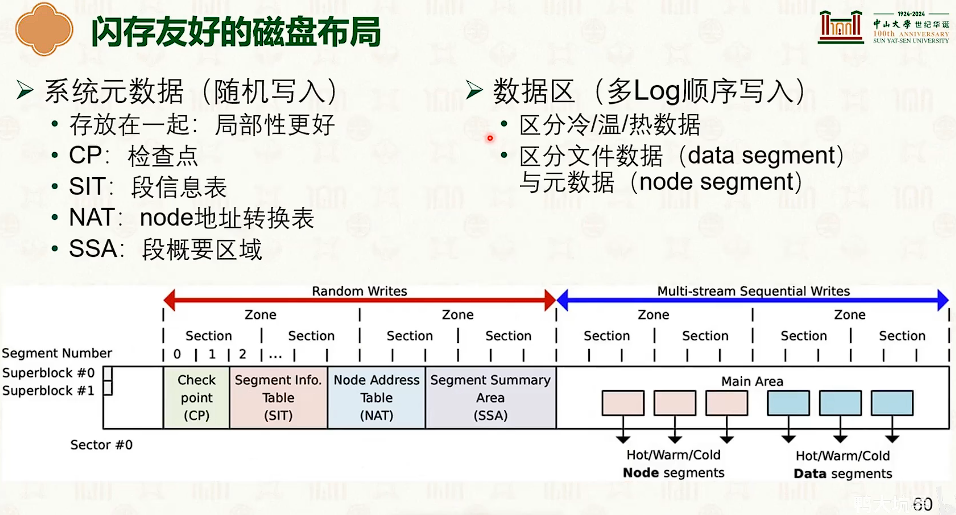
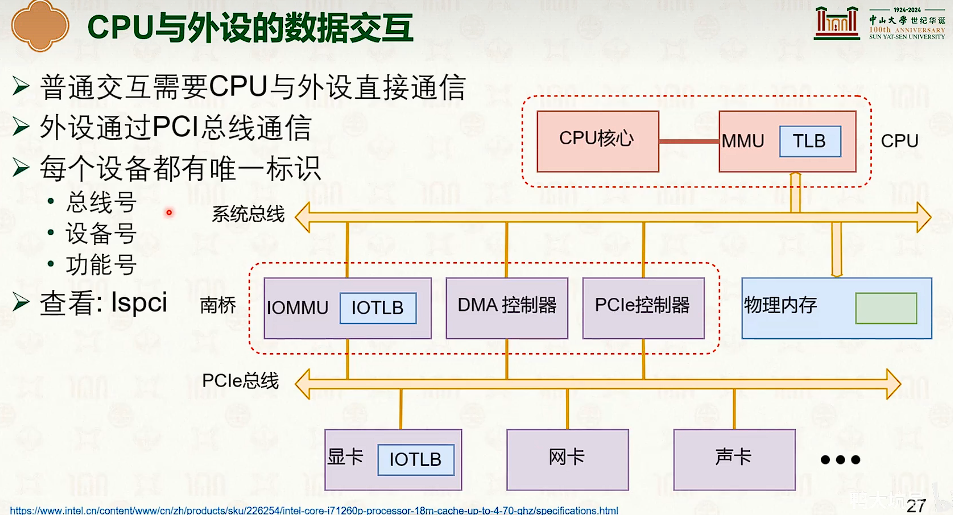
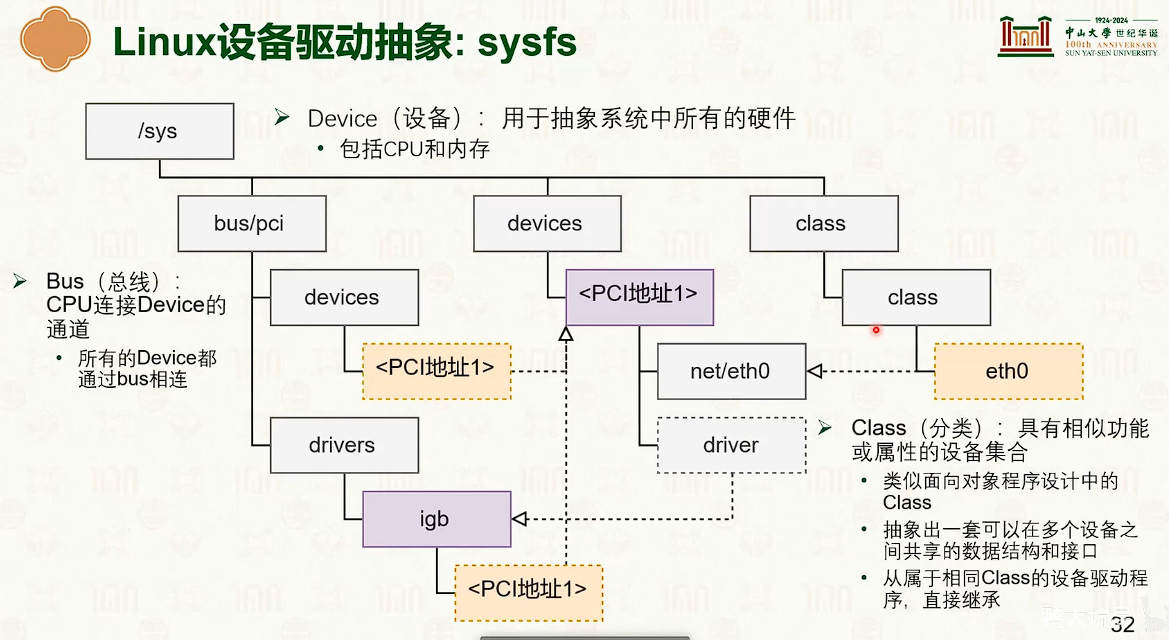
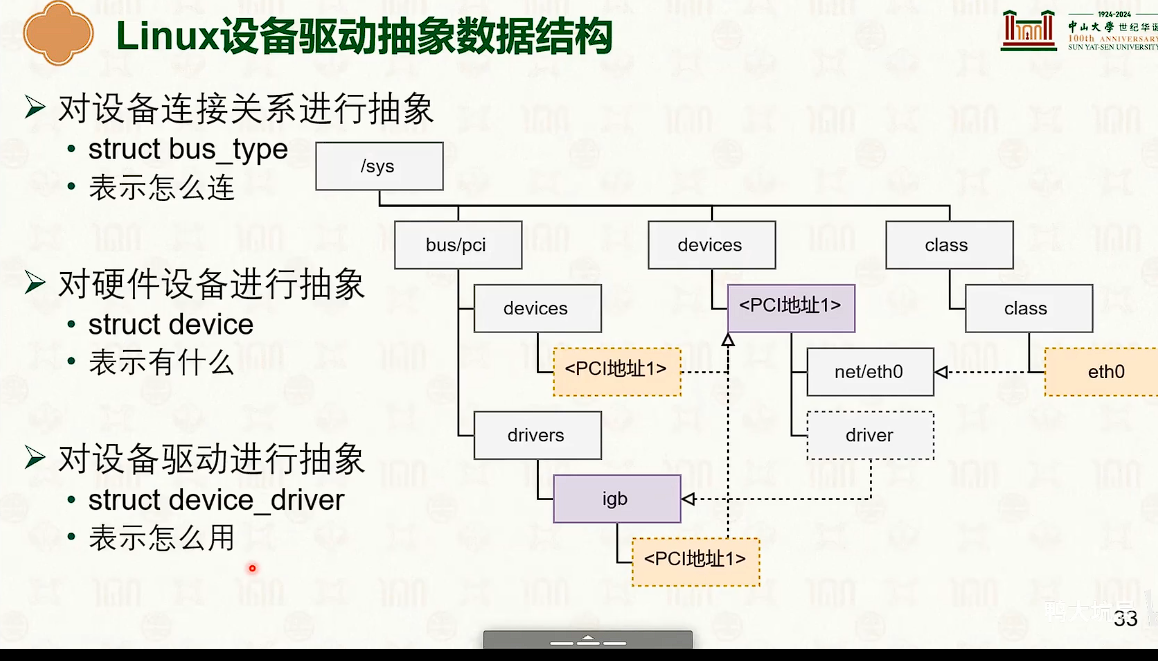
设备管理:分类与交互

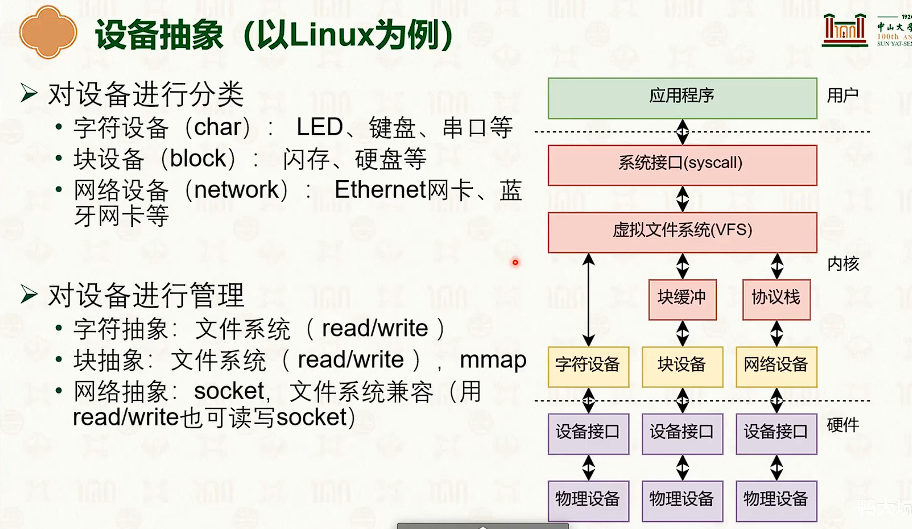


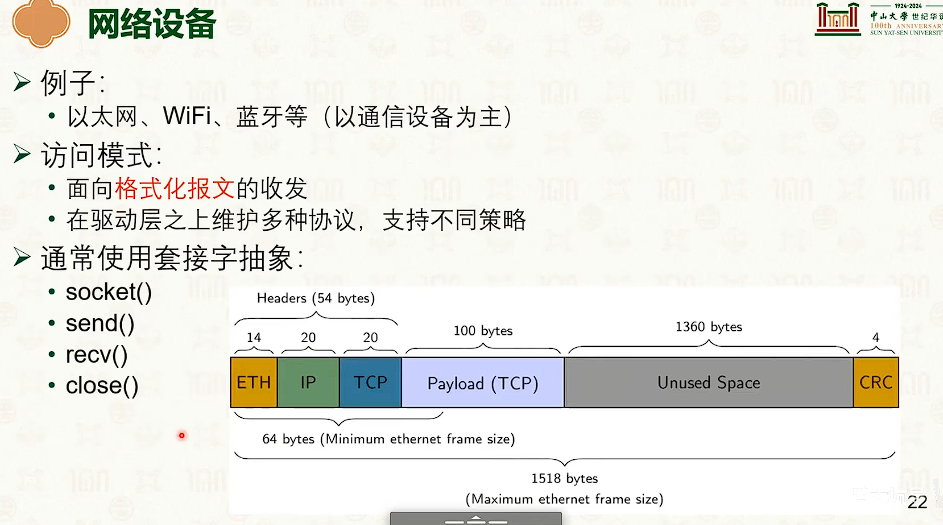
设备与操作系统的交互
可编程IO(Programmable IO,PIO)

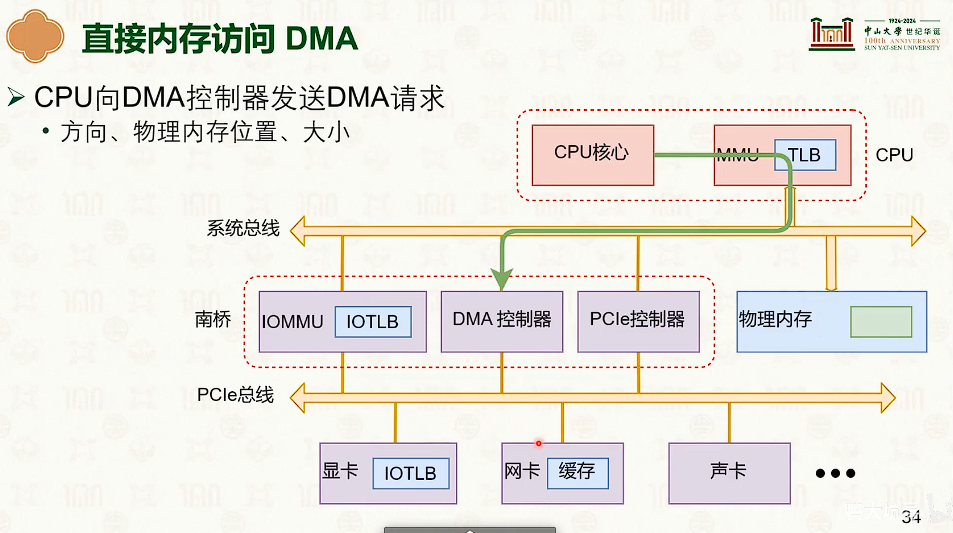
直接内存访问(Direct Memory Access,DMA)
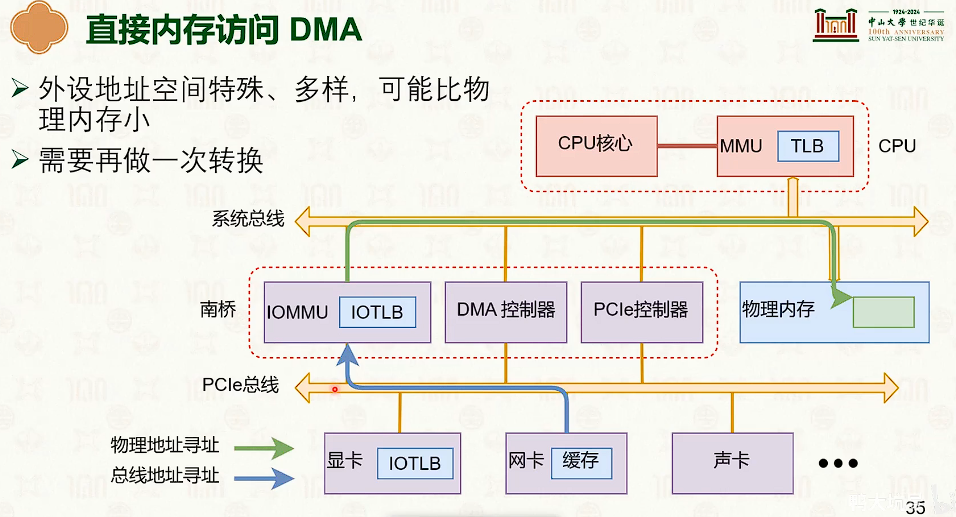
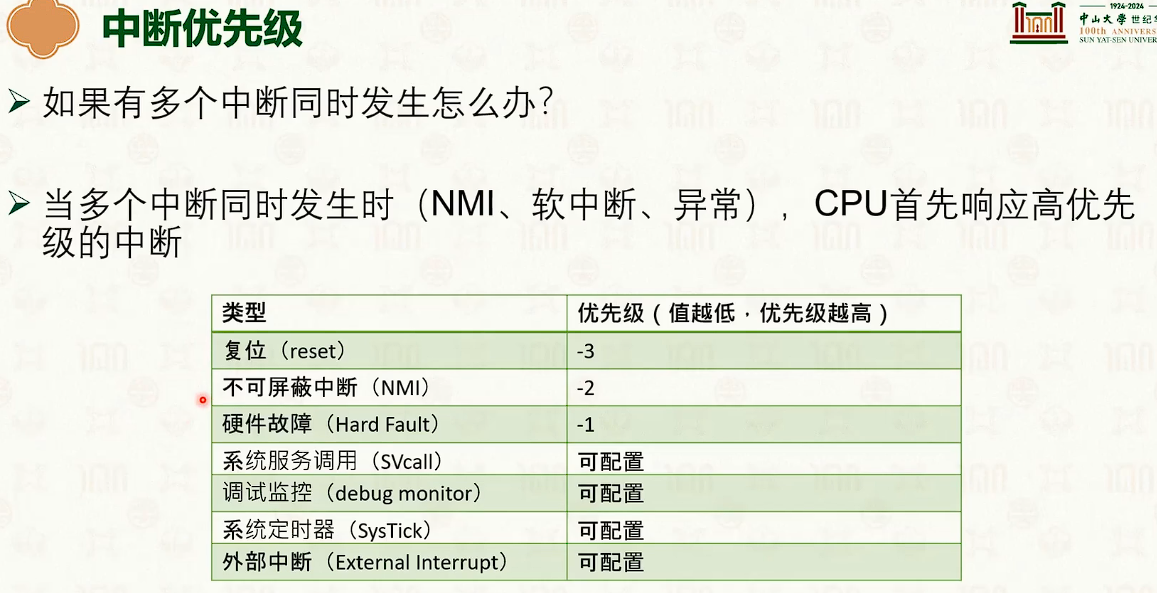
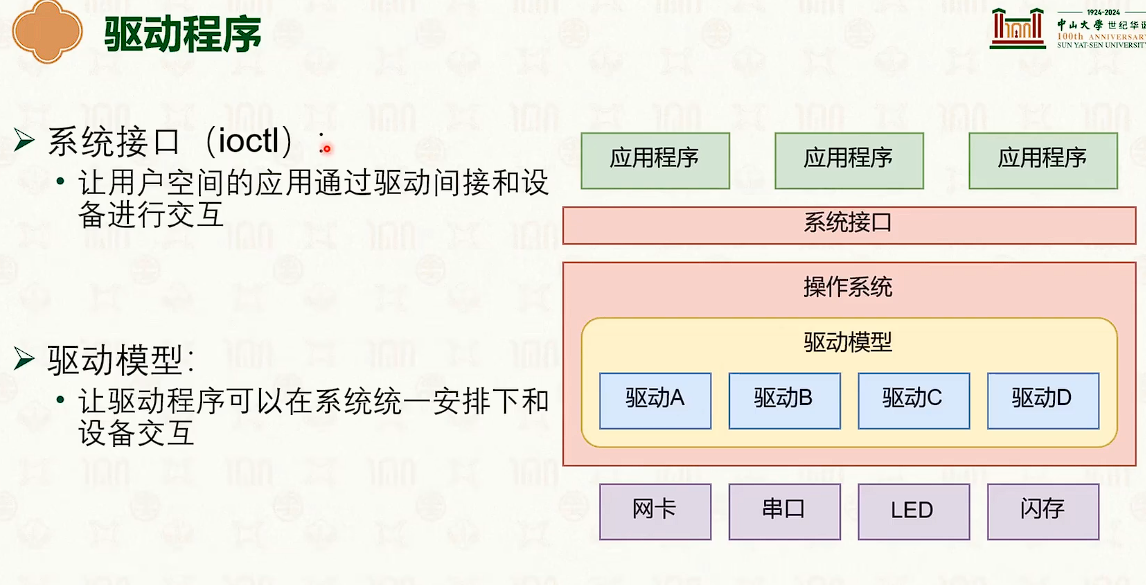
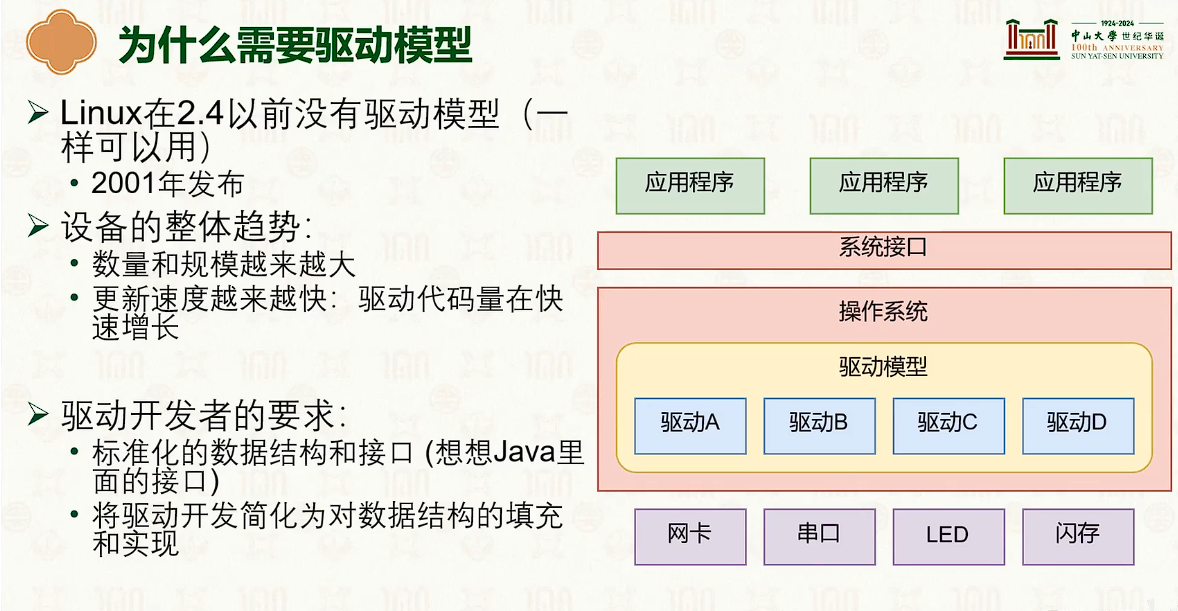
设备管理:中断响应与驱动模型

- 操作系统的交互需要中断
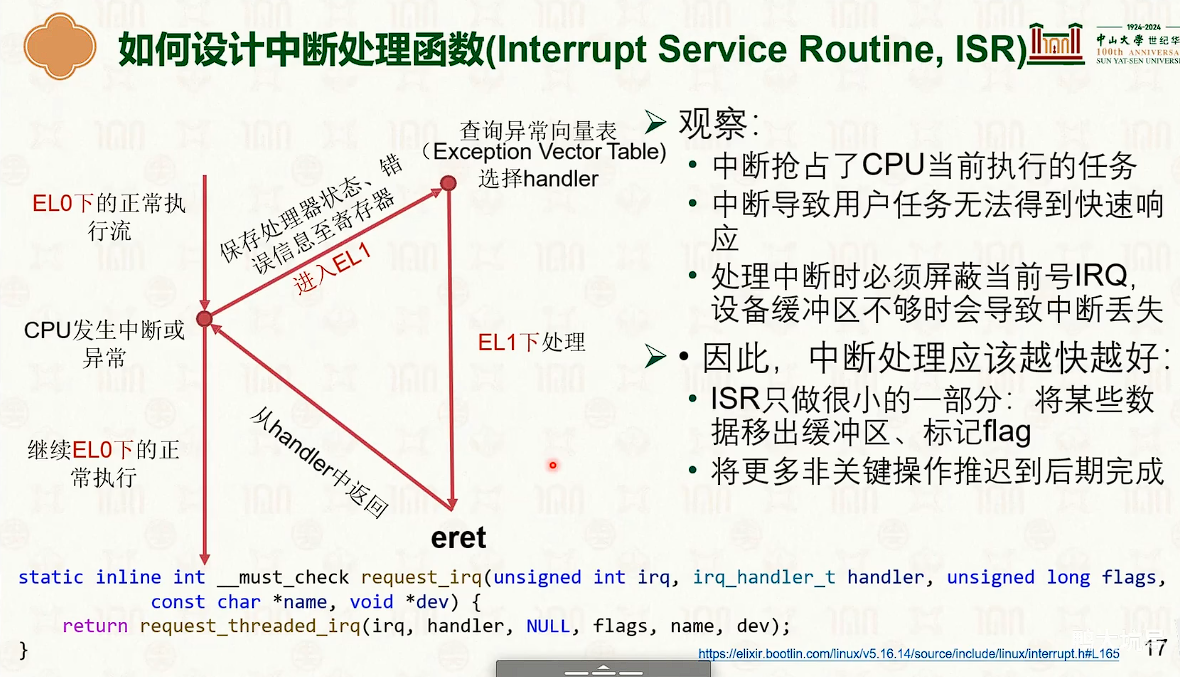
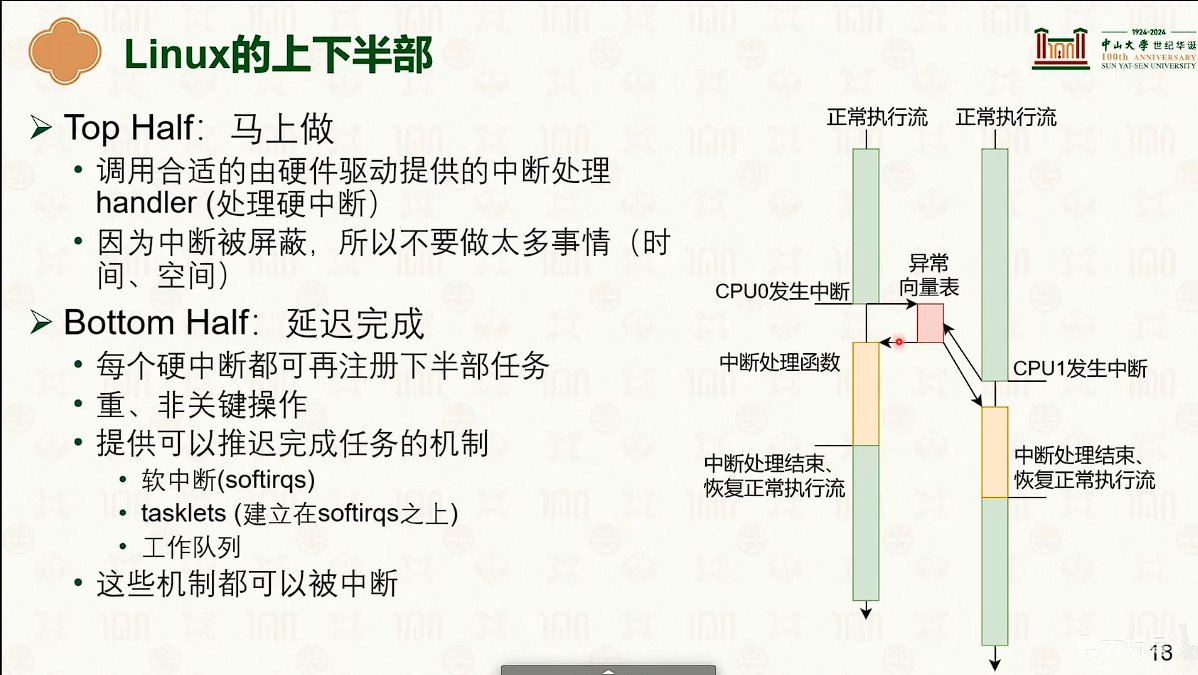
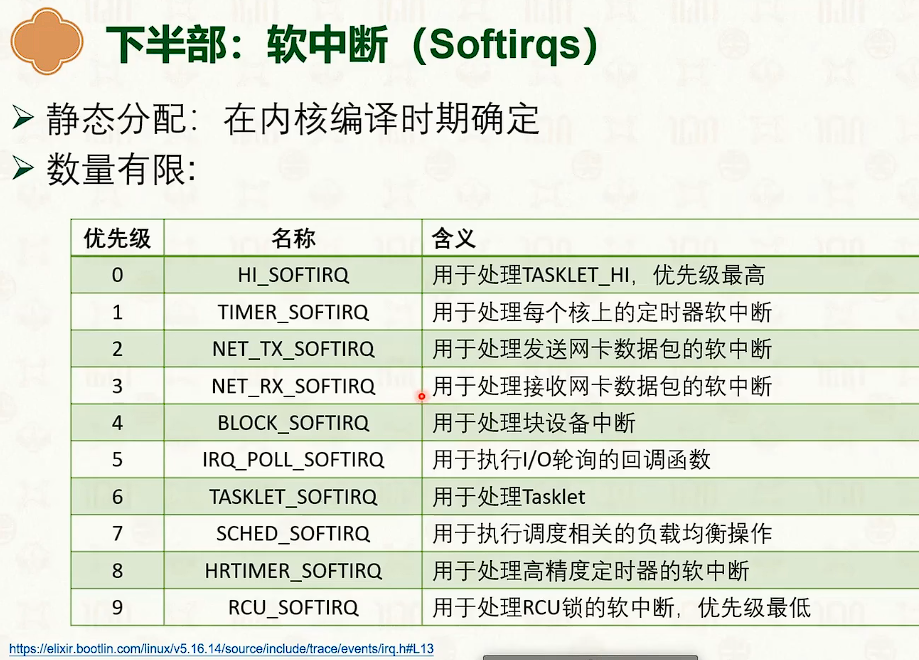
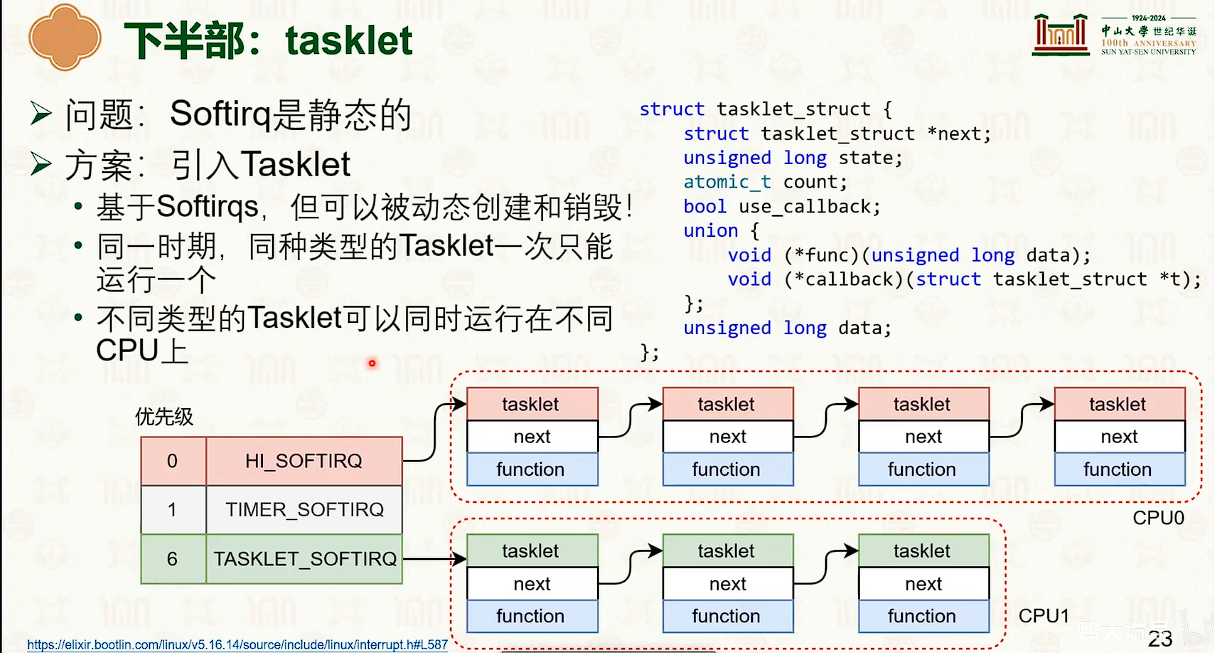
- 因为硬中断会屏蔽中断,所以必须快速执行,可以把任务转交给软中断处理函数。

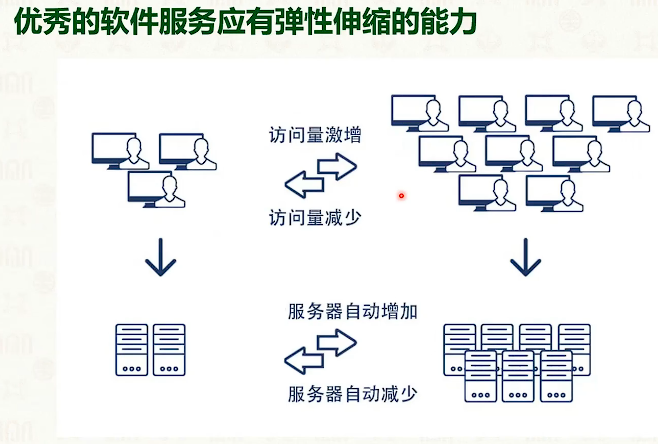
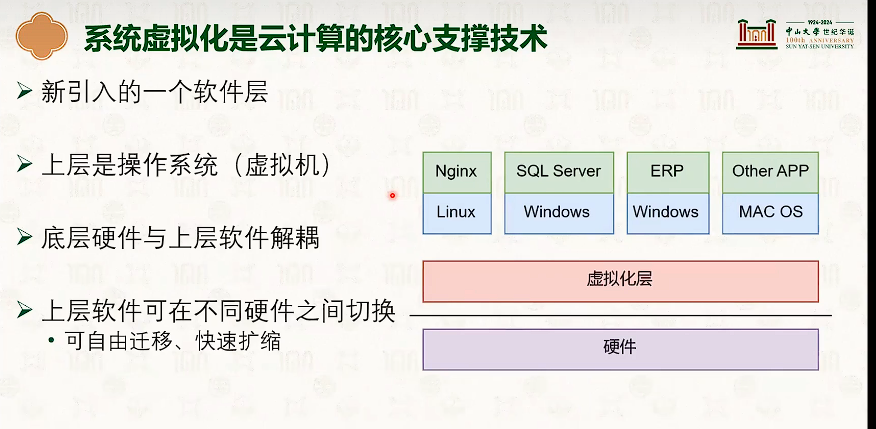
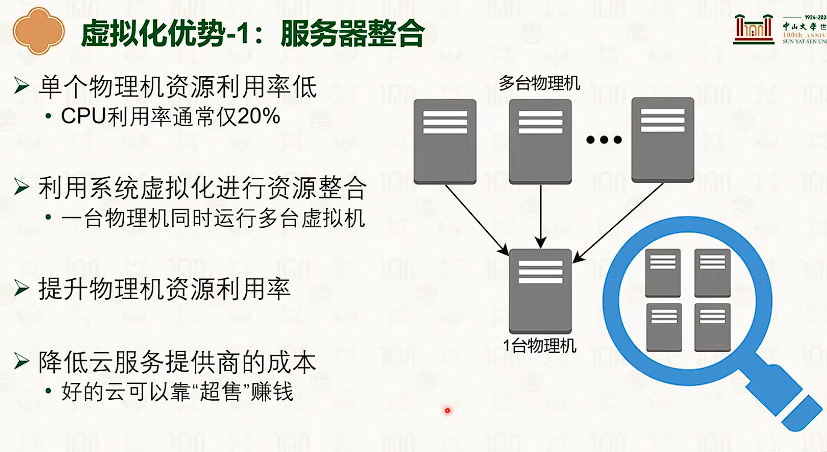
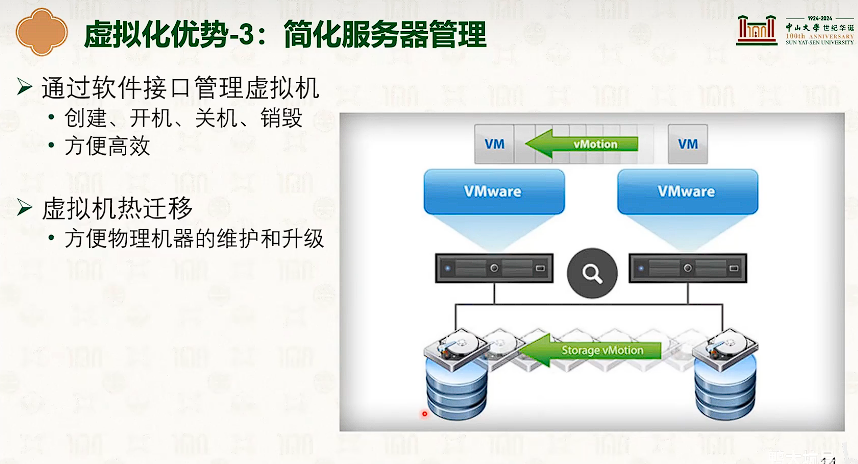
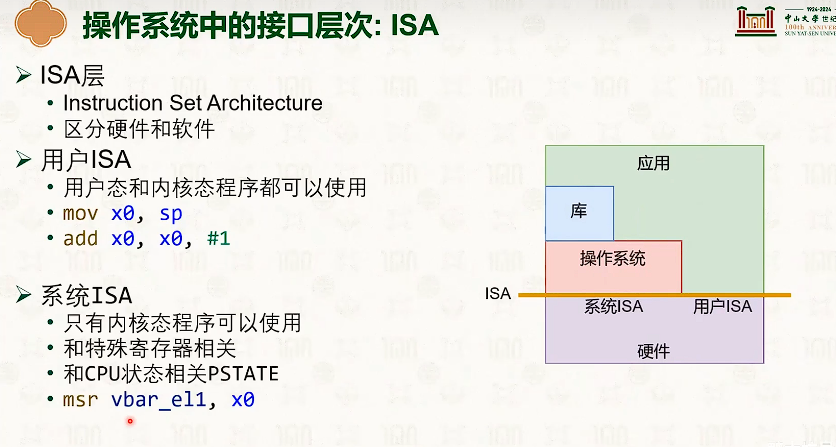
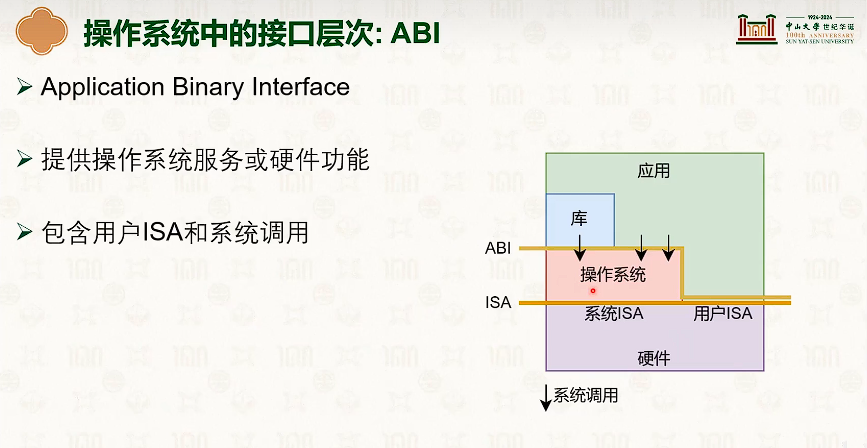
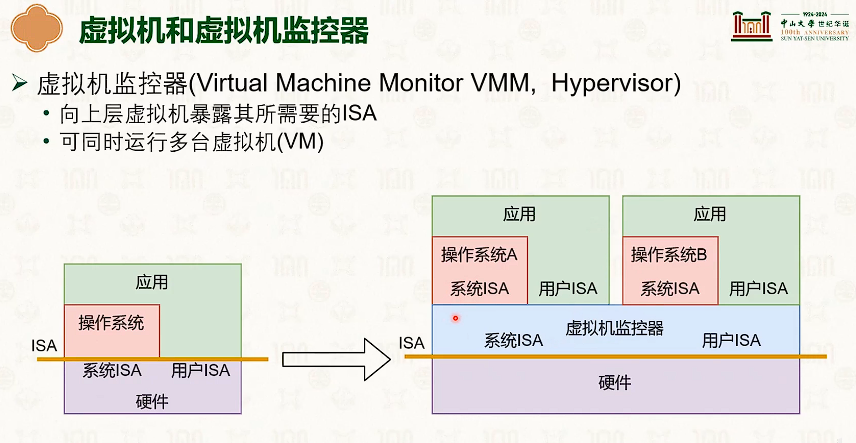
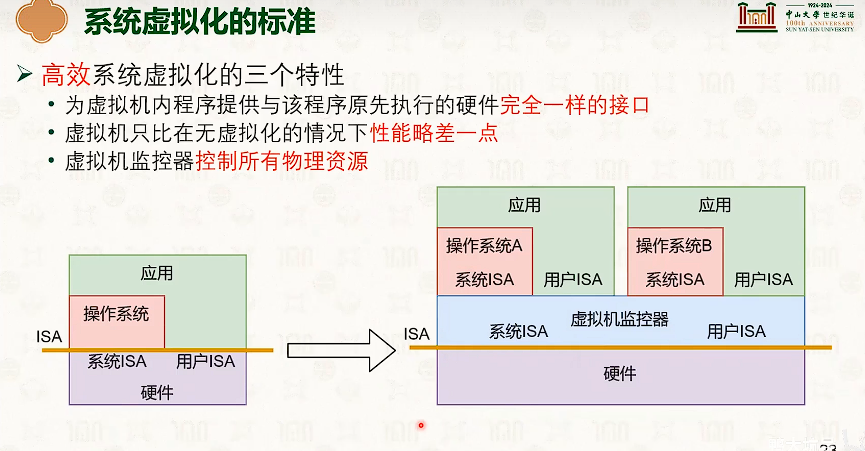
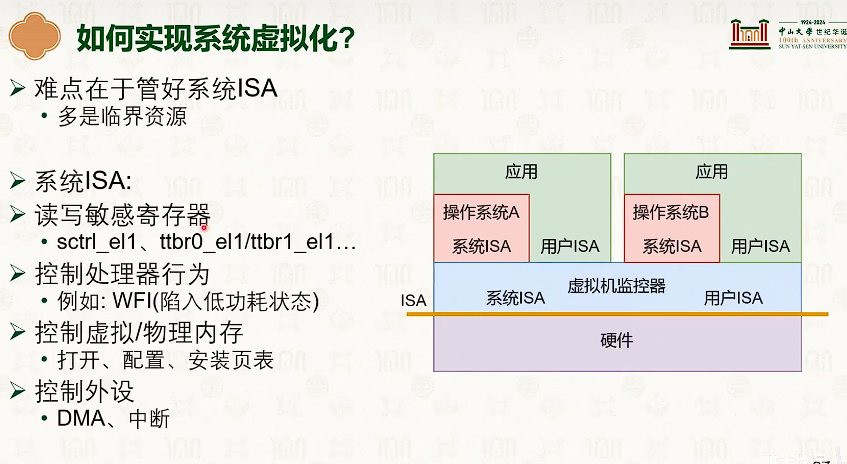
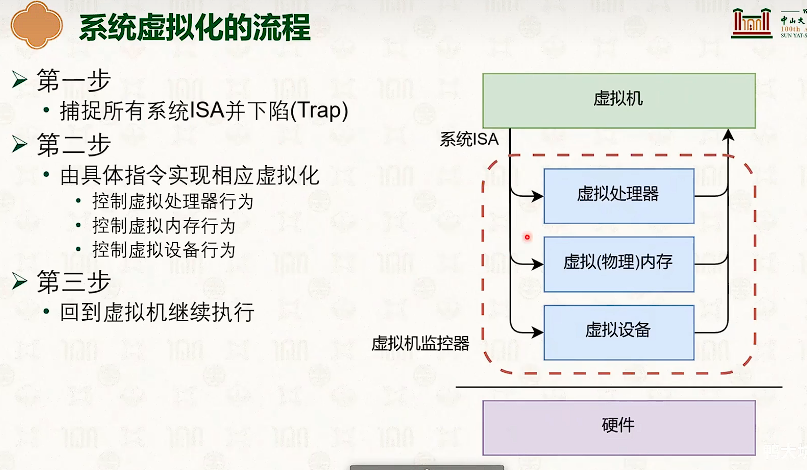
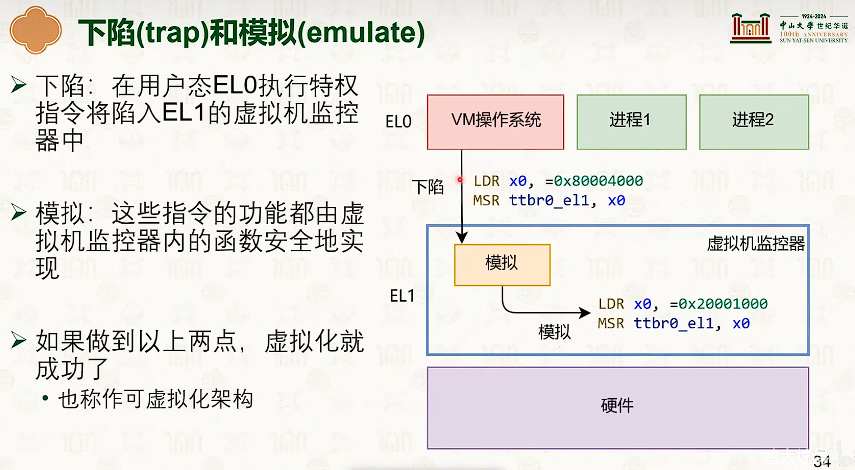
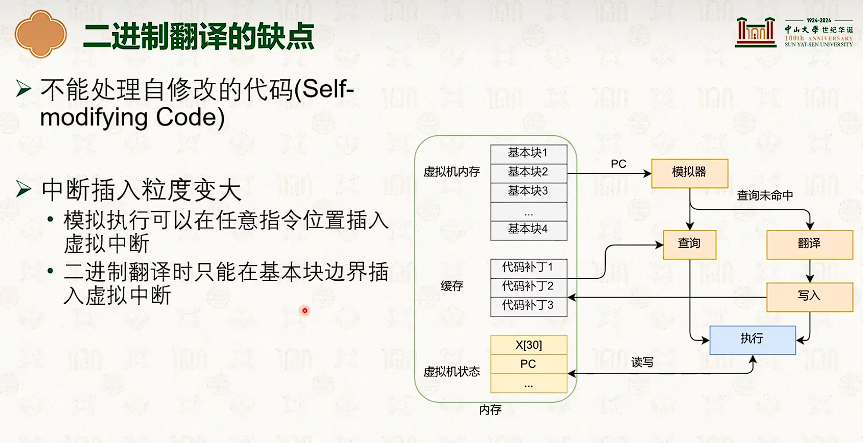
系统虚拟化:CPU虚拟化











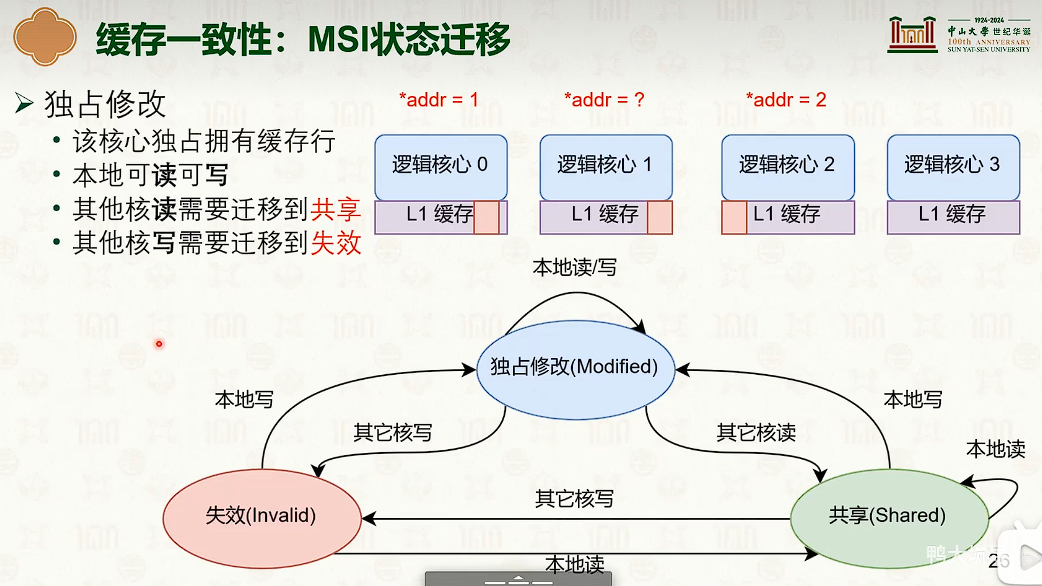
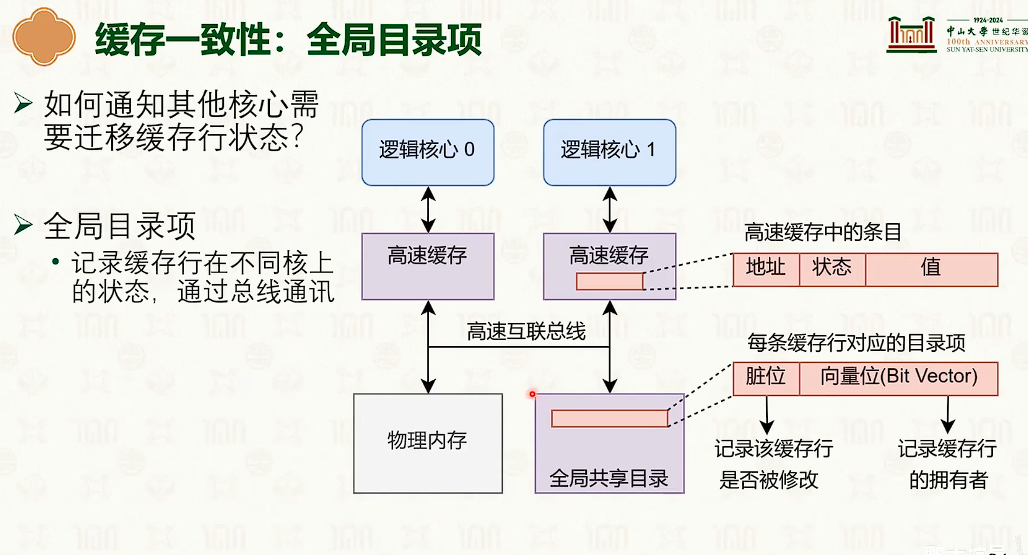
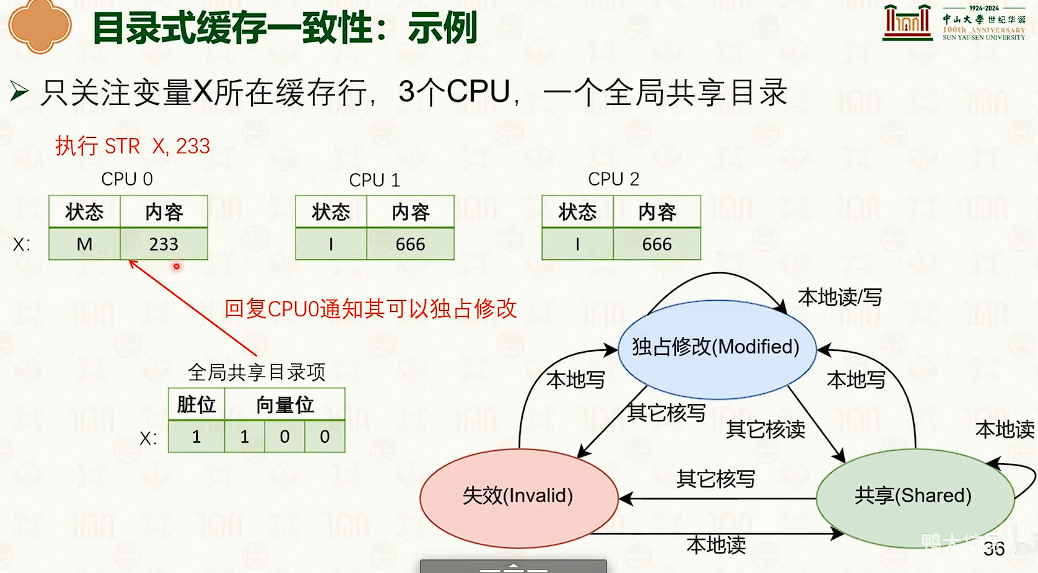
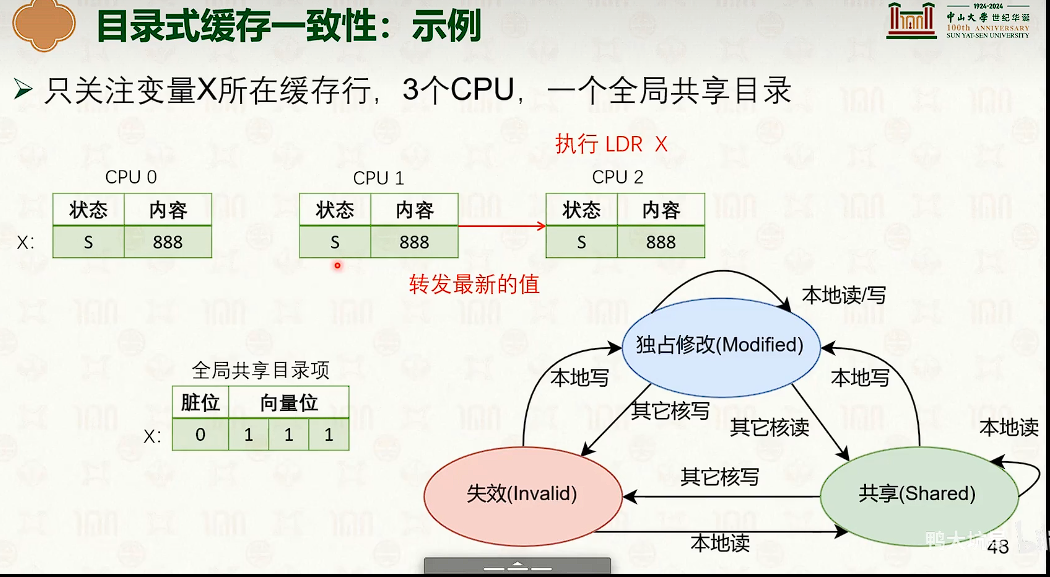
多核处理器:缓存一致性与内存一致性


- 右边快得多。写操作导致每个CPU核的缓冲是不一样的,如果用char[64]分割开,那么在不同的缓冲行中,不会导致缓冲不一致,会很快。
- 这是多核CPU中的缓冲不一致导致的。
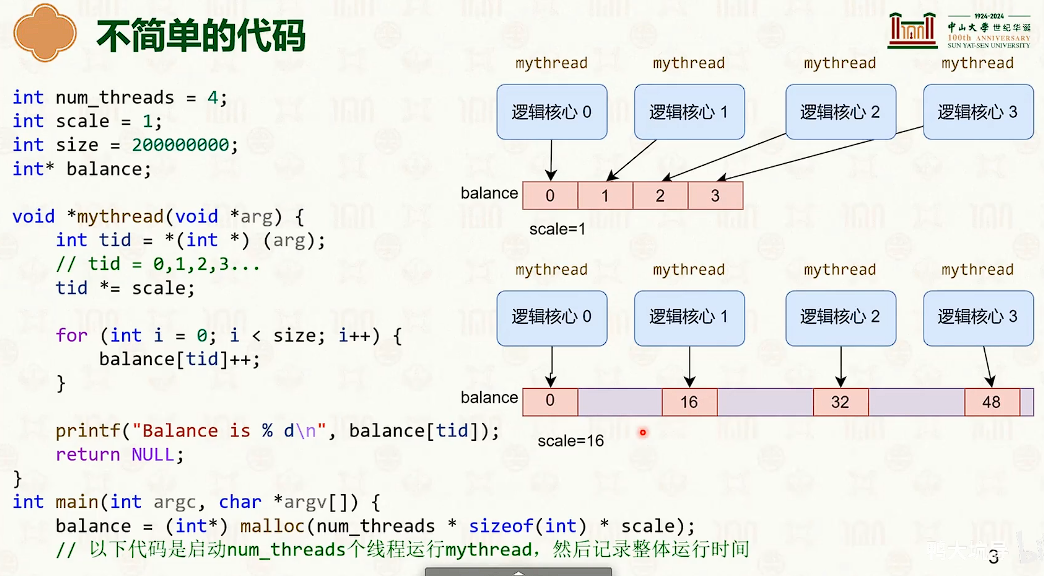
多核并发技巧:增加字段之间的字节填充,防止缓冲行伪共享。

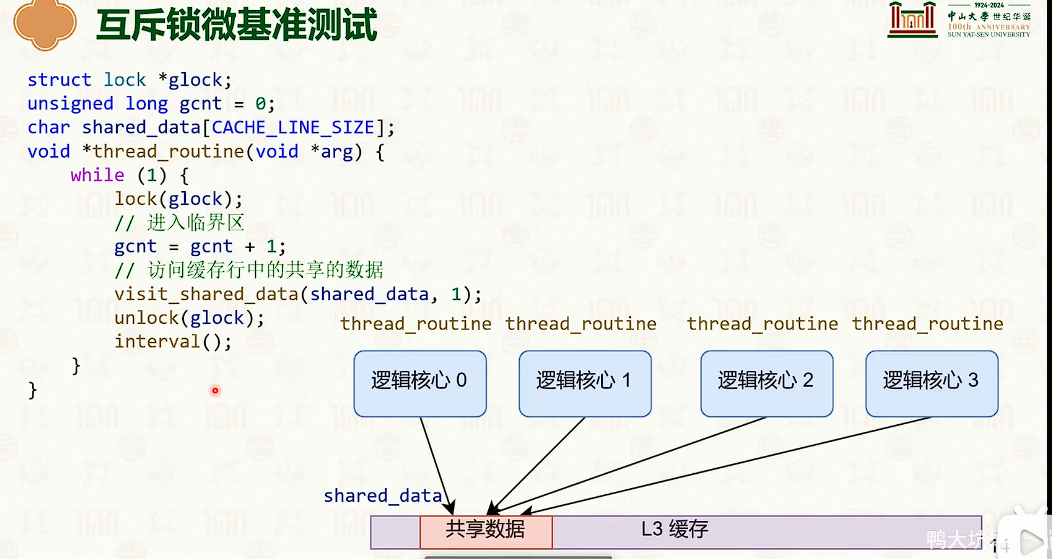
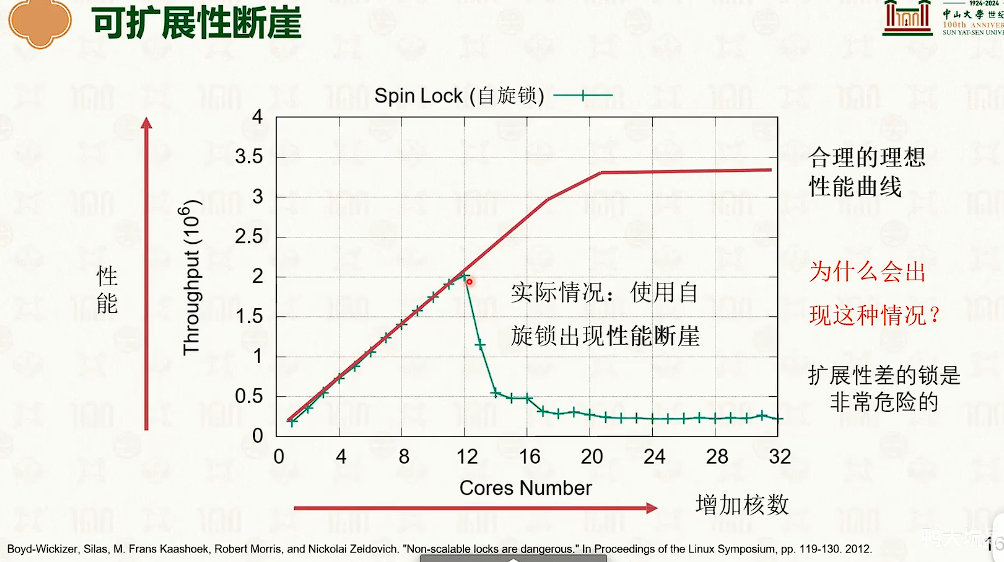
在临界区中缓冲不一致导致的缓冲失效,导致性能断崖。
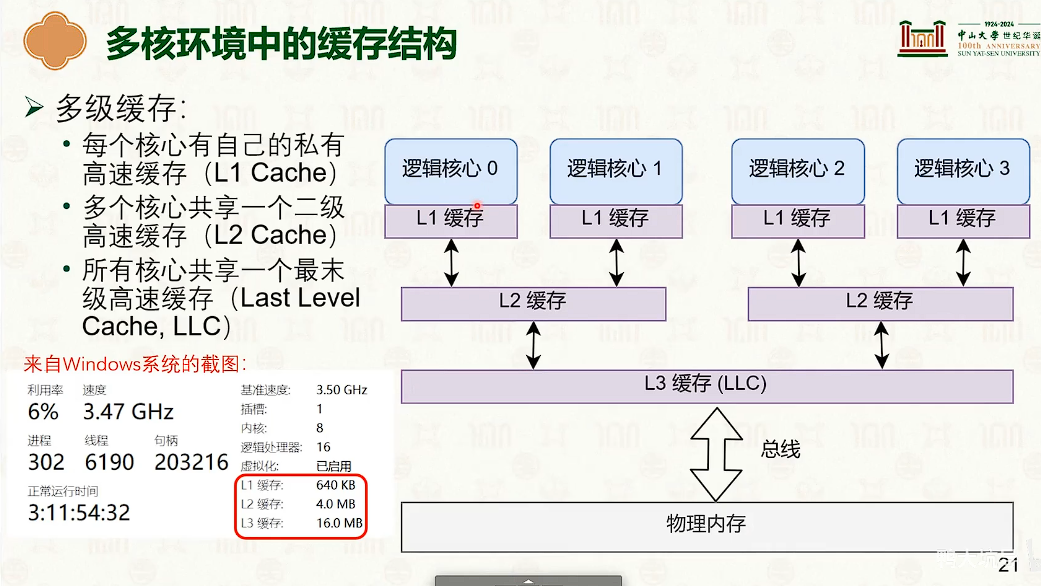
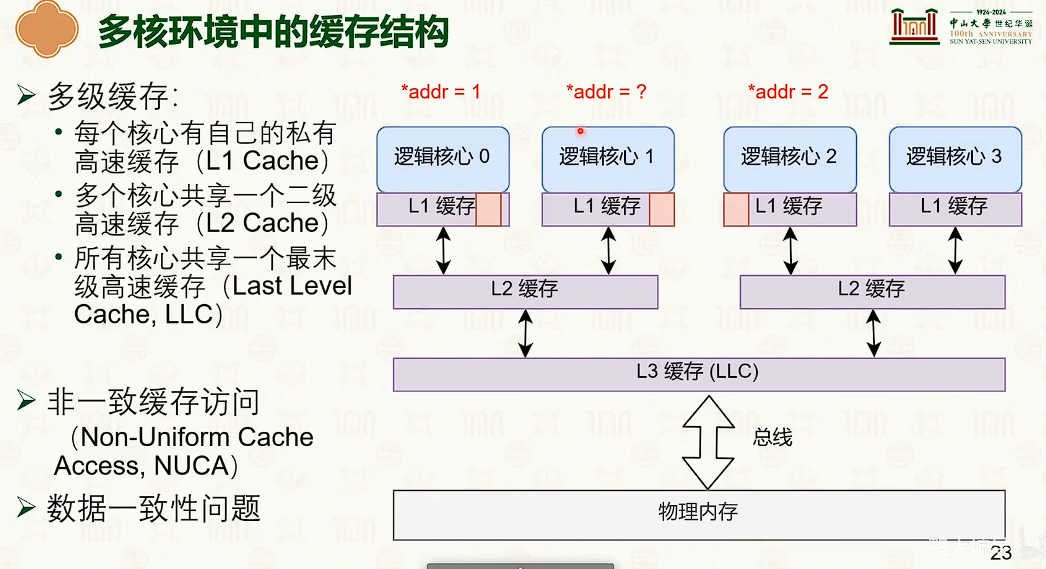
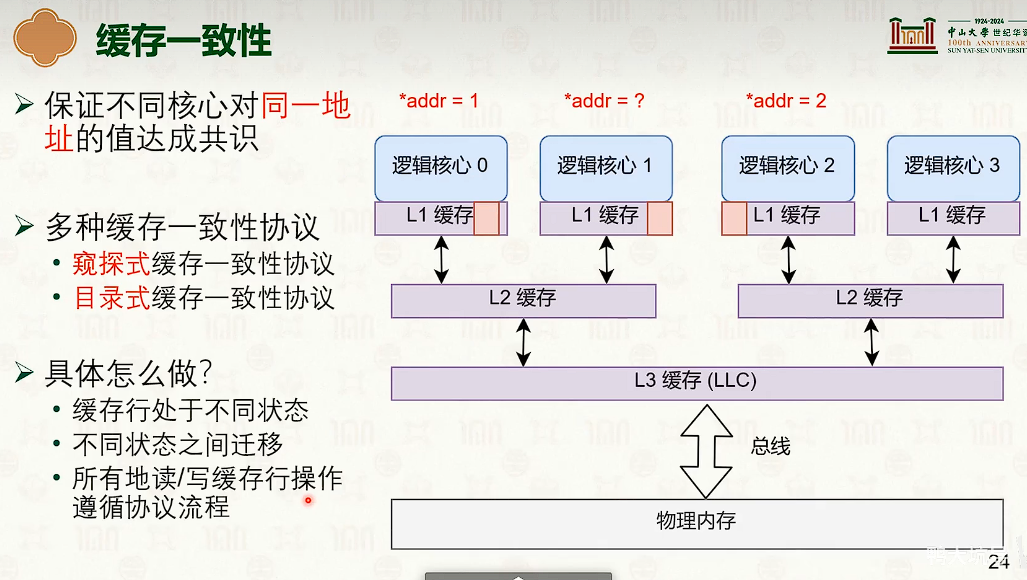
多核性能低下的原因
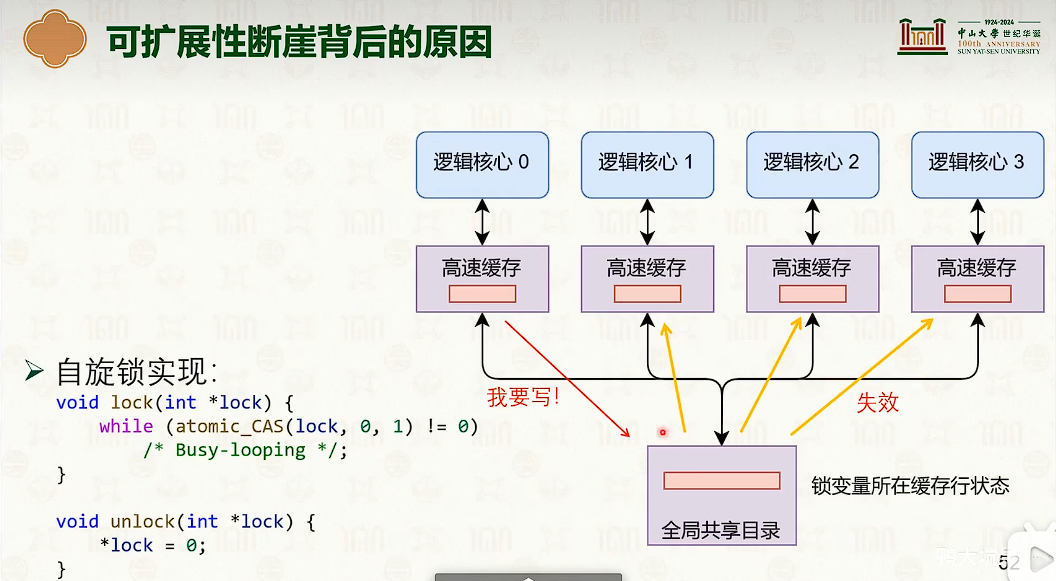
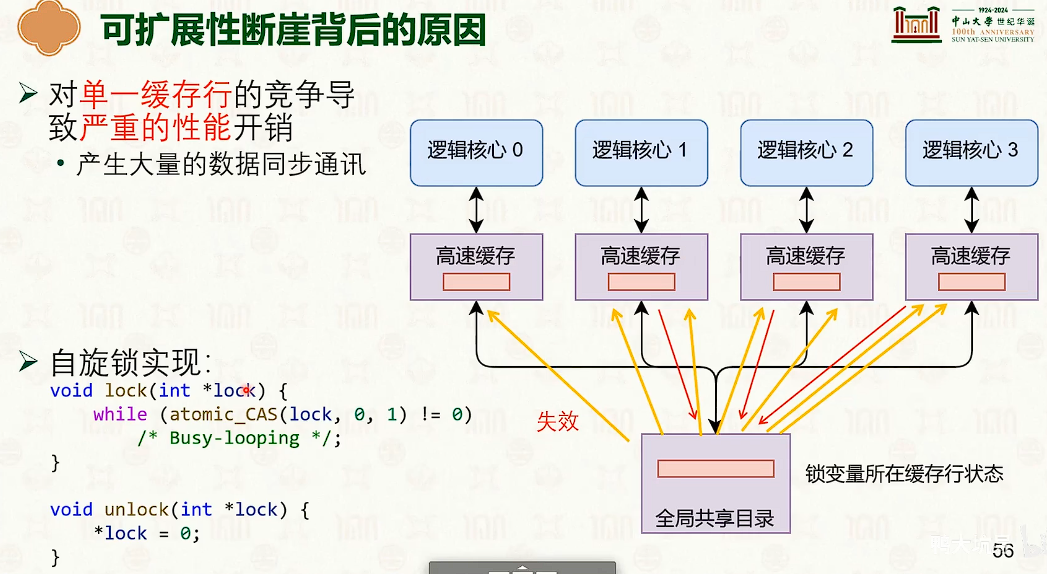
back-off等待避免单一缓冲行竞争。
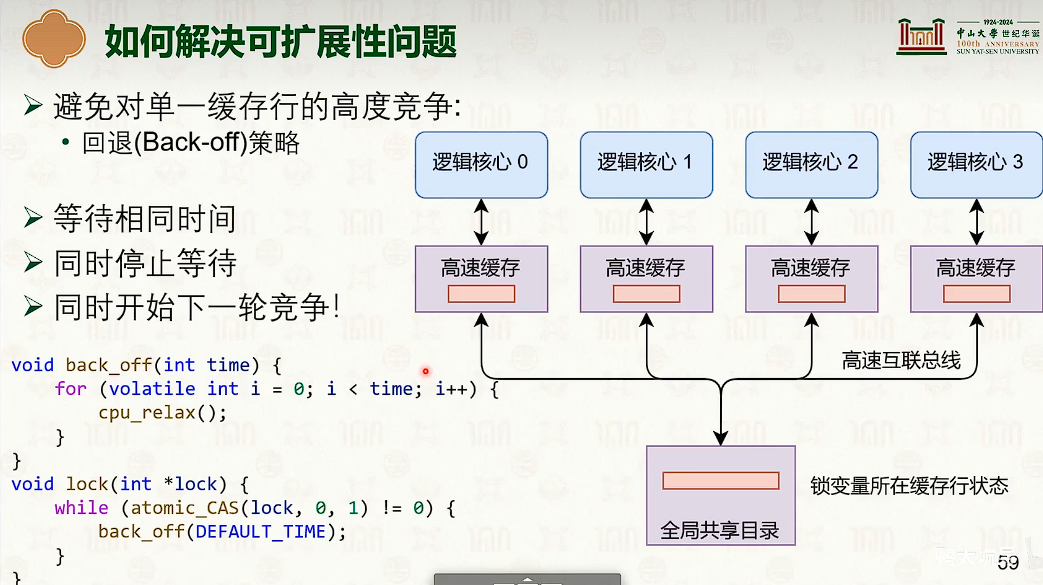
但是可能同时等待,。
解决方法:随机时间、指数回退。
但是仍然存在竞争,只是减轻了冲突的程度。
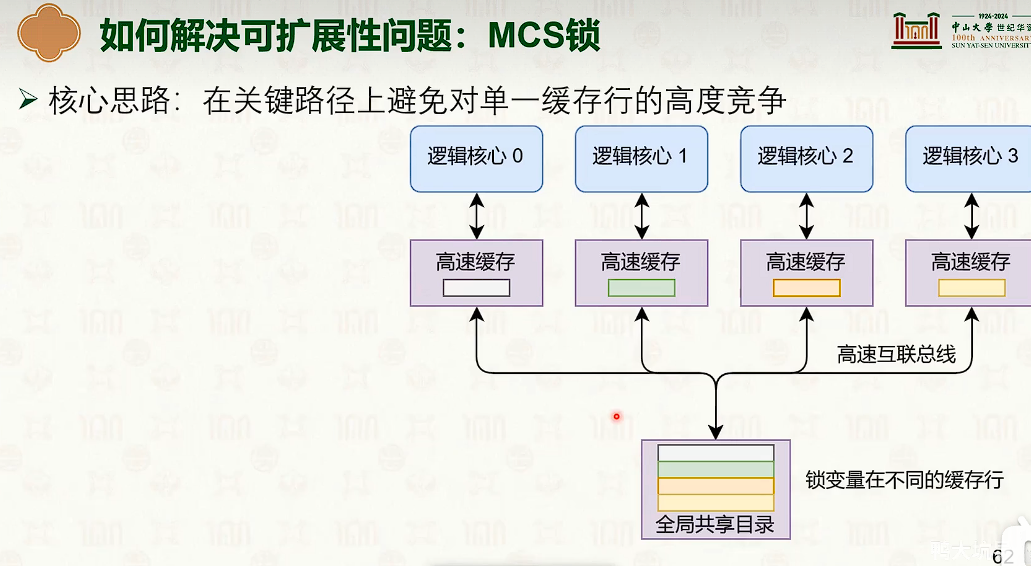
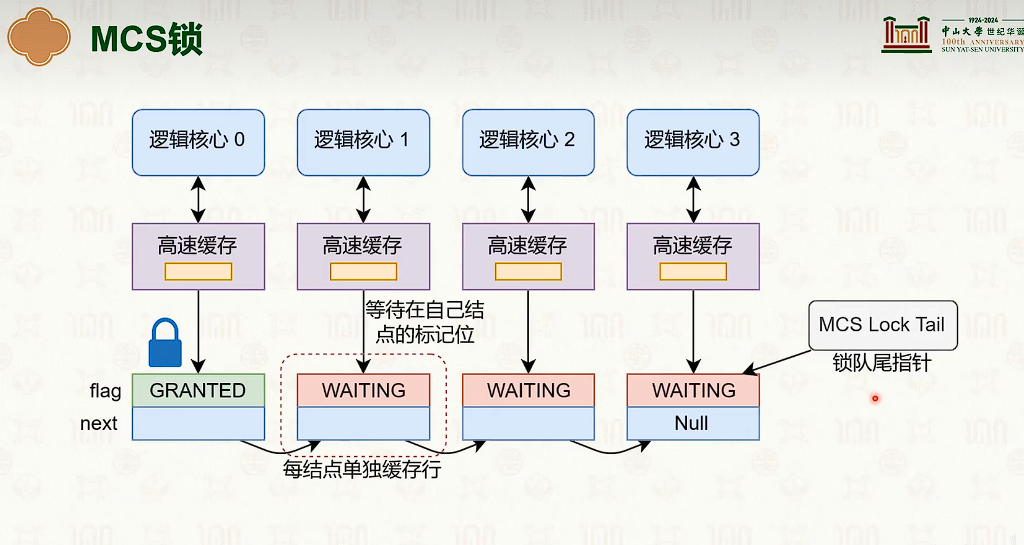
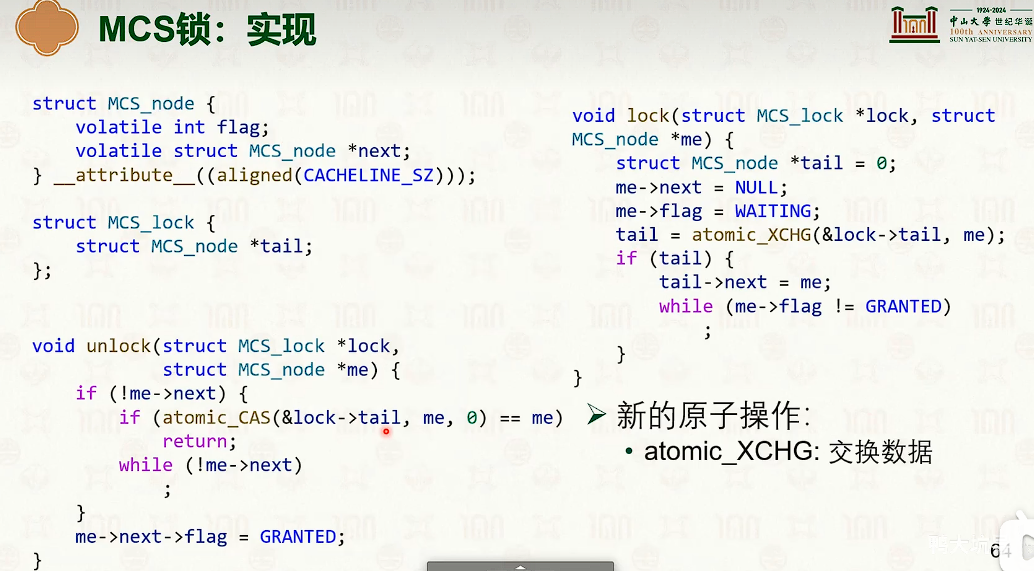
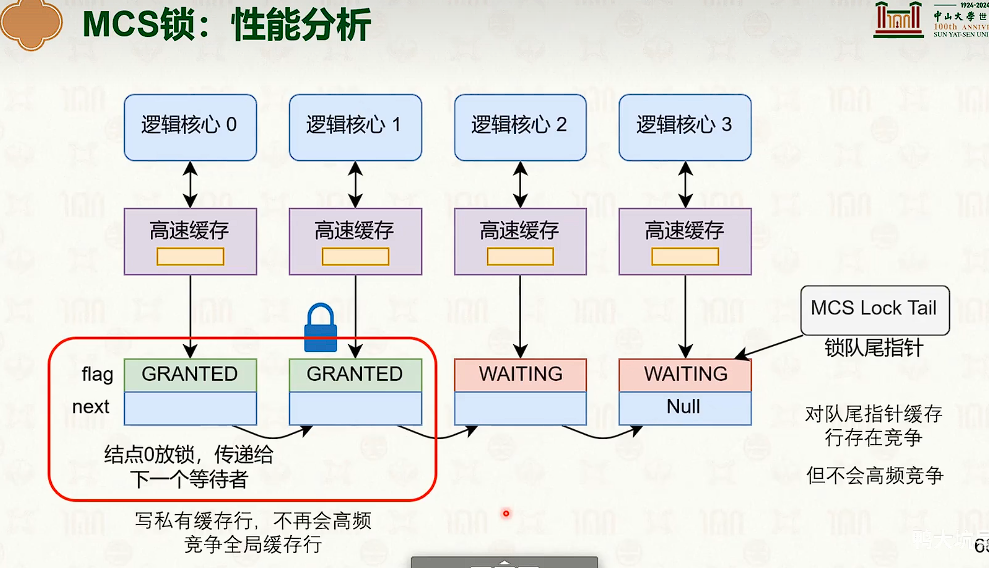

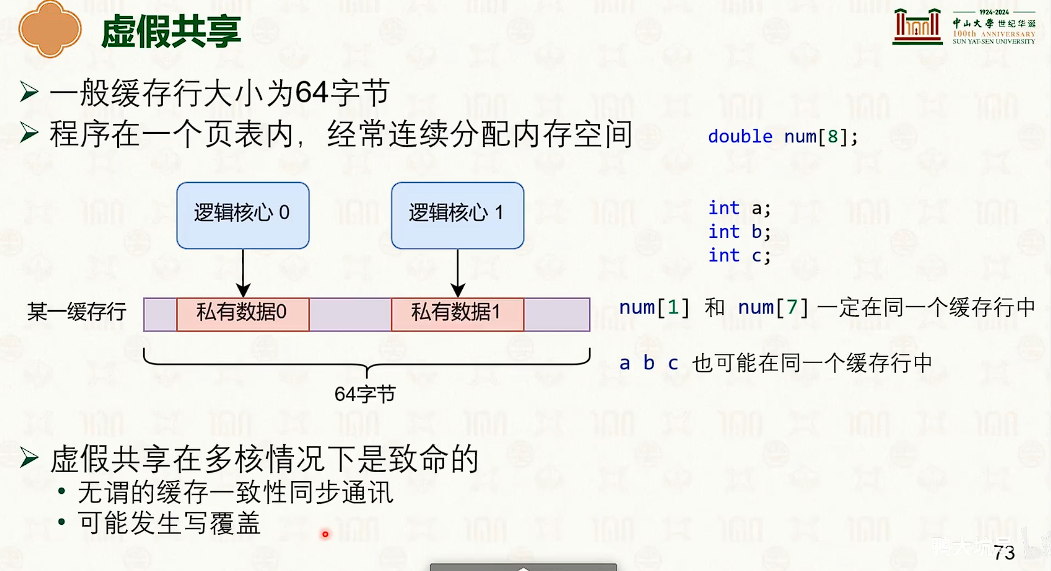


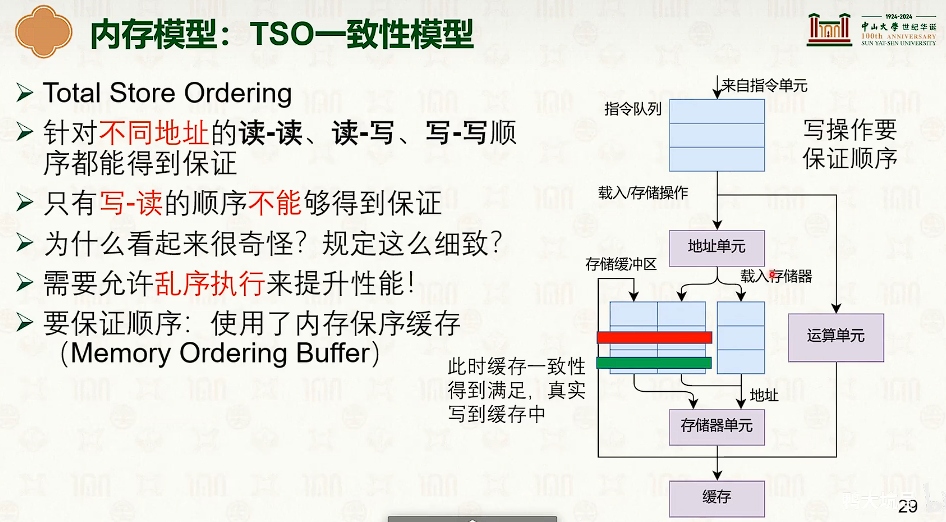

- 弱序一致性,可能需要编译器来保证。



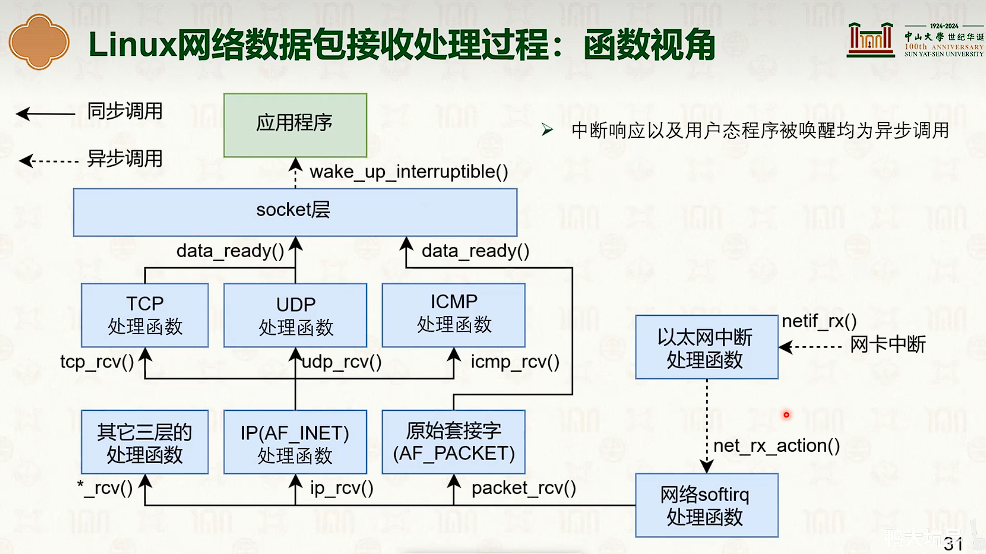
网络协议栈与系统实现:Linux

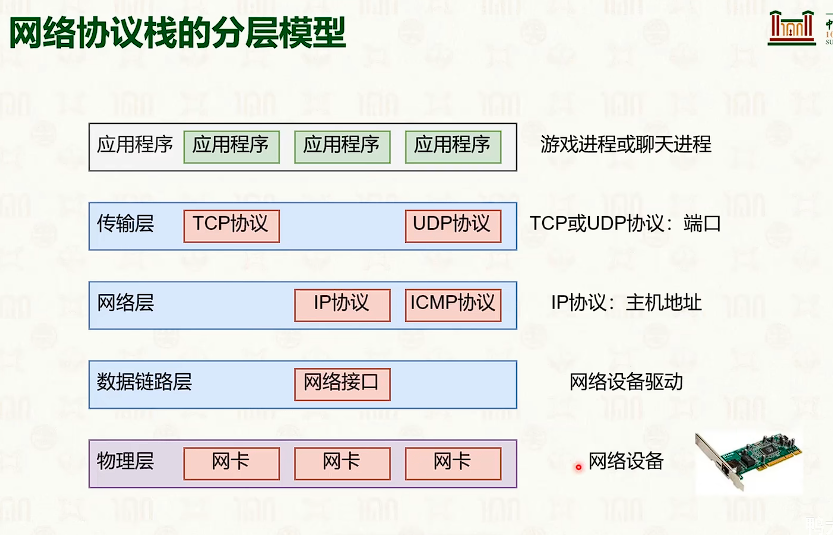
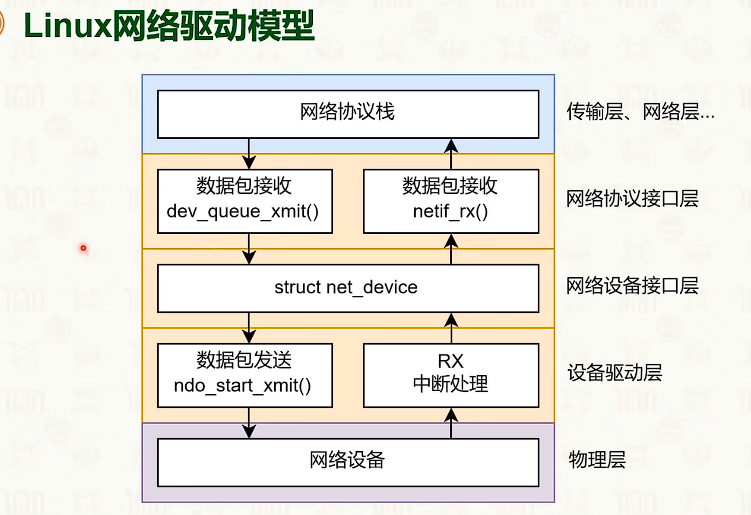
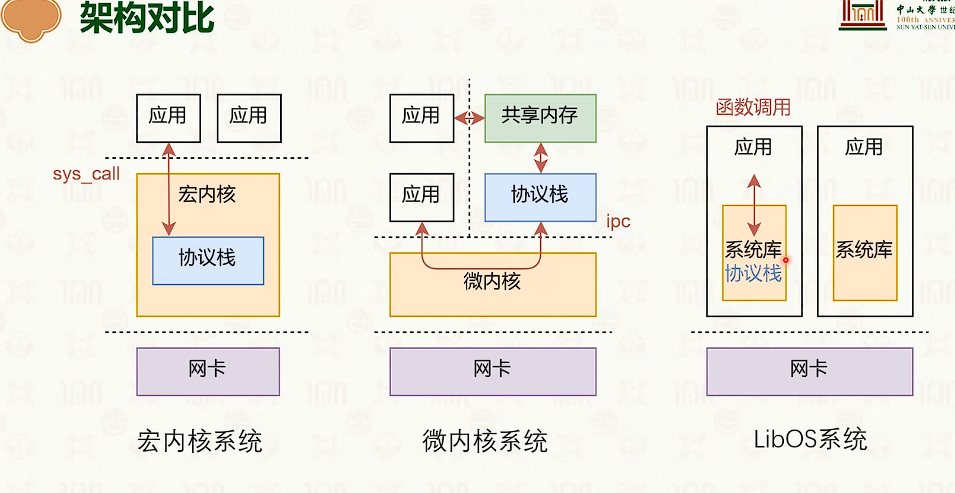

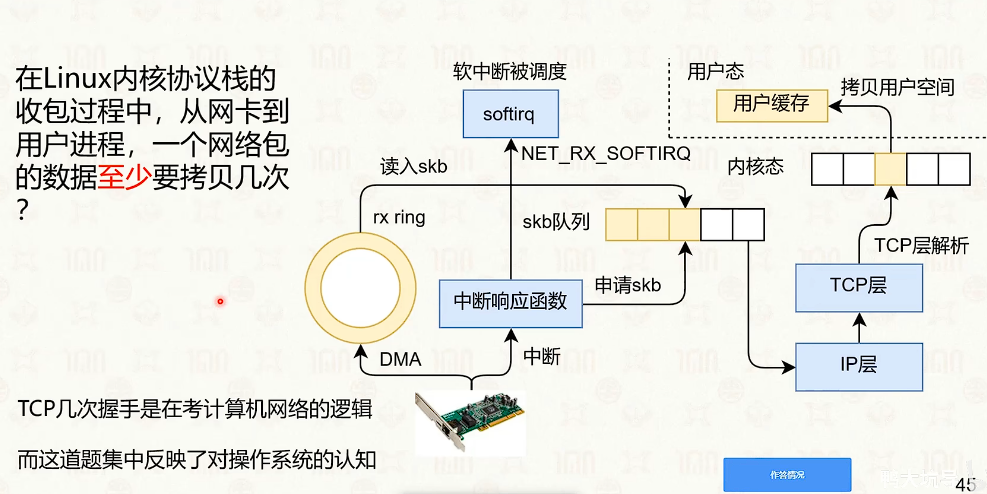
- sk_buff 里面都是指针,指向环形缓冲池,不会进行copy。
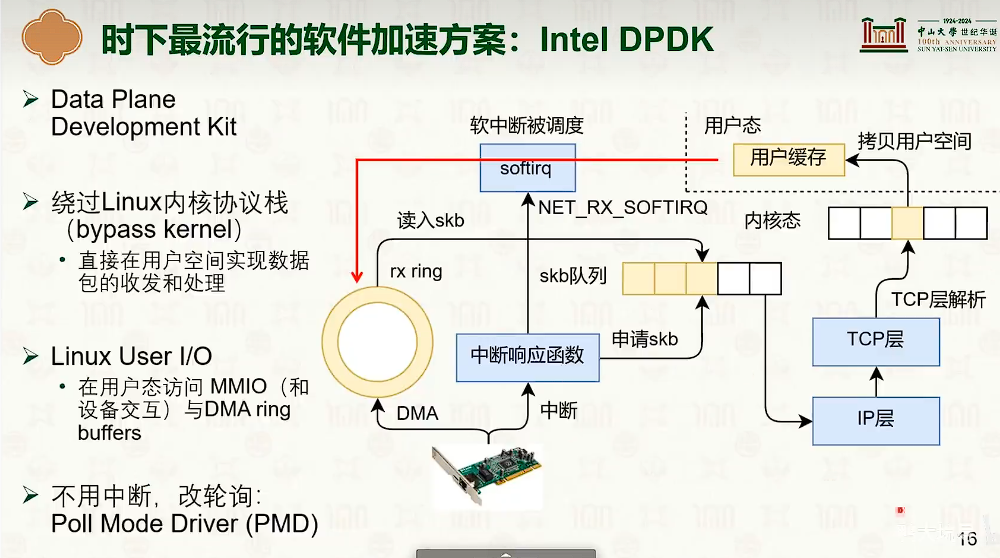
网络协议栈与系统实现:Intel DPDK





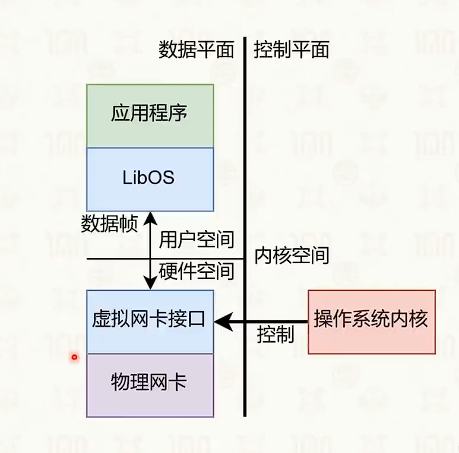
Intel DPDK软件优化方案
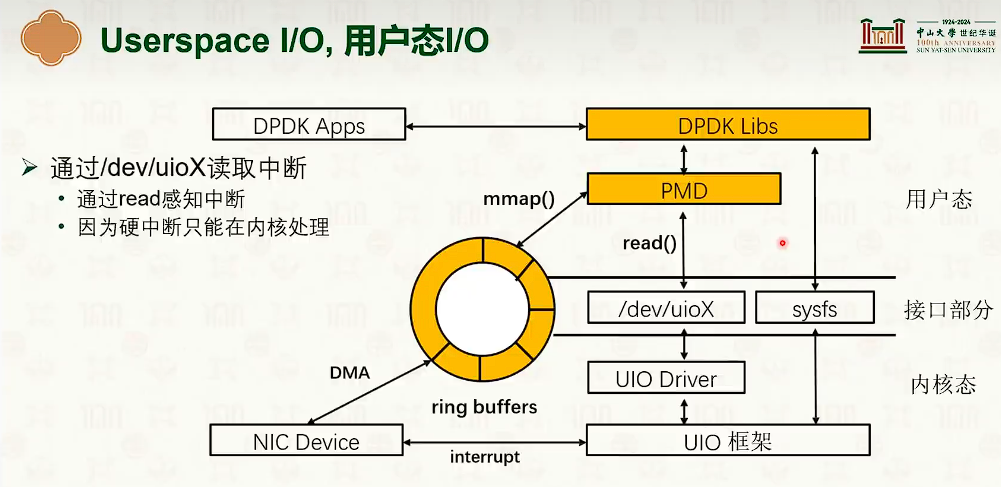



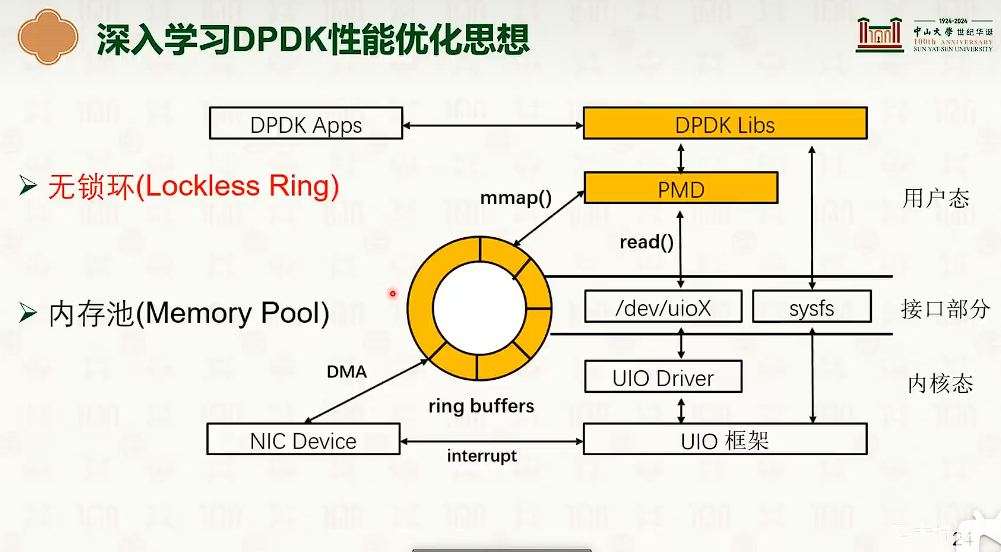
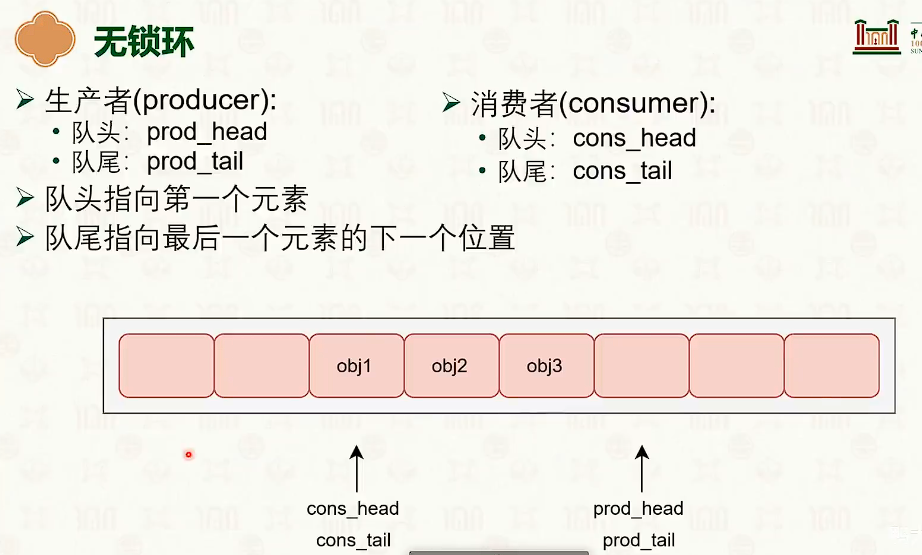
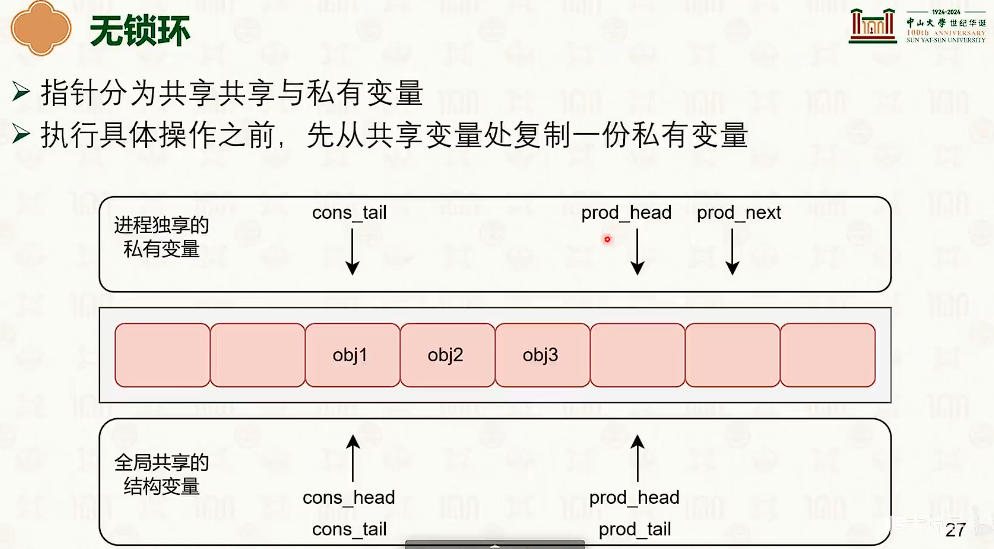
无锁环

- 特殊点是为了实现特性。
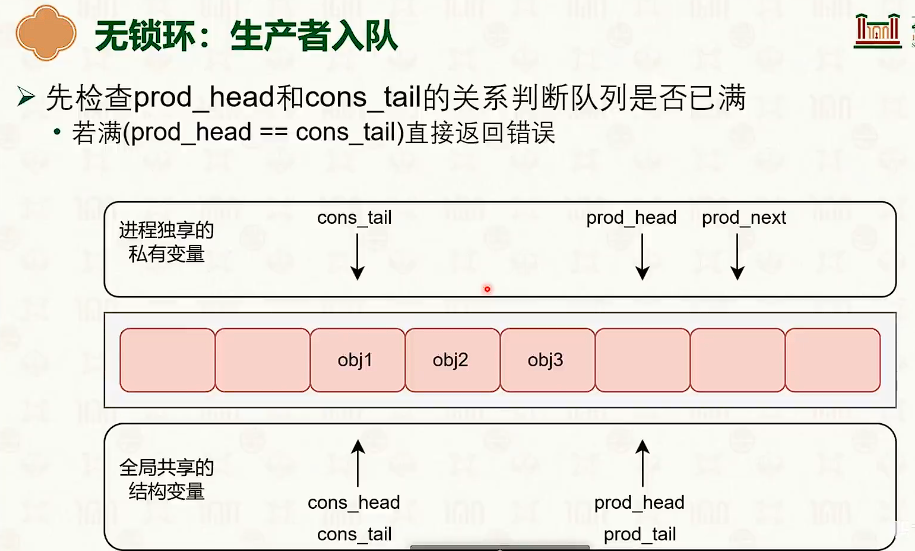

内存池


